 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Semantic Distillation Framework for Open-Vocabulary Object Detection
Mar 13, 2025



Open-vocabulary object detection (OVD) aims to detect objects beyond the training annotations, where detectors are usually aligned to a pre-trained vision-language model, eg, CLIP, to inherit its generalizable recognition ability so that detectors can recognize new or novel objects. However, previous works directly align the feature space with CLIP and fail to learn the semantic knowledge effectively. In this work, we propose a hierarchical semantic distillation framework named HD-OVD to construct a comprehensive distillation process, which exploits generalizable knowledge from the CLIP model in three aspects. In the first hierarchy of HD-OVD, the detector learns fine-grained instance-wise semantics from the CLIP image encoder by modeling relations among single objects in the visual space. Besides, we introduce text space novel-class-aware classification to help the detector assimilate the highly generalizable class-wise semantics from the CLIP text encoder, representing the second hierarchy. Lastly, abundant image-wise semantics containing multi-object and their contexts are also distilled by an image-wise contrastive distillation. Benefiting from the elaborated semantic distillation in triple hierarchies, our HD-OVD inherits generalizable recognition ability from CLIP in instance, class, and image levels. Thus, we boost the novel AP on the OV-COCO dataset to 46.4% with a ResNet50 backbone, which outperforms others by a clear margin. We also conduct extensive ablation studies to analyze how each component works.
LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models
Jan 31, 2025



Recent open-vocabulary detectors achieve promising performance with abundant region-level annotated data. In this work, we show that an open-vocabulary detector co-training with a large language model by generating image-level detailed captions for each image can further improve performance. To achieve the goal, we first collect a dataset, GroundingCap-1M, wherein each image is accompanied by associated grounding labels and an image-level detailed caption. With this dataset, we finetune an open-vocabulary detector with training objectives including a standard grounding loss and a caption generation loss. We take advantage of a large language model to generate both region-level short captions for each region of interest and image-level long captions for the whole image. Under the supervision of the large language model, the resulting detector, LLMDet, outperforms the baseline by a clear margin, enjoying superior open-vocabulary ability. Further, we show that the improved LLMDet can in turn build a stronger large multi-modal model, achieving mutual benefits. The code, model, and dataset is available at https://github.com/iSEE-Laboratory/LLMDet.
Frozen-DETR: Enhancing DETR with Image Understanding from Frozen Foundation Models
Oct 25, 2024



Recent vision foundation models can extract universal representations and show impressive abilities in various tasks. However, their application on object detection is largely overlooked, especially without fine-tuning them. In this work, we show that frozen foundation models can be a versatile feature enhancer, even though they are not pre-trained for object detection. Specifically, we explore directly transferring the high-level image understanding of foundation models to detectors in the following two ways. First, the class token in foundation models provides an in-depth understanding of the complex scene, which facilitates decoding object queries in the detector's decoder by providing a compact context. Additionally, the patch tokens in foundation models can enrich the features in the detector's encoder by providing semantic details. Utilizing frozen foundation models as plug-and-play modules rather than the commonly used backbone can significantly enhance the detector's performance while preventing the problems caused by the architecture discrepancy between the detector's backbone and the foundation model. With such a novel paradigm, we boost the SOTA query-based detector DINO from 49.0% AP to 51.9% AP (+2.9% AP) and further to 53.8% AP (+4.8% AP) by integrating one or two foundation models respectively, on the COCO validation set after training for 12 epochs with R50 as the detector's backbone.
Loc4Plan: Locating Before Planning for Outdoor Vision and Language Navigation
Aug 09, 2024



Vision and Language Navigation (VLN) is a challenging task that requires agents to understand instructions and navigate to the destination in a visual environment.One of the key challenges in outdoor VLN is keeping track of which part of the instruction was completed. To alleviate this problem, previous works mainly focus on grounding the natural language to the visual input, but neglecting the crucial role of the agent's spatial position information in the grounding process. In this work, we first explore the substantial effect of spatial position locating on the grounding of outdoor VLN, drawing inspiration from human navigation. In real-world navigation scenarios, before planning a path to the destination, humans typically need to figure out their current location. This observation underscores the pivotal role of spatial localization in the navigation process. In this work, we introduce a novel framework, Locating be for Planning (Loc4Plan), designed to incorporate spatial perception for action planning in outdoor VLN tasks. The main idea behind Loc4Plan is to perform the spatial localization before planning a decision action based on corresponding guidance, which comprises a block-aware spatial locating (BAL) module and a spatial-aware action planning (SAP) module. Specifically, to help the agent perceive its spatial location in the environment, we propose to learn a position predictor that measures how far the agent is from the next intersection for reflecting its position, which is achieved by the BAL module. After the locating process, we propose the SAP module to incorporate spatial information to ground the corresponding guidance and enhance the precision of action planning. Extensive experiments on the Touchdown and map2seq datasets show that the proposed Loc4Plan outperforms the SOTA methods.
Bridge Past and Future: Overcoming Information Asymmetry in Incremental Object Detection
Jul 16, 2024



In incremental object detection, knowledge distillation has been proven to be an effective way to alleviate catastrophic forgetting. However, previous works focused on preserving the knowledge of old models, ignoring that images could simultaneously contain categories from past, present, and future stages. The co-occurrence of objects makes the optimization objectives inconsistent across different stages since the definition for foreground objects differs across various stages, which limits the model's performance greatly. To overcome this problem, we propose a method called ``Bridge Past and Future'' (BPF), which aligns models across stages, ensuring consistent optimization directions. In addition, we propose a novel Distillation with Future (DwF) loss, fully leveraging the background probability to mitigate the forgetting of old classes while ensuring a high level of adaptability in learning new classes. Extensive experiments are conducted on both Pascal VOC and MS COCO benchmarks. Without memory, BPF outperforms current state-of-the-art methods under various settings. The code is available at https://github.com/iSEE-Laboratory/BPF.
DreamView: Injecting View-specific Text Guidance into Text-to-3D Generation
Apr 09, 2024



Text-to-3D generation, which synthesizes 3D assets according to an overall text description, has significantly progressed. However, a challenge arises when the specific appearances need customizing at designated viewpoints but referring solely to the overall description for generating 3D objects. For instance, ambiguity easily occurs when producing a T-shirt with distinct patterns on its front and back using a single overall text guidance. In this work, we propose DreamView, a text-to-image approach enabling multi-view customization while maintaining overall consistency by adaptively injecting the view-specific and overall text guidance through a collaborative text guidance injection module, which can also be lifted to 3D generation via score distillation sampling. DreamView is trained with large-scale rendered multi-view images and their corresponding view-specific texts to learn to balance the separate content manipulation in each view and the global consistency of the overall object, resulting in a dual achievement of customization and consistency. Consequently, DreamView empowers artists to design 3D objects creatively, fostering the creation of more innovative and diverse 3D assets. Code and model will be released at https://github.com/iSEE-Laboratory/DreamView.
A Versatile Framework for Multi-scene Person Re-identification
Mar 17, 2024



Person Re-identification (ReID) has been extensively developed for a decade in order to learn the association of images of the same person across non-overlapping camera views. To overcome significant variations between images across camera views, mountains of variants of ReID models were developed for solving a number of challenges, such as resolution change, clothing change, occlusion, modality change, and so on. Despite the impressive performance of many ReID variants, these variants typically function distinctly and cannot be applied to other challenges. To our best knowledge, there is no versatile ReID model that can handle various ReID challenges at the same time. This work contributes to the first attempt at learning a versatile ReID model to solve such a problem. Our main idea is to form a two-stage prompt-based twin modeling framework called VersReID. Our VersReID firstly leverages the scene label to train a ReID Bank that contains abundant knowledge for handling various scenes, where several groups of scene-specific prompts are used to encode different scene-specific knowledge. In the second stage, we distill a V-Branch model with versatile prompts from the ReID Bank for adaptively solving the ReID of different scenes, eliminating the demand for scene labels during the inference stage. To facilitate training VersReID, we further introduce the multi-scene properties into self-supervised learning of ReID via a multi-scene prioris data augmentation (MPDA) strategy. Through extensive experiments, we demonstrate the success of learning an effective and versatile ReID model for handling ReID tasks under multi-scene conditions without manual assignment of scene labels in the inference stage, including general, low-resolution, clothing change, occlusion, and cross-modality scenes. Codes and models are available at https://github.com/iSEE-Laboratory/VersReID.
ASAG: Building Strong One-Decoder-Layer Sparse Detectors via Adaptive Sparse Anchor Generation
Aug 18, 2023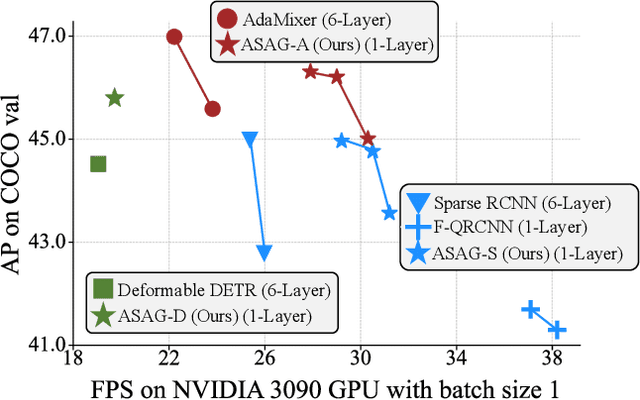

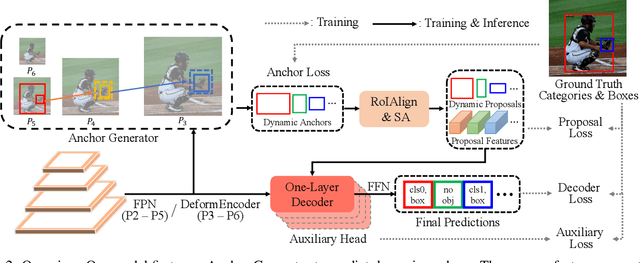

Recent sparse detectors with multiple, e.g. six, decoder layers achieve promising performance but much inference time due to complex heads. Previous works have explored using dense priors as initialization and built one-decoder-layer detectors. Although they gain remarkable acceleration, their performance still lags behind their six-decoder-layer counterparts by a large margin. In this work, we aim to bridge this performance gap while retaining fast speed. We find that the architecture discrepancy between dense and sparse detectors leads to feature conflict, hampering the performance of one-decoder-layer detectors. Thus we propose Adaptive Sparse Anchor Generator (ASAG) which predicts dynamic anchors on patches rather than grids in a sparse way so that it alleviates the feature conflict problem. For each image, ASAG dynamically selects which feature maps and which locations to predict, forming a fully adaptive way to generate image-specific anchors. Further, a simple and effective Query Weighting method eases the training instability from adaptiveness. Extensive experiments show that our method outperforms dense-initialized ones and achieves a better speed-accuracy trade-off. The code is available at \url{https://github.com/iSEE-Laboratory/ASAG}.