 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Text-to-Image Generation Alignment via Attention Modulation
Apr 22, 2024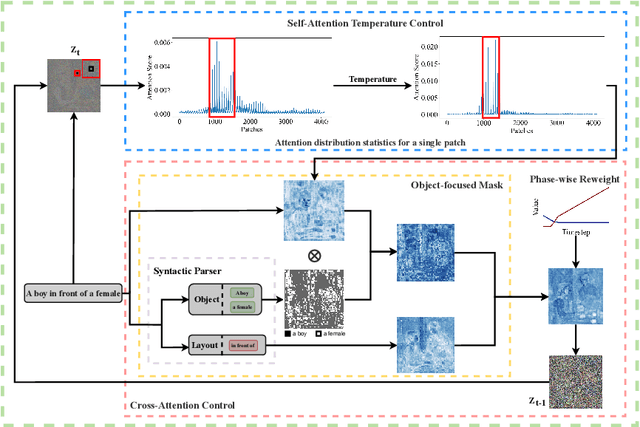
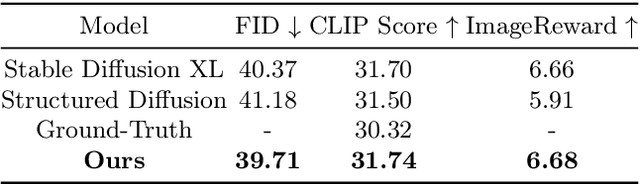

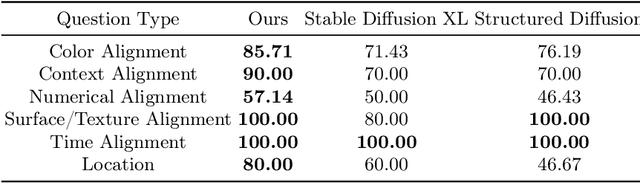
In text-to-image generation tasks, the advancements of diffusion models have facilitated the fidelity of generated results. However, these models encounter challenges when processing text prompts containing multiple entities and attributes. The uneven distribution of attention results in the issues of entity leakage and attribute misalignment. Training from scratch to address this issue requires numerous labeled data and is resource-consuming. Motivated by this, we propose an attribution-focusing mechanism, a training-free phase-wise mechanism by modulation of attention for diffusion model. One of our core ideas is to guide the model to concentrate on the corresponding syntactic components of the prompt at distinct timesteps. To achieve this, we incorporate a temperature control mechanism within the early phases of the self-attention modules to mitigate entity leakage issues. An object-focused masking scheme and a phase-wise dynamic weight control mechanism are integrated into the cross-attention modules, enabling the model to discern the affiliation of semantic information between entities more effectively. The experimental results in various alignment scenarios demonstrate that our model attain better image-text alignment with minimal additional computational cost.
Class-level Structural Relation Modelling and Smoothing for Visual Representation Learning
Aug 08, 2023



Representation learning for images has been advanced by recent progress in more complex neural models such as the Vision Transformers and new learning theories such as the structural causal models. However, these models mainly rely on the classification loss to implicitly regularize the class-level data distributions, and they may face difficulties when handling classes with diverse visual patterns. We argue that the incorporation of the structural information between data samples may improve this situation. To achieve this goal, this paper presents a framework termed \textbf{C}lass-level Structural Relation Modeling and Smoothing for Visual Representation Learning (CSRMS), which includes the Class-level Relation Modelling, Class-aware Graph Sampling, and Relational Graph-Guided Representation Learning modules to model a relational graph of the entire dataset and perform class-aware smoothing and regularization operations to alleviate the issue of intra-class visual diversity and inter-class similarity. Specifically, the Class-level Relation Modelling module uses a clustering algorithm to learn the data distributions in the feature space and identify three types of class-level sample relations for the training set; Class-aware Graph Sampling module extends typical training batch construction process with three strategies to sample dataset-level sub-graphs; and Relational Graph-Guided Representation Learning module employs a graph convolution network with knowledge-guided smoothing operations to ease the projection from different visual patterns to the same class. Experiments demonstrate the effectiveness of structured knowledge modelling for enhanced representation learning and show that CSRMS can be incorporated with any state-of-the-art visual representation learning models for performance gains. The source codes and demos have been released at https://github.com/czt117/CSRMS.
Cross-Silo Prototypical Calibration for Federated Learning with Non-IID Data
Aug 07, 2023Federated Learning aims to learn a global model on the server side that generalizes to all clients in a privacy-preserving manner, by leveraging the local models from different clients. Existing solutions focus on either regularizing the objective functions among clients or improving the aggregation mechanism for the improved model generalization capability. However, their performance is typically limited by the dataset biases, such as the heterogeneous data distributions and the missing classes. To address this issue, this paper presents a cross-silo prototypical calibration method (FedCSPC), which takes additional prototype information from the clients to learn a unified feature space on the server side. Specifically, FedCSPC first employs the Data Prototypical Modeling (DPM) module to learn data patterns via clustering to aid calibration. Subsequently, the cross-silo prototypical calibration (CSPC) module develops an augmented contrastive learning method to improve the robustness of the calibration, which can effectively project cross-source features into a consistent space while maintaining clear decision boundaries. Moreover, the CSPC module's ease of implementation and plug-and-play characteristics make it even more remarkable. Experiments were conducted on four datasets in terms of performance comparison, ablation study, in-depth analysis and case study, and the results verified that FedCSPC is capable of learning the consistent features across different data sources of the same class under the guidance of calibrated model, which leads to better performance than the state-of-the-art methods. The source codes have been released at https://github.com/qizhuang-qz/FedCSPC.
Multi-modal Video Chapter Generation
Sep 26, 2022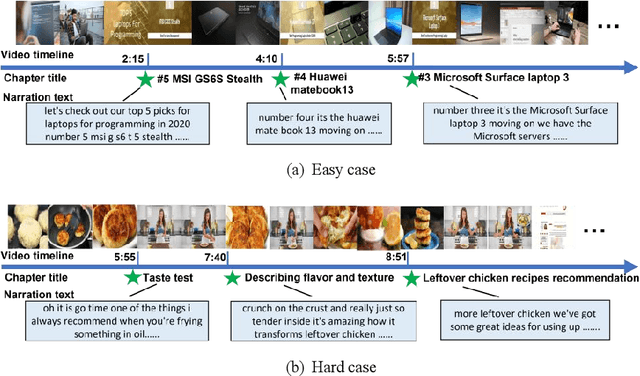
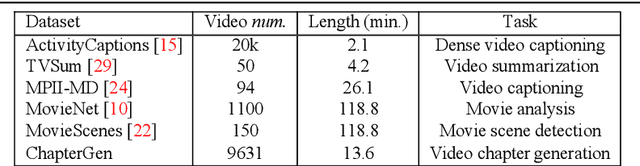
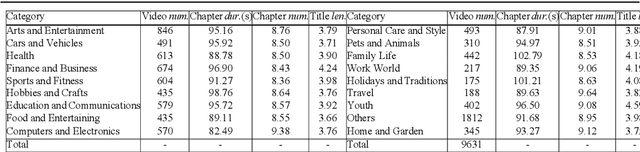
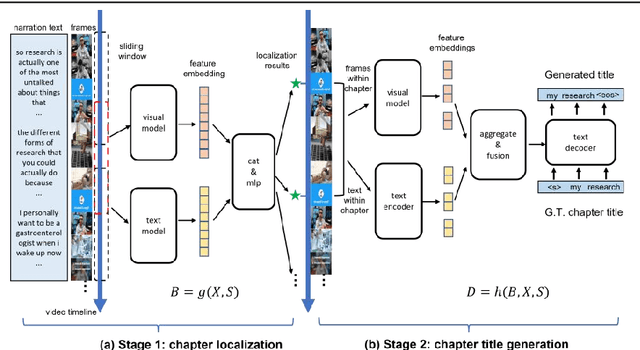
Chapter generation becomes practical technique for online videos nowadays. The chapter breakpoints enable users to quickly find the parts they want and get the summative annotations. However, there is no public method and dataset for this task. To facilitate the research along this direction, we introduce a new dataset called Chapter-Gen, which consists of approximately 10k user-generated videos with annotated chapter information. Our data collection procedure is fast, scalable and does not require any additional manual annotation. On top of this dataset, we design an effective baseline specificlly for video chapters generation task. which captures two aspects of a video,including visual dynamics and narration text. It disentangles local and global video features for localization and title generation respectively. To parse the long video efficiently, a skip sliding window mechanism is designed to localize potential chapters. And a cross attention multi-modal fusion module is developed to aggregate local features for title generation. Our experiments demonstrate that the proposed framework achieves superior results over existing methods which illustrate that the method design for similar task cannot be transfered directly even after fine-tuning. Code and dataset are available at https://github.com/czt117/MVCG.