 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionArt: Advancing Multimodal Large Models for Fine-Grained Human-Centric Video Understanding
Apr 25, 2025
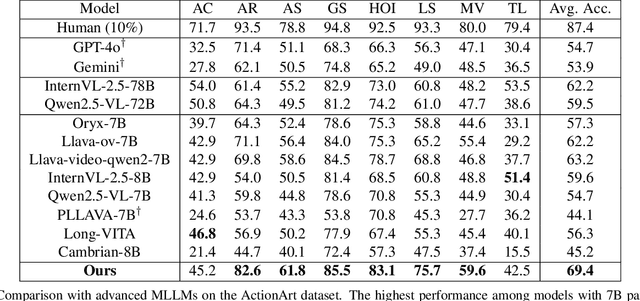
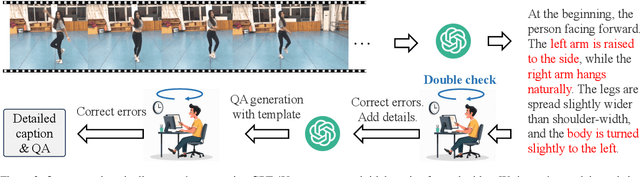
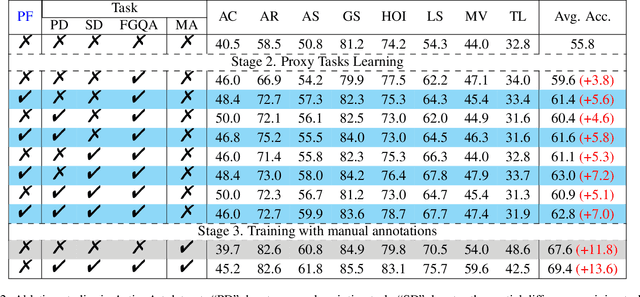
Fine-grained understanding of human actions and poses in videos is essential for human-centric AI applications. In this work, we introduce ActionArt, a fine-grained video-caption dataset designed to advance research in human-centric multimodal understanding. Our dataset comprises thousands of videos capturing a broad spectrum of human actions, human-object interactions, and diverse scenarios, each accompanied by detailed annotations that meticulously label every limb movement. We develop eight sub-tasks to evaluate the fine-grained understanding capabilities of existing large multimodal models across different dimensions. Experimental results indicate that, while current large multimodal models perform commendably on various tasks, they often fall short in achieving fine-grained understanding. We attribute this limitation to the scarcity of meticulously annotated data, which is both costly and difficult to scale manually. Since manual annotations are costly and hard to scale, we propose proxy tasks to enhance the model perception ability in both spatial and temporal dimensions. These proxy tasks are carefully crafted to be driven by data automatically generated from existing MLLMs, thereby reducing the reliance on costly manual labels. Experimental results show that the proposed proxy tasks significantly narrow the gap toward the performance achieved with manually annotated fine-grained data.
ViSpeak: Visual Instruction Feedback in Streaming Videos
Mar 17, 2025

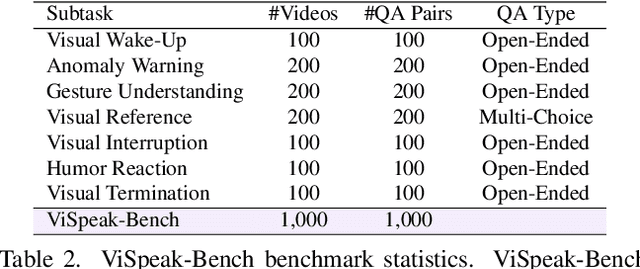
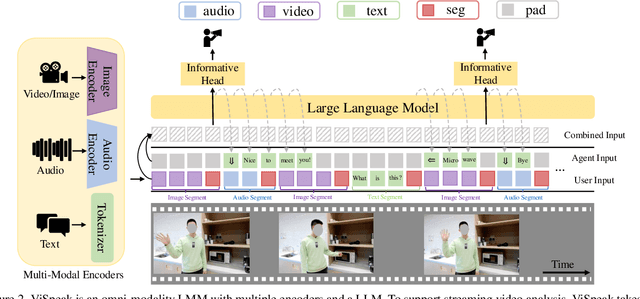
Recent advances in Large Multi-modal Models (LMMs) are primarily focused on offline video understanding. Instead, streaming video understanding poses great challenges to recent models due to its time-sensitive, omni-modal and interactive characteristics. In this work, we aim to extend the streaming video understanding from a new perspective and propose a novel task named Visual Instruction Feedback in which models should be aware of visual contents and learn to extract instructions from them. For example, when users wave their hands to agents, agents should recognize the gesture and start conversations with welcome information. Thus, following instructions in visual modality greatly enhances user-agent interactions. To facilitate research, we define seven key subtasks highly relevant to visual modality and collect the ViSpeak-Instruct dataset for training and the ViSpeak-Bench for evaluation. Further, we propose the ViSpeak model, which is a SOTA streaming video understanding LMM with GPT-4o-level performance on various streaming video understanding benchmarks. After finetuning on our ViSpeak-Instruct dataset, ViSpeak is equipped with basic visual instruction feedback ability, serving as a solid baseline for future research.
Omni-Emotion: Extending Video MLLM with Detailed Face and Audio Modeling for Multimodal Emotion Analysis
Jan 16, 2025
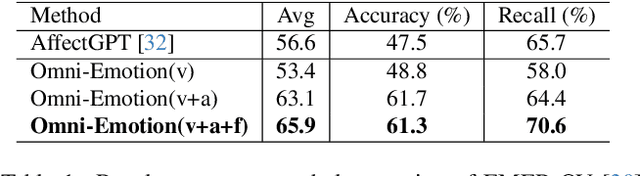
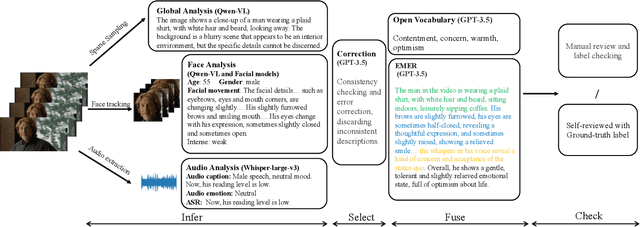
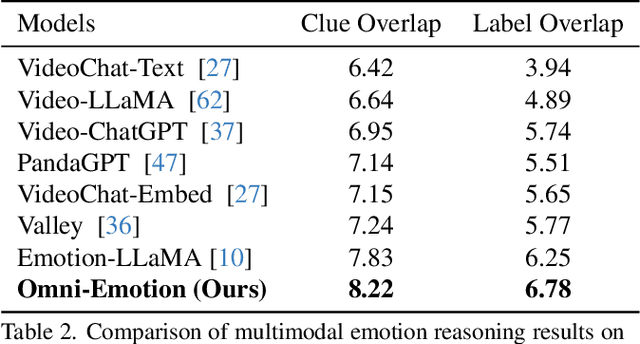
Understanding emotions accurately is essential for fields like human-computer interaction. Due to the complexity of emotions and their multi-modal nature (e.g., emotions are influenced by facial expressions and audio), researchers have turned to using multi-modal models to understand human emotions rather than single-modality. However, current video multi-modal large language models (MLLMs) encounter difficulties in effectively integrating audio and identifying subtle facial micro-expressions. Furthermore, the lack of detailed emotion analysis datasets also limits the development of multimodal emotion analysis. To address these issues, we introduce a self-reviewed dataset and a human-reviewed dataset, comprising 24,137 coarse-grained samples and 3,500 manually annotated samples with detailed emotion annotations, respectively. These datasets allow models to learn from diverse scenarios and better generalize to real-world applications. Moreover, in addition to the audio modeling, we propose to explicitly integrate facial encoding models into the existing advanced Video MLLM, enabling the MLLM to effectively unify audio and the subtle facial cues for emotion understanding. By aligning these features within a unified space and employing instruction tuning in our proposed datasets, our Omni-Emotion achieves state-of-the-art performance in both emotion recognition and reasoning tasks.
PixelFade: Privacy-preserving Person Re-identification with Noise-guided Progressive Replacement
Aug 10, 2024Online person re-identification services face privacy breaches from potential data leakage and recovery attacks, exposing cloud-stored images to malicious attackers and triggering public concern. The privacy protection of pedestrian images is crucial. Previous privacy-preserving person re-identification methods are unable to resist recovery attacks and compromise accuracy. In this paper, we propose an iterative method (PixelFade) to optimize pedestrian images into noise-like images to resist recovery attacks. We first give an in-depth study of protected images from previous privacy methods, which reveal that the chaos of protected images can disrupt the learning of recovery models. Accordingly, Specifically, we propose Noise-guided Objective Function with the feature constraints of a specific authorization model, optimizing pedestrian images to normal-distributed noise images while preserving their original identity information as per the authorization model. To solve the above non-convex optimization problem, we propose a heuristic optimization algorithm that alternately performs the Constraint Operation and the Partial Replacement Operation. This strategy not only safeguards that original pixels are replaced with noises to protect privacy, but also guides the images towards an improved optimization direction to effectively preserve discriminative features. Extensive experiments demonstrate that our PixelFade outperforms previous methods in resisting recovery attacks and Re-ID performance. The code is available at https://github.com/iSEE-Laboratory/PixelFade.
A Versatile Framework for Multi-scene Person Re-identification
Mar 17, 2024



Person Re-identification (ReID) has been extensively developed for a decade in order to learn the association of images of the same person across non-overlapping camera views. To overcome significant variations between images across camera views, mountains of variants of ReID models were developed for solving a number of challenges, such as resolution change, clothing change, occlusion, modality change, and so on. Despite the impressive performance of many ReID variants, these variants typically function distinctly and cannot be applied to other challenges. To our best knowledge, there is no versatile ReID model that can handle various ReID challenges at the same time. This work contributes to the first attempt at learning a versatile ReID model to solve such a problem. Our main idea is to form a two-stage prompt-based twin modeling framework called VersReID. Our VersReID firstly leverages the scene label to train a ReID Bank that contains abundant knowledge for handling various scenes, where several groups of scene-specific prompts are used to encode different scene-specific knowledge. In the second stage, we distill a V-Branch model with versatile prompts from the ReID Bank for adaptively solving the ReID of different scenes, eliminating the demand for scene labels during the inference stage. To facilitate training VersReID, we further introduce the multi-scene properties into self-supervised learning of ReID via a multi-scene prioris data augmentation (MPDA) strategy. Through extensive experiments, we demonstrate the success of learning an effective and versatile ReID model for handling ReID tasks under multi-scene conditions without manual assignment of scene labels in the inference stage, including general, low-resolution, clothing change, occlusion, and cross-modality scenes. Codes and models are available at https://github.com/iSEE-Laboratory/VersReID.
Rethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition
Mar 03, 2024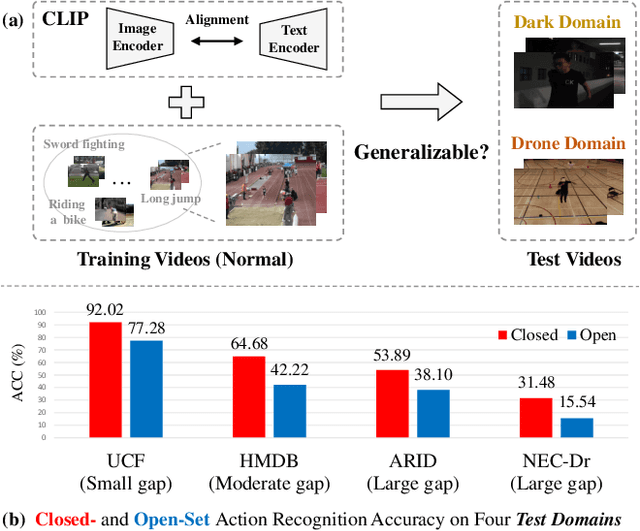
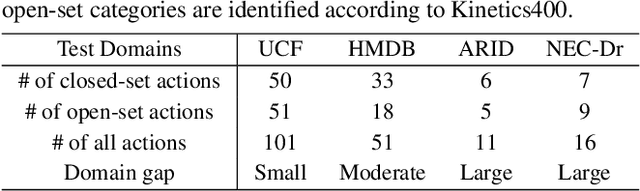
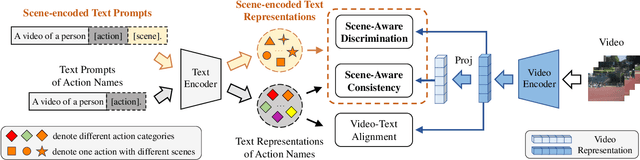
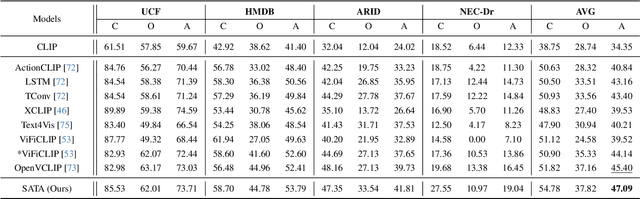
Contrastive Language-Image Pretraining (CLIP) has shown remarkable open-vocabulary abilities across various image understanding tasks. Building upon this impressive success, recent pioneer works have proposed to adapt the powerful CLIP to video data, leading to efficient and effective video learners for open-vocabulary action recognition. Inspired by the fact that humans perform actions in diverse environments, our work delves into an intriguing question: Can CLIP-based video learners effectively generalize to video domains they have not encountered during training? To answer this, we establish a CROSS-domain Open-Vocabulary Action recognition benchmark named XOV-Action, and conduct a comprehensive evaluation of five state-of-the-art CLIP-based video learners under various types of domain gaps. Our evaluation demonstrates that previous methods exhibit limited action recognition performance in unseen video domains, revealing potential challenges of the cross-domain open-vocabulary action recognition task. To address this task, our work focuses on a critical challenge, namely scene bias, and we accordingly contribute a novel scene-aware video-text alignment method. Our key idea is to distinguish video representations apart from scene-encoded text representations, aiming to learn scene-agnostic video representations for recognizing actions across domains. Extensive experimental results demonstrate the effectiveness of our method. The benchmark and code will be available at https://github.com/KunyuLin/XOV-Action/.
When Prompt-based Incremental Learning Does Not Meet Strong Pretraining
Aug 21, 2023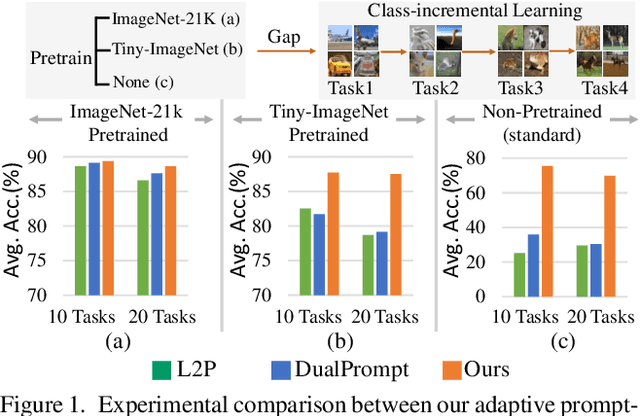

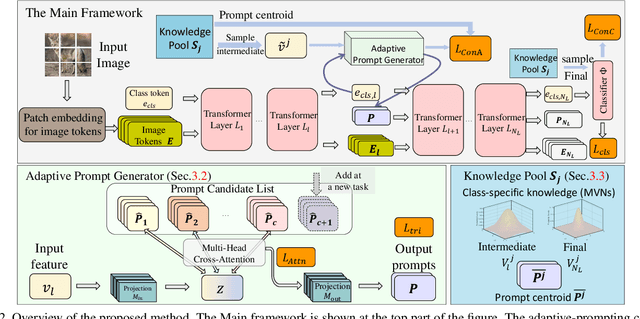
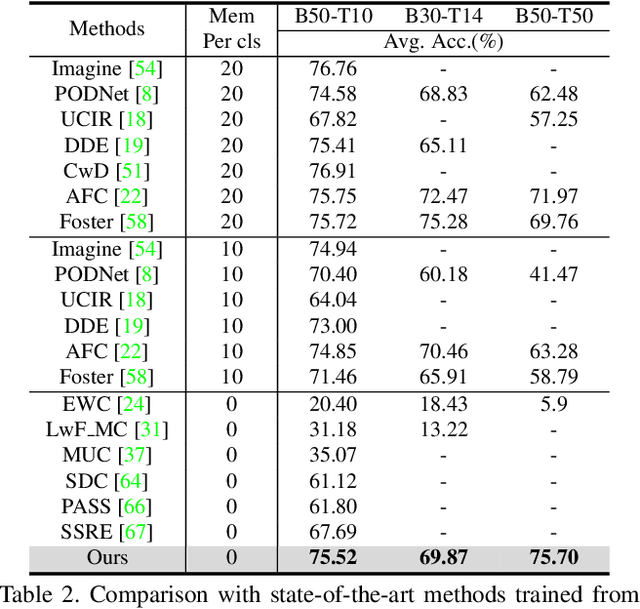
Incremental learning aims to overcome catastrophic forgetting when learning deep networks from sequential tasks. With impressive learning efficiency and performance, prompt-based methods adopt a fixed backbone to sequential tasks by learning task-specific prompts. However, existing prompt-based methods heavily rely on strong pretraining (typically trained on ImageNet-21k), and we find that their models could be trapped if the potential gap between the pretraining task and unknown future tasks is large. In this work, we develop a learnable Adaptive Prompt Generator (APG). The key is to unify the prompt retrieval and prompt learning processes into a learnable prompt generator. Hence, the whole prompting process can be optimized to reduce the negative effects of the gap between tasks effectively. To make our APG avoid learning ineffective knowledge, we maintain a knowledge pool to regularize APG with the feature distribution of each class. Extensive experiments show that our method significantly outperforms advanced methods in exemplar-free incremental learning without (strong) pretraining. Besides, under strong retraining, our method also has comparable performance to existing prompt-based models, showing that our method can still benefit from pretraining. Codes can be found at https://github.com/TOM-tym/APG
Learning to Imagine: Diversify Memory for Incremental Learning using Unlabeled Data
Apr 19, 2022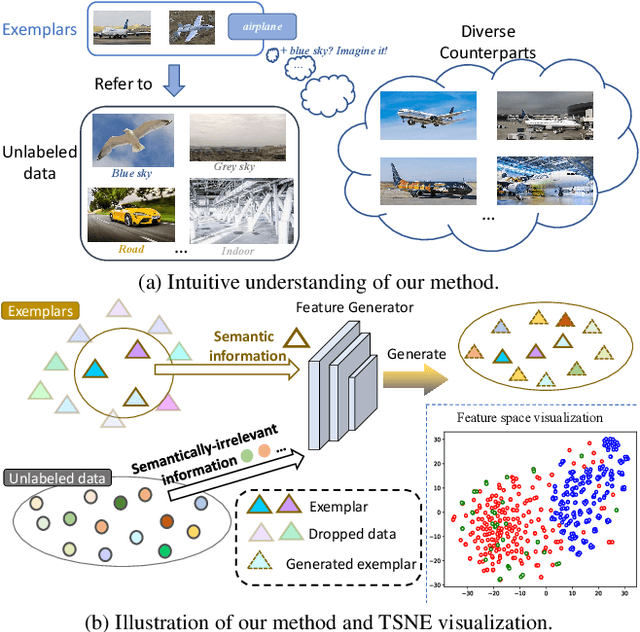
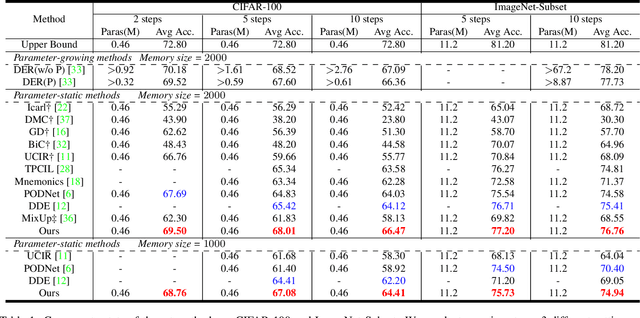
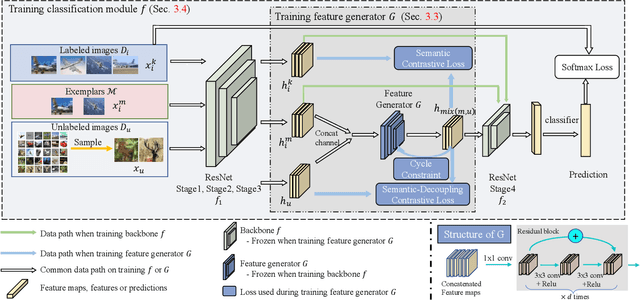
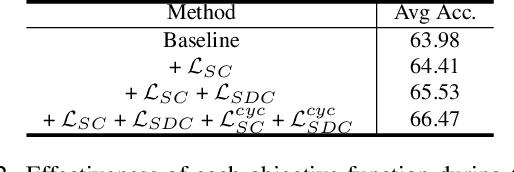
Deep neural network (DNN) suffers from catastrophic forgetting when learning incrementally, which greatly limits its applications. Although maintaining a handful of samples (called `exemplars`) of each task could alleviate forgetting to some extent, existing methods are still limited by the small number of exemplars since these exemplars are too few to carry enough task-specific knowledge, and therefore the forgetting remains. To overcome this problem, we propose to `imagine` diverse counterparts of given exemplars referring to the abundant semantic-irrelevant information from unlabeled data. Specifically, we develop a learnable feature generator to diversify exemplars by adaptively generating diverse counterparts of exemplars based on semantic information from exemplars and semantically-irrelevant information from unlabeled data. We introduce semantic contrastive learning to enforce the generated samples to be semantic consistent with exemplars and perform semanticdecoupling contrastive learning to encourage diversity of generated samples. The diverse generated samples could effectively prevent DNN from forgetting when learning new tasks. Our method does not bring any extra inference cost and outperforms state-of-the-art methods on two benchmarks CIFAR-100 and ImageNet-Subset by a clear margin.