 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRG-MotionLLM: Interleaving Motion Generation, Assessment and Refinement for Text-to-Motion Generation
Dec 11, 2025Recent advances in motion-aware large language models have shown remarkable promise for unifying motion understanding and generation tasks. However, these models typically treat understanding and generation separately, limiting the mutual benefits that could arise from interactive feedback between tasks. In this work, we reveal that motion assessment and refinement tasks act as crucial bridges to enable bidirectional knowledge flow between understanding and generation. Leveraging this insight, we propose Interleaved Reasoning for Motion Generation (IRMoGen), a novel paradigm that tightly couples motion generation with assessment and refinement through iterative text-motion dialogue. To realize this, we introduce IRG-MotionLLM, the first model that seamlessly interleaves motion generation, assessment, and refinement to improve generation performance. IRG-MotionLLM is developed progressively with a novel three-stage training scheme, initializing and subsequently enhancing native IRMoGen capabilities. To facilitate this development, we construct an automated data engine to synthesize interleaved reasoning annotations from existing text-motion datasets. Extensive experiments demonstrate that: (i) Assessment and refinement tasks significantly improve text-motion alignment; (ii) Interleaving motion generation, assessment, and refinement steps yields consistent performance gains across training stages; and (iii) IRG-MotionLLM clearly outperforms the baseline model and achieves advanced performance on standard text-to-motion generation benchmarks. Cross-evaluator testing further validates its effectiveness. Code & Data: https://github.com/HumanMLLM/IRG-MotionLLM/tree/main.
CoGenAV: Versatile Audio-Visual Representation Learning via Contrastive-Generative Synchronization
May 06, 2025The inherent synchronization between a speaker's lip movements, voice, and the underlying linguistic content offers a rich source of information for improving speech processing tasks, especially in challenging conditions where traditional audio-only systems falter. We introduce CoGenAV, a powerful and data-efficient model designed to learn versatile audio-visual representations applicable across a wide range of speech and audio-visual tasks. CoGenAV is trained by optimizing a dual objective derived from natural audio-visual synchrony, contrastive feature alignment and generative text prediction, using only 223 hours of labeled data from the LRS2 dataset. This contrastive-generative synchronization strategy effectively captures fundamental cross-modal correlations. We showcase the effectiveness and versatility of the learned CoGenAV representations on multiple benchmarks. When utilized for Audio-Visual Speech Recognition (AVSR) on LRS2, these representations contribute to achieving a state-of-the-art Word Error Rate (WER) of 1.27. They also enable strong performance in Visual Speech Recognition (VSR) with a WER of 22.0 on LRS2, and significantly improve performance in noisy environments by over 70%. Furthermore, CoGenAV representations benefit speech reconstruction tasks, boosting performance in Speech Enhancement and Separation, and achieve competitive results in audio-visual synchronization tasks like Active Speaker Detection (ASD). Our model will be open-sourced to facilitate further development and collaboration within both academia and industry.
ActionArt: Advancing Multimodal Large Models for Fine-Grained Human-Centric Video Understanding
Apr 25, 2025
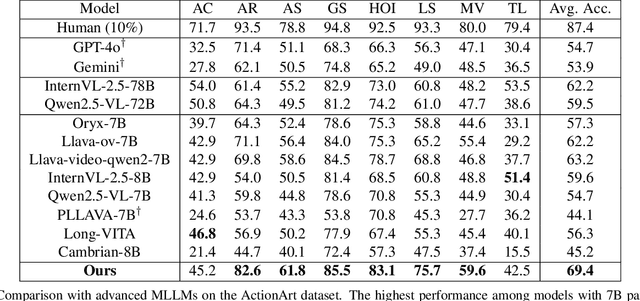
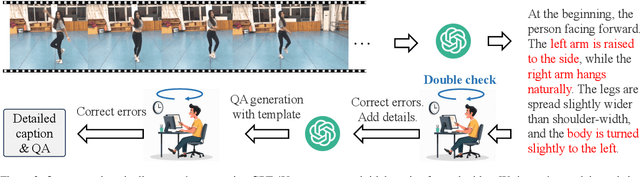
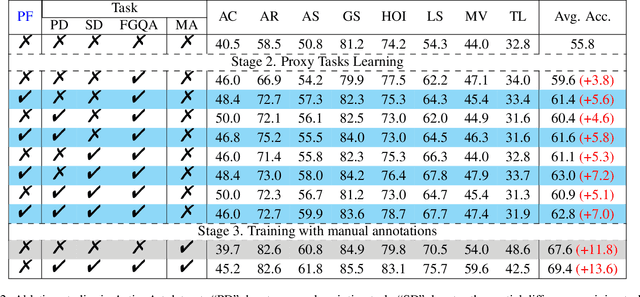
Fine-grained understanding of human actions and poses in videos is essential for human-centric AI applications. In this work, we introduce ActionArt, a fine-grained video-caption dataset designed to advance research in human-centric multimodal understanding. Our dataset comprises thousands of videos capturing a broad spectrum of human actions, human-object interactions, and diverse scenarios, each accompanied by detailed annotations that meticulously label every limb movement. We develop eight sub-tasks to evaluate the fine-grained understanding capabilities of existing large multimodal models across different dimensions. Experimental results indicate that, while current large multimodal models perform commendably on various tasks, they often fall short in achieving fine-grained understanding. We attribute this limitation to the scarcity of meticulously annotated data, which is both costly and difficult to scale manually. Since manual annotations are costly and hard to scale, we propose proxy tasks to enhance the model perception ability in both spatial and temporal dimensions. These proxy tasks are carefully crafted to be driven by data automatically generated from existing MLLMs, thereby reducing the reliance on costly manual labels. Experimental results show that the proposed proxy tasks significantly narrow the gap toward the performance achieved with manually annotated fine-grained data.
ViSpeak: Visual Instruction Feedback in Streaming Videos
Mar 17, 2025

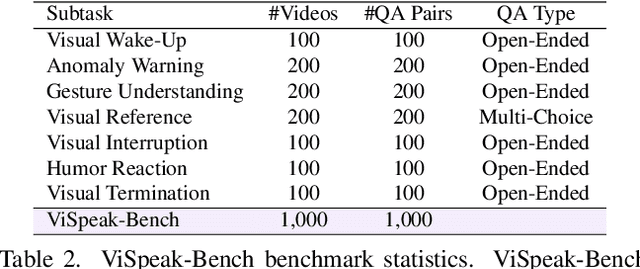
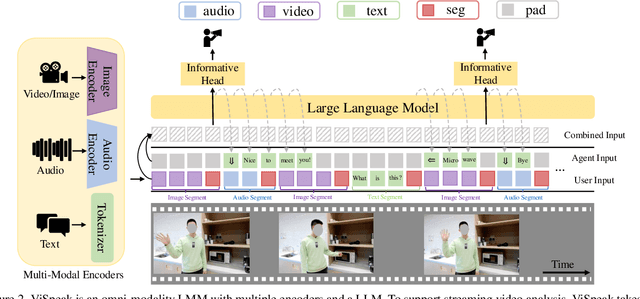
Recent advances in Large Multi-modal Models (LMMs) are primarily focused on offline video understanding. Instead, streaming video understanding poses great challenges to recent models due to its time-sensitive, omni-modal and interactive characteristics. In this work, we aim to extend the streaming video understanding from a new perspective and propose a novel task named Visual Instruction Feedback in which models should be aware of visual contents and learn to extract instructions from them. For example, when users wave their hands to agents, agents should recognize the gesture and start conversations with welcome information. Thus, following instructions in visual modality greatly enhances user-agent interactions. To facilitate research, we define seven key subtasks highly relevant to visual modality and collect the ViSpeak-Instruct dataset for training and the ViSpeak-Bench for evaluation. Further, we propose the ViSpeak model, which is a SOTA streaming video understanding LMM with GPT-4o-level performance on various streaming video understanding benchmarks. After finetuning on our ViSpeak-Instruct dataset, ViSpeak is equipped with basic visual instruction feedback ability, serving as a solid baseline for future research.
A Hierarchical Semantic Distillation Framework for Open-Vocabulary Object Detection
Mar 13, 2025



Open-vocabulary object detection (OVD) aims to detect objects beyond the training annotations, where detectors are usually aligned to a pre-trained vision-language model, eg, CLIP, to inherit its generalizable recognition ability so that detectors can recognize new or novel objects. However, previous works directly align the feature space with CLIP and fail to learn the semantic knowledge effectively. In this work, we propose a hierarchical semantic distillation framework named HD-OVD to construct a comprehensive distillation process, which exploits generalizable knowledge from the CLIP model in three aspects. In the first hierarchy of HD-OVD, the detector learns fine-grained instance-wise semantics from the CLIP image encoder by modeling relations among single objects in the visual space. Besides, we introduce text space novel-class-aware classification to help the detector assimilate the highly generalizable class-wise semantics from the CLIP text encoder, representing the second hierarchy. Lastly, abundant image-wise semantics containing multi-object and their contexts are also distilled by an image-wise contrastive distillation. Benefiting from the elaborated semantic distillation in triple hierarchies, our HD-OVD inherits generalizable recognition ability from CLIP in instance, class, and image levels. Thus, we boost the novel AP on the OV-COCO dataset to 46.4% with a ResNet50 backbone, which outperforms others by a clear margin. We also conduct extensive ablation studies to analyze how each component works.
R1-Omni: Explainable Omni-Multimodal Emotion Recognition with Reinforcing Learning
Mar 07, 2025
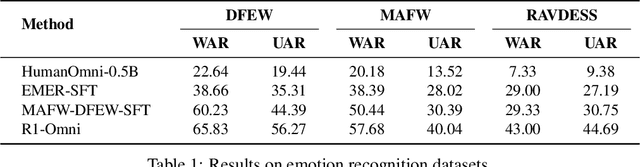


In this work, we present the first application of Reinforcement Learning with Verifiable Reward (RLVR) to an Omni-multimodal large language model in the context of emotion recognition, a task where both visual and audio modalities play crucial roles. We leverage RLVR to optimize the Omni model, significantly enhancing its performance in three key aspects: reasoning capability, emotion recognition accuracy, and generalization ability. The introduction of RLVR not only improves the model's overall performance on in-distribution data but also demonstrates superior robustness when evaluated on out-of-distribution datasets. More importantly, the improved reasoning capability enables clear analysis of the contributions of different modalities, particularly visual and audio information, in the emotion recognition process. This provides valuable insights into the optimization of multimodal large language models.
LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models
Jan 31, 2025



Recent open-vocabulary detectors achieve promising performance with abundant region-level annotated data. In this work, we show that an open-vocabulary detector co-training with a large language model by generating image-level detailed captions for each image can further improve performance. To achieve the goal, we first collect a dataset, GroundingCap-1M, wherein each image is accompanied by associated grounding labels and an image-level detailed caption. With this dataset, we finetune an open-vocabulary detector with training objectives including a standard grounding loss and a caption generation loss. We take advantage of a large language model to generate both region-level short captions for each region of interest and image-level long captions for the whole image. Under the supervision of the large language model, the resulting detector, LLMDet, outperforms the baseline by a clear margin, enjoying superior open-vocabulary ability. Further, we show that the improved LLMDet can in turn build a stronger large multi-modal model, achieving mutual benefits. The code, model, and dataset is available at https://github.com/iSEE-Laboratory/LLMDet.
HumanOmni: A Large Vision-Speech Language Model for Human-Centric Video Understanding
Jan 25, 2025



In human-centric scenes, the ability to simultaneously understand visual and auditory information is crucial. While recent omni models can process multiple modalities, they generally lack effectiveness in human-centric scenes due to the absence of large-scale, specialized datasets and non-targeted architectures. In this work, we developed HumanOmni, the industry's first human-centric Omni-multimodal large language model. We constructed a dataset containing over 2.4 million human-centric video clips with detailed captions and more than 14 million instructions, facilitating the understanding of diverse human-centric scenes. HumanOmni includes three specialized branches for understanding different types of scenes. It adaptively fuses features from these branches based on user instructions, significantly enhancing visual understanding in scenes centered around individuals. Moreover, HumanOmni integrates audio features to ensure a comprehensive understanding of environments and individuals. Our experiments validate HumanOmni's advanced capabilities in handling human-centric scenes across a variety of tasks, including emotion recognition, facial expression description, and action understanding. Our model will be open-sourced to facilitate further development and collaboration within both academia and industry.
Omni-Emotion: Extending Video MLLM with Detailed Face and Audio Modeling for Multimodal Emotion Analysis
Jan 16, 2025
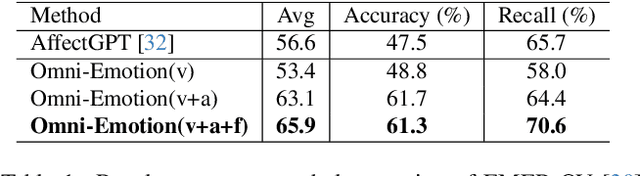
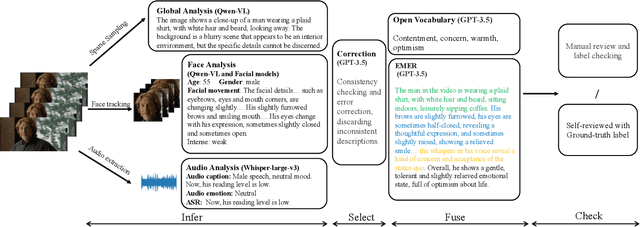
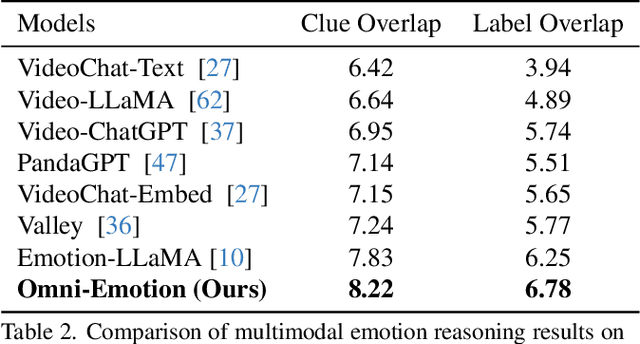
Understanding emotions accurately is essential for fields like human-computer interaction. Due to the complexity of emotions and their multi-modal nature (e.g., emotions are influenced by facial expressions and audio), researchers have turned to using multi-modal models to understand human emotions rather than single-modality. However, current video multi-modal large language models (MLLMs) encounter difficulties in effectively integrating audio and identifying subtle facial micro-expressions. Furthermore, the lack of detailed emotion analysis datasets also limits the development of multimodal emotion analysis. To address these issues, we introduce a self-reviewed dataset and a human-reviewed dataset, comprising 24,137 coarse-grained samples and 3,500 manually annotated samples with detailed emotion annotations, respectively. These datasets allow models to learn from diverse scenarios and better generalize to real-world applications. Moreover, in addition to the audio modeling, we propose to explicitly integrate facial encoding models into the existing advanced Video MLLM, enabling the MLLM to effectively unify audio and the subtle facial cues for emotion understanding. By aligning these features within a unified space and employing instruction tuning in our proposed datasets, our Omni-Emotion achieves state-of-the-art performance in both emotion recognition and reasoning tasks.
Facial Dynamics in Video: Instruction Tuning for Improved Facial Expression Perception and Contextual Awareness
Jan 14, 2025



Facial expression captioning has found widespread application across various domains. Recently, the emergence of video Multimodal Large Language Models (MLLMs) has shown promise in general video understanding tasks. However, describing facial expressions within videos poses two major challenges for these models: (1) the lack of adequate datasets and benchmarks, and (2) the limited visual token capacity of video MLLMs. To address these issues, this paper introduces a new instruction-following dataset tailored for dynamic facial expression caption. The dataset comprises 5,033 high-quality video clips annotated manually, containing over 700,000 tokens. Its purpose is to improve the capability of video MLLMs to discern subtle facial nuances. Furthermore, we propose FaceTrack-MM, which leverages a limited number of tokens to encode the main character's face. This model demonstrates superior performance in tracking faces and focusing on the facial expressions of the main characters, even in intricate multi-person scenarios. Additionally, we introduce a novel evaluation metric combining event extraction, relation classification, and the longest common subsequence (LCS) algorithm to assess the content consistency and temporal sequence consistency of generated text. Moreover, we present FEC-Bench, a benchmark designed to assess the performance of existing video MLLMs in this specific task. All data and source code will be made publicly available.