 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Whole-Body Human-Humanoid Interaction from Human-Human Demonstrations
Jan 14, 2026Enabling humanoid robots to physically interact with humans is a critical frontier, but progress is hindered by the scarcity of high-quality Human-Humanoid Interaction (HHoI) data. While leveraging abundant Human-Human Interaction (HHI) data presents a scalable alternative, we first demonstrate that standard retargeting fails by breaking the essential contacts. We address this with PAIR (Physics-Aware Interaction Retargeting), a contact-centric, two-stage pipeline that preserves contact semantics across morphology differences to generate physically consistent HHoI data. This high-quality data, however, exposes a second failure: conventional imitation learning policies merely mimic trajectories and lack interactive understanding. We therefore introduce D-STAR (Decoupled Spatio-Temporal Action Reasoner), a hierarchical policy that disentangles when to act from where to act. In D-STAR, Phase Attention (when) and a Multi-Scale Spatial module (where) are fused by the diffusion head to produce synchronized whole-body behaviors beyond mimicry. By decoupling these reasoning streams, our model learns robust temporal phases without being distracted by spatial noise, leading to responsive, synchronized collaboration. We validate our framework through extensive and rigorous simulations, demonstrating significant performance gains over baseline approaches and a complete, effective pipeline for learning complex whole-body interactions from HHI data.
IRG-MotionLLM: Interleaving Motion Generation, Assessment and Refinement for Text-to-Motion Generation
Dec 11, 2025Recent advances in motion-aware large language models have shown remarkable promise for unifying motion understanding and generation tasks. However, these models typically treat understanding and generation separately, limiting the mutual benefits that could arise from interactive feedback between tasks. In this work, we reveal that motion assessment and refinement tasks act as crucial bridges to enable bidirectional knowledge flow between understanding and generation. Leveraging this insight, we propose Interleaved Reasoning for Motion Generation (IRMoGen), a novel paradigm that tightly couples motion generation with assessment and refinement through iterative text-motion dialogue. To realize this, we introduce IRG-MotionLLM, the first model that seamlessly interleaves motion generation, assessment, and refinement to improve generation performance. IRG-MotionLLM is developed progressively with a novel three-stage training scheme, initializing and subsequently enhancing native IRMoGen capabilities. To facilitate this development, we construct an automated data engine to synthesize interleaved reasoning annotations from existing text-motion datasets. Extensive experiments demonstrate that: (i) Assessment and refinement tasks significantly improve text-motion alignment; (ii) Interleaving motion generation, assessment, and refinement steps yields consistent performance gains across training stages; and (iii) IRG-MotionLLM clearly outperforms the baseline model and achieves advanced performance on standard text-to-motion generation benchmarks. Cross-evaluator testing further validates its effectiveness. Code & Data: https://github.com/HumanMLLM/IRG-MotionLLM/tree/main.
Modeling Multiple Normal Action Representations for Error Detection in Procedural Tasks
Apr 02, 2025



Error detection in procedural activities is essential for consistent and correct outcomes in AR-assisted and robotic systems. Existing methods often focus on temporal ordering errors or rely on static prototypes to represent normal actions. However, these approaches typically overlook the common scenario where multiple, distinct actions are valid following a given sequence of executed actions. This leads to two issues: (1) the model cannot effectively detect errors using static prototypes when the inference environment or action execution distribution differs from training; and (2) the model may also use the wrong prototypes to detect errors if the ongoing action label is not the same as the predicted one. To address this problem, we propose an Adaptive Multiple Normal Action Representation (AMNAR) framework. AMNAR predicts all valid next actions and reconstructs their corresponding normal action representations, which are compared against the ongoing action to detect errors. Extensive experiments demonstrate that AMNAR achieves state-of-the-art performance, highlighting the effectiveness of AMNAR and the importance of modeling multiple valid next actions in error detection. The code is available at https://github.com/iSEE-Laboratory/AMNAR.
ViSpeak: Visual Instruction Feedback in Streaming Videos
Mar 17, 2025

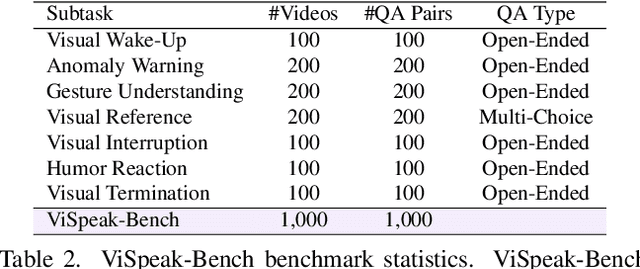
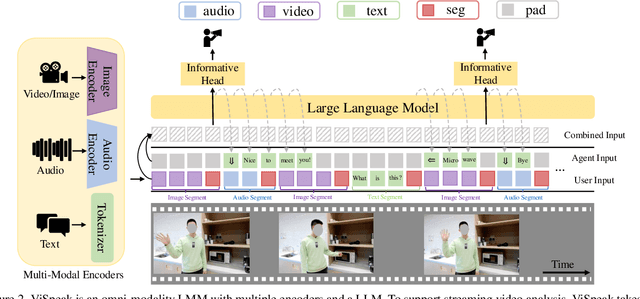
Recent advances in Large Multi-modal Models (LMMs) are primarily focused on offline video understanding. Instead, streaming video understanding poses great challenges to recent models due to its time-sensitive, omni-modal and interactive characteristics. In this work, we aim to extend the streaming video understanding from a new perspective and propose a novel task named Visual Instruction Feedback in which models should be aware of visual contents and learn to extract instructions from them. For example, when users wave their hands to agents, agents should recognize the gesture and start conversations with welcome information. Thus, following instructions in visual modality greatly enhances user-agent interactions. To facilitate research, we define seven key subtasks highly relevant to visual modality and collect the ViSpeak-Instruct dataset for training and the ViSpeak-Bench for evaluation. Further, we propose the ViSpeak model, which is a SOTA streaming video understanding LMM with GPT-4o-level performance on various streaming video understanding benchmarks. After finetuning on our ViSpeak-Instruct dataset, ViSpeak is equipped with basic visual instruction feedback ability, serving as a solid baseline for future research.
TechCoach: Towards Technical Keypoint-Aware Descriptive Action Coaching
Nov 26, 2024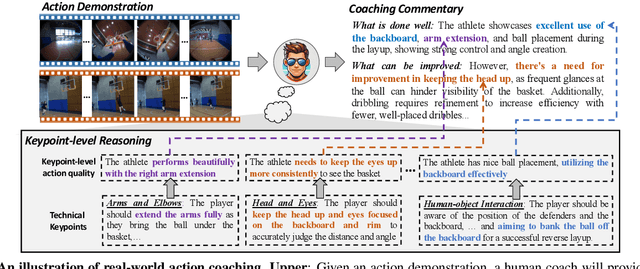
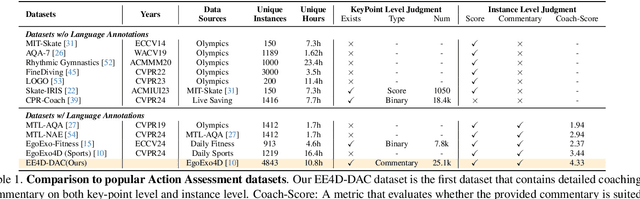
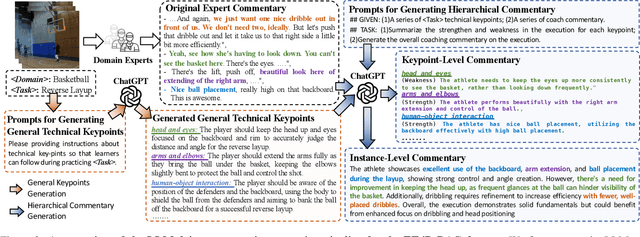

To guide a learner to master the action skills, it is crucial for a coach to 1) reason through the learner's action execution and technical keypoints, and 2) provide detailed, understandable feedback on what is done well and what can be improved. However, existing score-based action assessment methods are still far from this practical scenario. To bridge this gap, we investigate a new task termed Descriptive Action Coaching (DAC) which requires a model to provide detailed commentary on what is done well and what can be improved beyond a quality score from an action execution. To this end, we construct a new dataset named EE4D-DAC. With an LLM-based annotation pipeline, our dataset goes beyond the existing action assessment datasets by providing the hierarchical coaching commentary at both keypoint and instance levels. Furthermore, we propose TechCoach, a new framework that explicitly incorporates keypoint-level reasoning into the DAC process. The central to our method lies in the Context-aware Keypoint Reasoner, which enables TechCoach to learn keypoint-related quality representations by querying visual context under the supervision of keypoint-level coaching commentary. Prompted by the visual context and the keypoint-related quality representations, a unified Keypoint-aware Action Assessor is then employed to provide the overall coaching commentary together with the quality score. Combining all of these, we build a new benchmark for DAC and evaluate the effectiveness of our method through extensive experiments. Data and code will be publicly available.
Loc4Plan: Locating Before Planning for Outdoor Vision and Language Navigation
Aug 09, 2024



Vision and Language Navigation (VLN) is a challenging task that requires agents to understand instructions and navigate to the destination in a visual environment.One of the key challenges in outdoor VLN is keeping track of which part of the instruction was completed. To alleviate this problem, previous works mainly focus on grounding the natural language to the visual input, but neglecting the crucial role of the agent's spatial position information in the grounding process. In this work, we first explore the substantial effect of spatial position locating on the grounding of outdoor VLN, drawing inspiration from human navigation. In real-world navigation scenarios, before planning a path to the destination, humans typically need to figure out their current location. This observation underscores the pivotal role of spatial localization in the navigation process. In this work, we introduce a novel framework, Locating be for Planning (Loc4Plan), designed to incorporate spatial perception for action planning in outdoor VLN tasks. The main idea behind Loc4Plan is to perform the spatial localization before planning a decision action based on corresponding guidance, which comprises a block-aware spatial locating (BAL) module and a spatial-aware action planning (SAP) module. Specifically, to help the agent perceive its spatial location in the environment, we propose to learn a position predictor that measures how far the agent is from the next intersection for reflecting its position, which is achieved by the BAL module. After the locating process, we propose the SAP module to incorporate spatial information to ground the corresponding guidance and enhance the precision of action planning. Extensive experiments on the Touchdown and map2seq datasets show that the proposed Loc4Plan outperforms the SOTA methods.
EgoExo-Fitness: Towards Egocentric and Exocentric Full-Body Action Understanding
Jun 13, 2024We present EgoExo-Fitness, a new full-body action understanding dataset, featuring fitness sequence videos recorded from synchronized egocentric and fixed exocentric (third-person) cameras. Compared with existing full-body action understanding datasets, EgoExo-Fitness not only contains videos from first-person perspectives, but also provides rich annotations. Specifically, two-level temporal boundaries are provided to localize single action videos along with sub-steps of each action. More importantly, EgoExo-Fitness introduces innovative annotations for interpretable action judgement--including technical keypoint verification, natural language comments on action execution, and action quality scores. Combining all of these, EgoExo-Fitness provides new resources to study egocentric and exocentric full-body action understanding across dimensions of "what", "when", and "how well". To facilitate research on egocentric and exocentric full-body action understanding, we construct benchmarks on a suite of tasks (i.e., action classification, action localization, cross-view sequence verification, cross-view skill determination, and a newly proposed task of guidance-based execution verification), together with detailed analysis. Code and data will be available at https://github.com/iSEE-Laboratory/EgoExo-Fitness/tree/main.
Continual Action Assessment via Task-Consistent Score-Discriminative Feature Distribution Modeling
Sep 29, 2023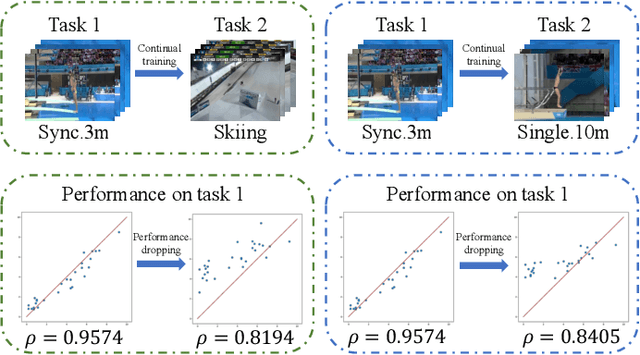
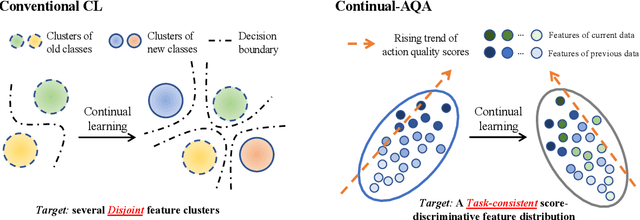
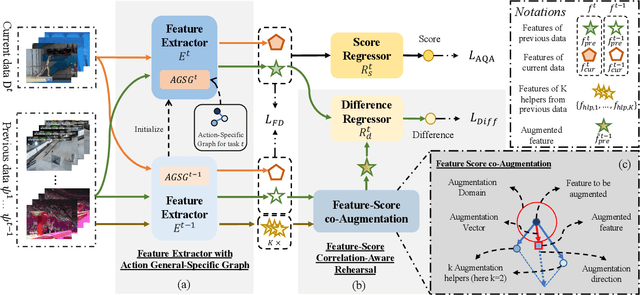
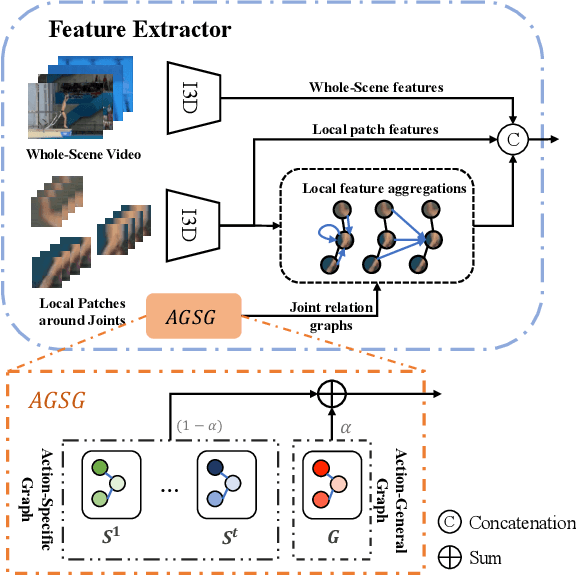
Action Quality Assessment (AQA) is a task that tries to answer how well an action is carried out. While remarkable progress has been achieved, existing works on AQA assume that all the training data are visible for training in one time, but do not enable continual learning on assessing new technical actions. In this work, we address such a Continual Learning problem in AQA (Continual-AQA), which urges a unified model to learn AQA tasks sequentially without forgetting. Our idea for modeling Continual-AQA is to sequentially learn a task-consistent score-discriminative feature distribution, in which the latent features express a strong correlation with the score labels regardless of the task or action types. From this perspective, we aim to mitigate the forgetting in Continual-AQA from two aspects. Firstly, to fuse the features of new and previous data into a score-discriminative distribution, a novel Feature-Score Correlation-Aware Rehearsal is proposed to store and reuse data from previous tasks with limited memory size. Secondly, an Action General-Specific Graph is developed to learn and decouple the action-general and action-specific knowledge so that the task-consistent score-discriminative features can be better extracted across various tasks. Extensive experiments are conducted to evaluate the contributions of proposed components. The comparisons with the existing continual learning methods additionally verify the effectiveness and versatility of our approach.