 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition
Paper and Code
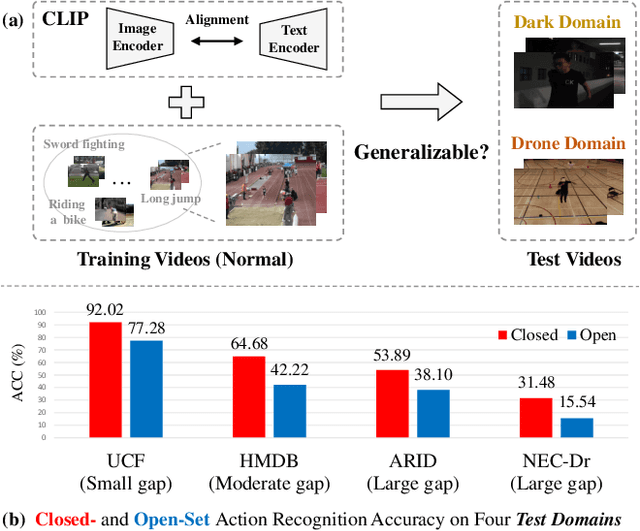
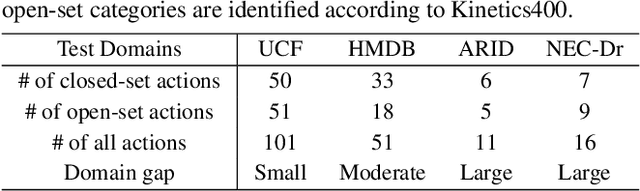
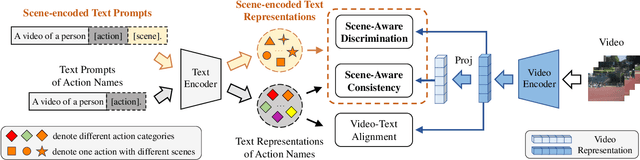
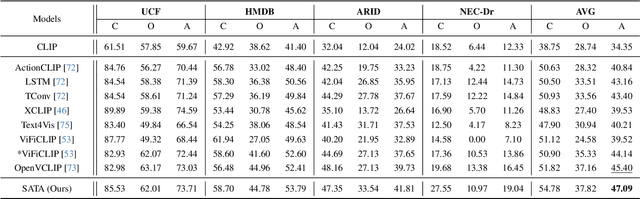
Contrastive Language-Image Pretraining (CLIP) has shown remarkable open-vocabulary abilities across various image understanding tasks. Building upon this impressive success, recent pioneer works have proposed to adapt the powerful CLIP to video data, leading to efficient and effective video learners for open-vocabulary action recognition. Inspired by the fact that humans perform actions in diverse environments, our work delves into an intriguing question: Can CLIP-based video learners effectively generalize to video domains they have not encountered during training? To answer this, we establish a CROSS-domain Open-Vocabulary Action recognition benchmark named XOV-Action, and conduct a comprehensive evaluation of five state-of-the-art CLIP-based video learners under various types of domain gaps. Our evaluation demonstrates that previous methods exhibit limited action recognition performance in unseen video domains, revealing potential challenges of the cross-domain open-vocabulary action recognition task. To address this task, our work focuses on a critical challenge, namely scene bias, and we accordingly contribute a novel scene-aware video-text alignment method. Our key idea is to distinguish video representations apart from scene-encoded text representations, aiming to learn scene-agnostic video representations for recognizing actions across domains. Extensive experimental results demonstrate the effectiveness of our method. The benchmark and code will be available at https://github.com/KunyuLin/XOV-Action/.