 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoGenAV: Versatile Audio-Visual Representation Learning via Contrastive-Generative Synchronization
May 06, 2025The inherent synchronization between a speaker's lip movements, voice, and the underlying linguistic content offers a rich source of information for improving speech processing tasks, especially in challenging conditions where traditional audio-only systems falter. We introduce CoGenAV, a powerful and data-efficient model designed to learn versatile audio-visual representations applicable across a wide range of speech and audio-visual tasks. CoGenAV is trained by optimizing a dual objective derived from natural audio-visual synchrony, contrastive feature alignment and generative text prediction, using only 223 hours of labeled data from the LRS2 dataset. This contrastive-generative synchronization strategy effectively captures fundamental cross-modal correlations. We showcase the effectiveness and versatility of the learned CoGenAV representations on multiple benchmarks. When utilized for Audio-Visual Speech Recognition (AVSR) on LRS2, these representations contribute to achieving a state-of-the-art Word Error Rate (WER) of 1.27. They also enable strong performance in Visual Speech Recognition (VSR) with a WER of 22.0 on LRS2, and significantly improve performance in noisy environments by over 70%. Furthermore, CoGenAV representations benefit speech reconstruction tasks, boosting performance in Speech Enhancement and Separation, and achieve competitive results in audio-visual synchronization tasks like Active Speaker Detection (ASD). Our model will be open-sourced to facilitate further development and collaboration within both academia and industry.
HumanOmni: A Large Vision-Speech Language Model for Human-Centric Video Understanding
Jan 25, 2025



In human-centric scenes, the ability to simultaneously understand visual and auditory information is crucial. While recent omni models can process multiple modalities, they generally lack effectiveness in human-centric scenes due to the absence of large-scale, specialized datasets and non-targeted architectures. In this work, we developed HumanOmni, the industry's first human-centric Omni-multimodal large language model. We constructed a dataset containing over 2.4 million human-centric video clips with detailed captions and more than 14 million instructions, facilitating the understanding of diverse human-centric scenes. HumanOmni includes three specialized branches for understanding different types of scenes. It adaptively fuses features from these branches based on user instructions, significantly enhancing visual understanding in scenes centered around individuals. Moreover, HumanOmni integrates audio features to ensure a comprehensive understanding of environments and individuals. Our experiments validate HumanOmni's advanced capabilities in handling human-centric scenes across a variety of tasks, including emotion recognition, facial expression description, and action understanding. Our model will be open-sourced to facilitate further development and collaboration within both academia and industry.
Omni-Emotion: Extending Video MLLM with Detailed Face and Audio Modeling for Multimodal Emotion Analysis
Jan 16, 2025
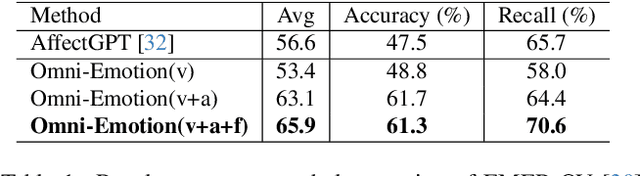
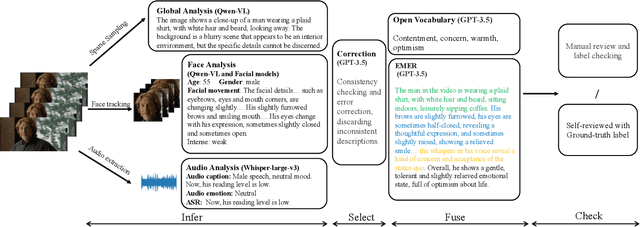
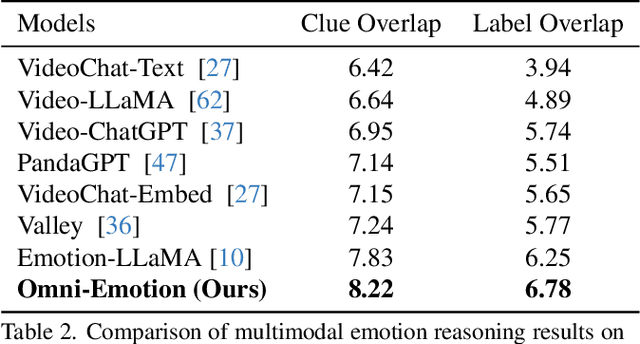
Understanding emotions accurately is essential for fields like human-computer interaction. Due to the complexity of emotions and their multi-modal nature (e.g., emotions are influenced by facial expressions and audio), researchers have turned to using multi-modal models to understand human emotions rather than single-modality. However, current video multi-modal large language models (MLLMs) encounter difficulties in effectively integrating audio and identifying subtle facial micro-expressions. Furthermore, the lack of detailed emotion analysis datasets also limits the development of multimodal emotion analysis. To address these issues, we introduce a self-reviewed dataset and a human-reviewed dataset, comprising 24,137 coarse-grained samples and 3,500 manually annotated samples with detailed emotion annotations, respectively. These datasets allow models to learn from diverse scenarios and better generalize to real-world applications. Moreover, in addition to the audio modeling, we propose to explicitly integrate facial encoding models into the existing advanced Video MLLM, enabling the MLLM to effectively unify audio and the subtle facial cues for emotion understanding. By aligning these features within a unified space and employing instruction tuning in our proposed datasets, our Omni-Emotion achieves state-of-the-art performance in both emotion recognition and reasoning tasks.