 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Visual and Semantic Feature Spaces with Diffusion Models for Enhanced Cross-Modal Alignment
Jul 26, 2024Image classification models often demonstrate unstable performance in real-world applications due to variations in image information, driven by differing visual perspectives of subject objects and lighting discrepancies. To mitigate these challenges, existing studies commonly incorporate additional modal information matching the visual data to regularize the model's learning process, enabling the extraction of high-quality visual features from complex image regions. Specifically, in the realm of multimodal learning, cross-modal alignment is recognized as an effective strategy, harmonizing different modal information by learning a domain-consistent latent feature space for visual and semantic features. However, this approach may face limitations due to the heterogeneity between multimodal information, such as differences in feature distribution and structure. To address this issue, we introduce a Multimodal Alignment and Reconstruction Network (MARNet), designed to enhance the model's resistance to visual noise. Importantly, MARNet includes a cross-modal diffusion reconstruction module for smoothly and stably blending information across different domains. Experiments conducted on two benchmark datasets, Vireo-Food172 and Ingredient-101, demonstrate that MARNet effectively improves the quality of image information extracted by the model. It is a plug-and-play framework that can be rapidly integrated into various image classification frameworks, boosting model performance.
Class-level Structural Relation Modelling and Smoothing for Visual Representation Learning
Aug 08, 2023



Representation learning for images has been advanced by recent progress in more complex neural models such as the Vision Transformers and new learning theories such as the structural causal models. However, these models mainly rely on the classification loss to implicitly regularize the class-level data distributions, and they may face difficulties when handling classes with diverse visual patterns. We argue that the incorporation of the structural information between data samples may improve this situation. To achieve this goal, this paper presents a framework termed \textbf{C}lass-level Structural Relation Modeling and Smoothing for Visual Representation Learning (CSRMS), which includes the Class-level Relation Modelling, Class-aware Graph Sampling, and Relational Graph-Guided Representation Learning modules to model a relational graph of the entire dataset and perform class-aware smoothing and regularization operations to alleviate the issue of intra-class visual diversity and inter-class similarity. Specifically, the Class-level Relation Modelling module uses a clustering algorithm to learn the data distributions in the feature space and identify three types of class-level sample relations for the training set; Class-aware Graph Sampling module extends typical training batch construction process with three strategies to sample dataset-level sub-graphs; and Relational Graph-Guided Representation Learning module employs a graph convolution network with knowledge-guided smoothing operations to ease the projection from different visual patterns to the same class. Experiments demonstrate the effectiveness of structured knowledge modelling for enhanced representation learning and show that CSRMS can be incorporated with any state-of-the-art visual representation learning models for performance gains. The source codes and demos have been released at https://github.com/czt117/CSRMS.
Cross-Modal Content Inference and Feature Enrichment for Cold-Start Recommendation
Jul 06, 2023Multimedia recommendation aims to fuse the multi-modal information of items for feature enrichment to improve the recommendation performance. However, existing methods typically introduce multi-modal information based on collaborative information to improve the overall recommendation precision, while failing to explore its cold-start recommendation performance. Meanwhile, these above methods are only applicable when such multi-modal data is available. To address this problem, this paper proposes a recommendation framework, named Cross-modal Content Inference and Feature Enrichment Recommendation (CIERec), which exploits the multi-modal information to improve its cold-start recommendation performance. Specifically, CIERec first introduces image annotation as the privileged information to help guide the mapping of unified features from the visual space to the semantic space in the training phase. And then CIERec enriches the content representation with the fusion of collaborative, visual, and cross-modal inferred representations, so as to improve its cold-start recommendation performance. Experimental results on two real-world datasets show that the content representations learned by CIERec are able to achieve superior cold-start recommendation performance over existing visually-aware recommendation algorithms. More importantly, CIERec can consistently achieve significant improvements with different conventional visually-aware backbones, which verifies its universality and effectiveness.
Meta-Causal Feature Learning for Out-of-Distribution Generalization
Aug 22, 2022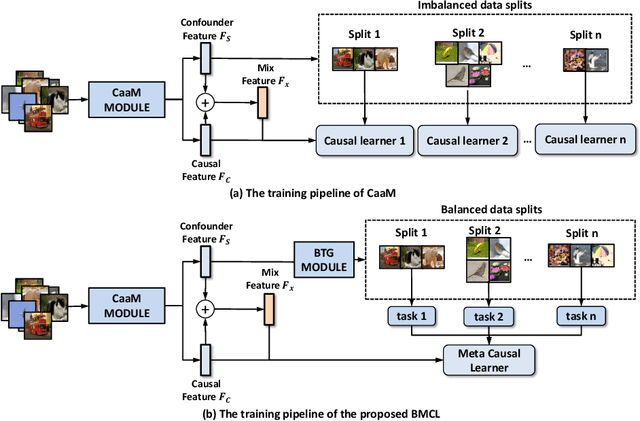
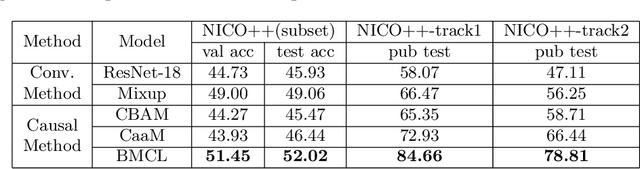
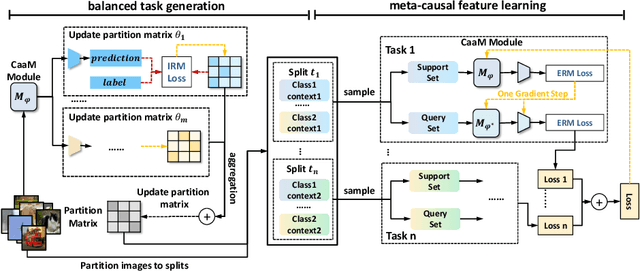
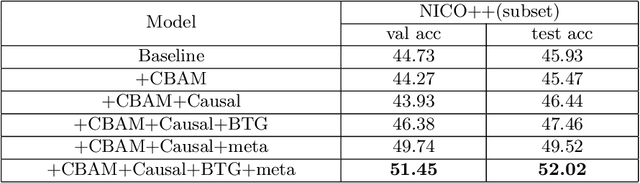
Causal inference has become a powerful tool to handle the out-of-distribution (OOD) generalization problem, which aims to extract the invariant features. However, conventional methods apply causal learners from multiple data splits, which may incur biased representation learning from imbalanced data distributions and difficulty in invariant feature learning from heterogeneous sources. To address these issues, this paper presents a balanced meta-causal learner (BMCL), which includes a balanced task generation module (BTG) and a meta-causal feature learning module (MCFL). Specifically, the BTG module learns to generate balanced subsets by a self-learned partitioning algorithm with constraints on the proportions of sample classes and contexts. The MCFL module trains a meta-learner adapted to different distributions. Experiments conducted on NICO++ dataset verified that BMCL effectively identifies the class-invariant visual regions for classification and may serve as a general framework to improve the performance of the state-of-the-art methods.