 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Video Chapter Generation
Sep 26, 2022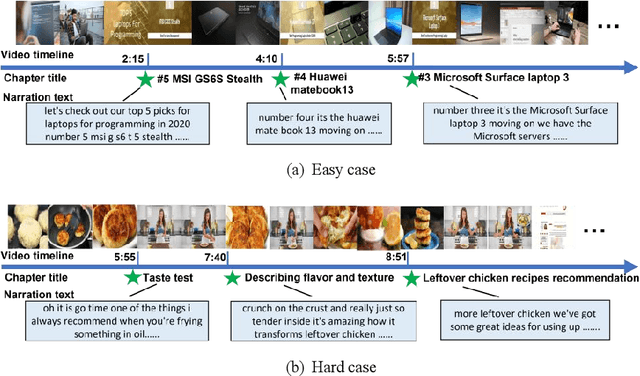
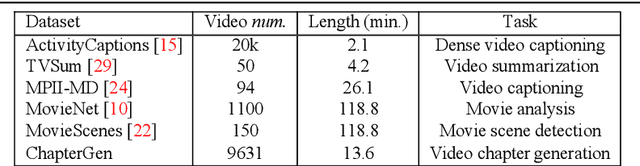
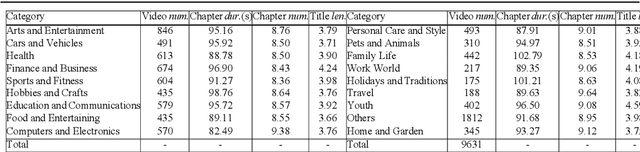
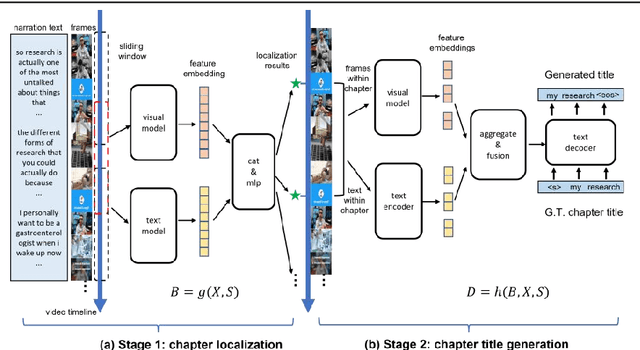
Chapter generation becomes practical technique for online videos nowadays. The chapter breakpoints enable users to quickly find the parts they want and get the summative annotations. However, there is no public method and dataset for this task. To facilitate the research along this direction, we introduce a new dataset called Chapter-Gen, which consists of approximately 10k user-generated videos with annotated chapter information. Our data collection procedure is fast, scalable and does not require any additional manual annotation. On top of this dataset, we design an effective baseline specificlly for video chapters generation task. which captures two aspects of a video,including visual dynamics and narration text. It disentangles local and global video features for localization and title generation respectively. To parse the long video efficiently, a skip sliding window mechanism is designed to localize potential chapters. And a cross attention multi-modal fusion module is developed to aggregate local features for title generation. Our experiments demonstrate that the proposed framework achieves superior results over existing methods which illustrate that the method design for similar task cannot be transfered directly even after fine-tuning. Code and dataset are available at https://github.com/czt117/MVCG.
Continual Local Replacement for Few-shot Image Recognition
Jan 23, 2020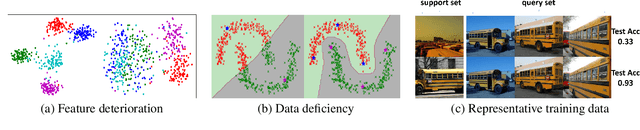
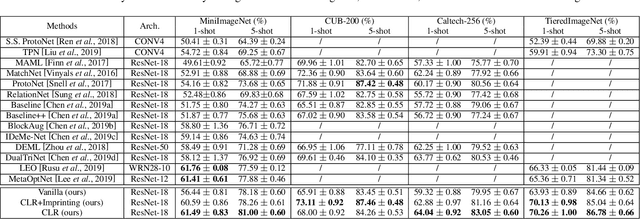

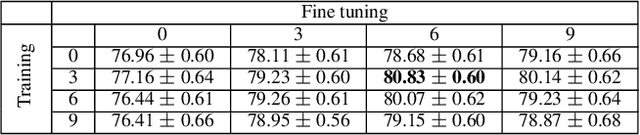
The goal of few-shot learning is to learn a model that can recognize novel classes based on one or few training data. It is challenging mainly due to two aspects: (1) it lacks good feature representation of novel classes; (2) a few labeled data could not accurately represent the true data distribution. In this work, we use a sophisticated network architecture to learn better feature representation and focus on the second issue. A novel continual local replacement strategy is proposed to address the data deficiency problem. It takes advantage of the content in unlabeled images to continually enhance labeled ones. Specifically, a pseudo labeling strategy is adopted to constantly select semantic similar images on the fly. Original labeled images will be locally replaced by the selected images for the next epoch training. In this way, the model can directly learn new semantic information from unlabeled images and the capacity of supervised signals in the embedding space can be significantly enlarged. This allows the model to improve generalization and learn a better decision boundary for classification. Extensive experiments demonstrate that our approach can achieve highly competitive results over existing methods on various few-shot image recognition benchmarks.
Learning Continually from Low-shot Data Stream
Sep 04, 2019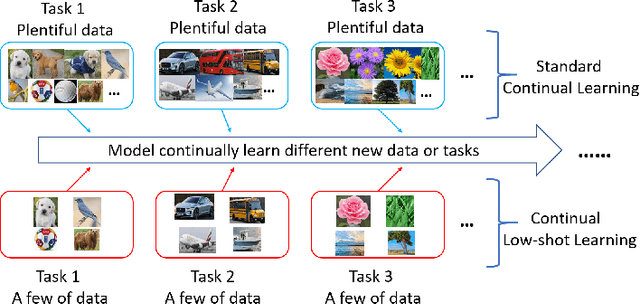
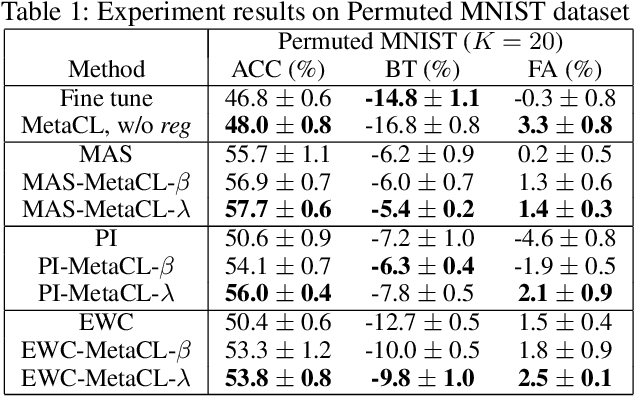
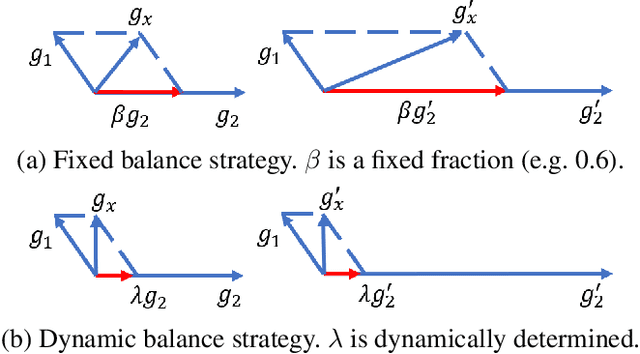
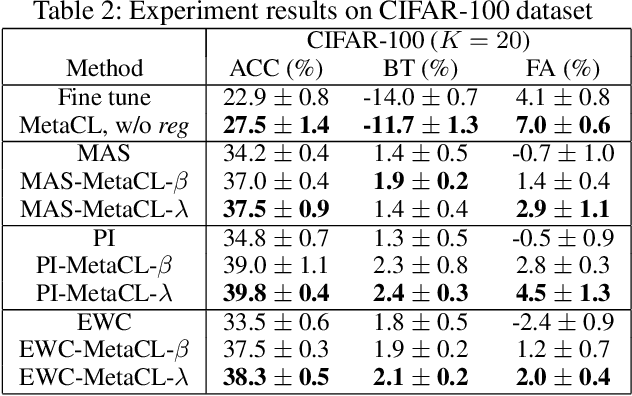
While deep learning has achieved remarkable results on various applications, it is usually data hungry and struggles to learn over non-stationary data stream. To solve these two limits, the deep learning model should not only be able to learn from a few of data, but also incrementally learn new concepts from data stream over time without forgetting the previous knowledge. Limited literature simultaneously address both problems. In this work, we propose a novel approach, MetaCL, which enables neural networks to effectively learn meta knowledge from low-shot data stream without catastrophic forgetting. MetaCL trains a model to exploit the intrinsic feature of data (i.e. meta knowledge) and dynamically penalize the important model parameters change to preserve learned knowledge. In this way, the deep learning model can efficiently obtain new knowledge from small volume of data and still keep high performance on previous tasks. MetaCL is conceptually simple, easy to implement and model-agnostic. We implement our method on three recent regularization-based methods. Extensive experiments show that our approach leads to state-of-the-art performance on image classification benchmarks.
JigsawNet: Shredded Image Reassembly using Convolutional Neural Network and Loop-based Composition
Sep 11, 2018
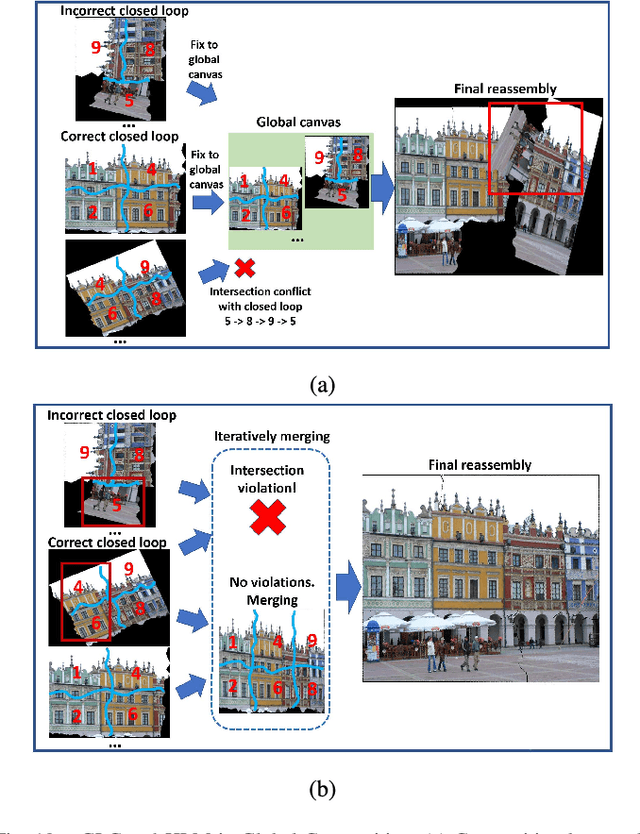

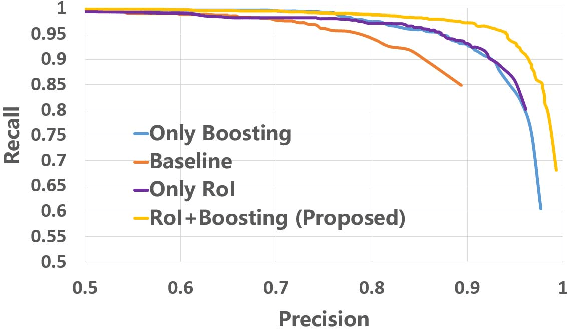
This paper proposes a novel algorithm to reassemble an arbitrarily shredded image to its original status. Existing reassembly pipelines commonly consist of a local matching stage and a global compositions stage. In the local stage, a key challenge in fragment reassembly is to reliably compute and identify correct pairwise matching, for which most existing algorithms use handcrafted features, and hence, cannot reliably handle complicated puzzles. We build a deep convolutional neural network to detect the compatibility of a pairwise stitching, and use it to prune computed pairwise matches. To improve the network efficiency and accuracy, we transfer the calculation of CNN to the stitching region and apply a boost training strategy. In the global composition stage, we modify the commonly adopted greedy edge selection strategies to two new loop closure based searching algorithms. Extensive experiments show that our algorithm significantly outperforms existing methods on solving various puzzles, especially those challenging ones with many fragment pieces.