 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DSwapping: Texture Swapping For 3D Object From Single Reference Image
Mar 24, 20253D texture swapping allows for the customization of 3D object textures, enabling efficient and versatile visual transformations in 3D editing. While no dedicated method exists, adapted 2D editing and text-driven 3D editing approaches can serve this purpose. However, 2D editing requires frame-by-frame manipulation, causing inconsistencies across views, while text-driven 3D editing struggles to preserve texture characteristics from reference images. To tackle these challenges, we introduce 3DSwapping, a 3D texture swapping method that integrates: 1) progressive generation, 2) view-consistency gradient guidance, and 3) prompt-tuned gradient guidance. To ensure view consistency, our progressive generation process starts by editing a single reference image and gradually propagates the edits to adjacent views. Our view-consistency gradient guidance further reinforces consistency by conditioning the generation model on feature differences between consistent and inconsistent outputs. To preserve texture characteristics, we introduce prompt-tuning-based gradient guidance, which learns a token that precisely captures the difference between the reference image and the 3D object. This token then guides the editing process, ensuring more consistent texture preservation across views. Overall, 3DSwapping integrates these novel strategies to achieve higher-fidelity texture transfer while preserving structural coherence across multiple viewpoints. Extensive qualitative and quantitative evaluations confirm that our three novel components enable convincing and effective 2D texture swapping for 3D objects. Code will be available upon acceptance.
SSNeRF: Sparse View Semi-supervised Neural Radiance Fields with Augmentation
Aug 17, 2024



Sparse view NeRF is challenging because limited input images lead to an under constrained optimization problem for volume rendering. Existing methods address this issue by relying on supplementary information, such as depth maps. However, generating this supplementary information accurately remains problematic and often leads to NeRF producing images with undesired artifacts. To address these artifacts and enhance robustness, we propose SSNeRF, a sparse view semi supervised NeRF method based on a teacher student framework. Our key idea is to challenge the NeRF module with progressively severe sparse view degradation while providing high confidence pseudo labels. This approach helps the NeRF model become aware of noise and incomplete information associated with sparse views, thus improving its robustness. The novelty of SSNeRF lies in its sparse view specific augmentations and semi supervised learning mechanism. In this approach, the teacher NeRF generates novel views along with confidence scores, while the student NeRF, perturbed by the augmented input, learns from the high confidence pseudo labels. Our sparse view degradation augmentation progressively injects noise into volume rendering weights, perturbs feature maps in vulnerable layers, and simulates sparse view blurriness. These augmentation strategies force the student NeRF to recognize degradation and produce clearer rendered views. By transferring the student's parameters to the teacher, the teacher gains increased robustness in subsequent training iterations. Extensive experiments demonstrate the effectiveness of our SSNeRF in generating novel views with less sparse view degradation. We will release code upon acceptance.
Towards Better Text-to-Image Generation Alignment via Attention Modulation
Apr 22, 2024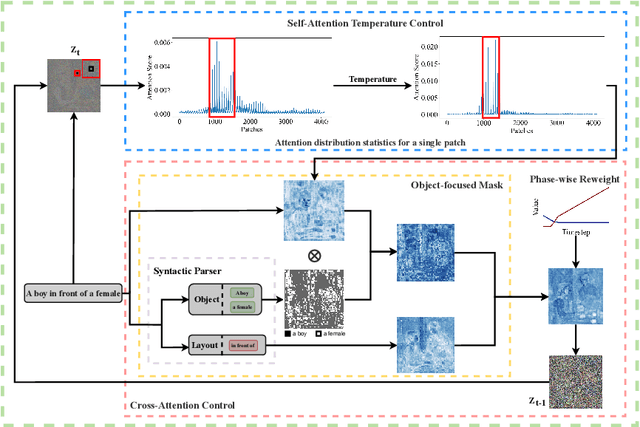
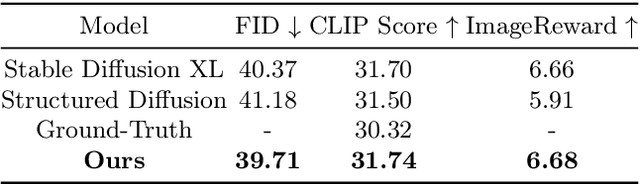

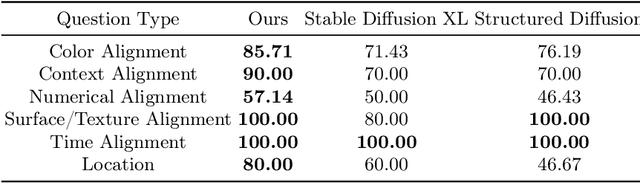
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
Class-level Structural Relation Modelling and Smoothing for Visual Representation Learning
Aug 08, 2023



Representation learning for images has been advanced by recent progress in more complex neural models such as the Vision Transformers and new learning theories such as the structural causal models. However, these models mainly rely on the classification loss to implicitly regularize the class-level data distributions, and they may face difficulties when handling classes with diverse visual patterns. We argue that the incorporation of the structural information between data samples may improve this situation. To achieve this goal, this paper presents a framework termed \textbf{C}lass-level Structural Relation Modeling and Smoothing for Visual Representation Learning (CSRMS), which includes the Class-level Relation Modelling, Class-aware Graph Sampling, and Relational Graph-Guided Representation Learning modules to model a relational graph of the entire dataset and perform class-aware smoothing and regularization operations to alleviate the issue of intra-class visual diversity and inter-class similarity. Specifically, the Class-level Relation Modelling module uses a clustering algorithm to learn the data distributions in the feature space and identify three types of class-level sample relations for the training set; Class-aware Graph Sampling module extends typical training batch construction process with three strategies to sample dataset-level sub-graphs; and Relational Graph-Guided Representation Learning module employs a graph convolution network with knowledge-guided smoothing operations to ease the projection from different visual patterns to the same class. Experiments demonstrate the effectiveness of structured knowledge modelling for enhanced representation learning and show that CSRMS can be incorporated with any state-of-the-art visual representation learning models for performance gains. The source codes and demos have been released at https://github.com/czt117/CSRMS.
Multi-modal Video Chapter Generation
Sep 26, 2022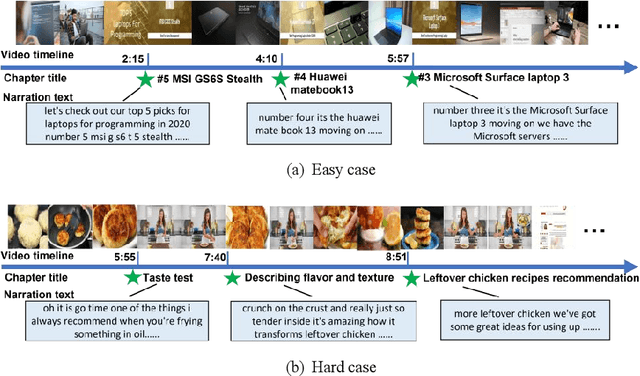
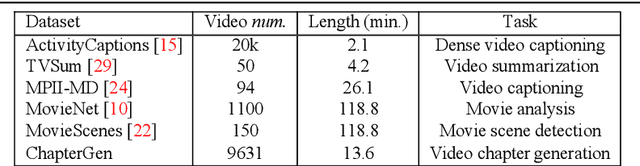
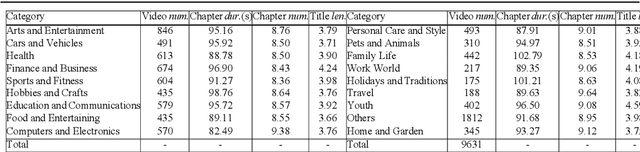
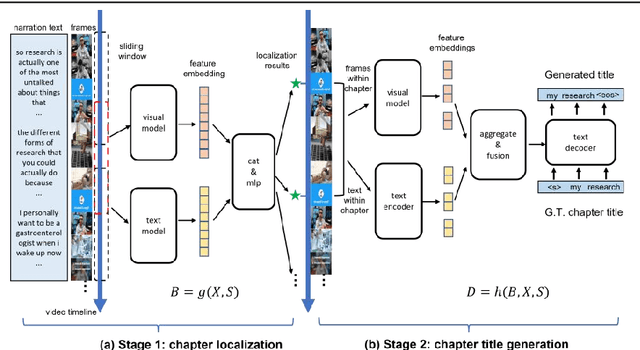
Chapter generation becomes practical technique for online videos nowadays. The chapter breakpoints enable users to quickly find the parts they want and get the summative annotations. However, there is no public method and dataset for this task. To facilitate the research along this direction, we introduce a new dataset called Chapter-Gen, which consists of approximately 10k user-generated videos with annotated chapter information. Our data collection procedure is fast, scalable and does not require any additional manual annotation. On top of this dataset, we design an effective baseline specificlly for video chapters generation task. which captures two aspects of a video,including visual dynamics and narration text. It disentangles local and global video features for localization and title generation respectively. To parse the long video efficiently, a skip sliding window mechanism is designed to localize potential chapters. And a cross attention multi-modal fusion module is developed to aggregate local features for title generation. Our experiments demonstrate that the proposed framework achieves superior results over existing methods which illustrate that the method design for similar task cannot be transfered directly even after fine-tuning. Code and dataset are available at https://github.com/czt117/MVCG.