 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
Mar 25, 2026Computer-use agents (CUAs) hold great promise for automating complex desktop workflows, yet progress toward general-purpose agents is bottlenecked by the scarcity of continuous, high-quality human demonstration videos. Recent work emphasizes that continuous video, not sparse screenshots, is the critical missing ingredient for scaling these agents. However, the largest existing open dataset, ScaleCUA, contains only 2 million screenshots, equating to less than 20 hours of video. To address this bottleneck, we introduce CUA-Suite, a large-scale ecosystem of expert video demonstrations and dense annotations for professional desktop computer-use agents. At its core is VideoCUA, which provides approximately 10,000 human-demonstrated tasks across 87 diverse applications with continuous 30 fps screen recordings, kinematic cursor traces, and multi-layerfed reasoning annotations, totaling approximately 55 hours and 6 million frames of expert video. Unlike sparse datasets that capture only final click coordinates, these continuous video streams preserve the full temporal dynamics of human interaction, forming a superset of information that can be losslessly transformed into the formats required by existing agent frameworks. CUA-Suite further provides two complementary resources: UI-Vision, a rigorous benchmark for evaluating grounding and planning capabilities in CUAs, and GroundCUA, a large-scale grounding dataset with 56K annotated screenshots and over 3.6 million UI element annotations. Preliminary evaluation reveals that current foundation action models struggle substantially with professional desktop applications (~60% task failure rate). Beyond evaluation, CUA-Suite's rich multimodal corpus supports emerging research directions including generalist screen parsing, continuous spatial control, video-based reward modeling, and visual world models. All data and models are publicly released.
Towards Principled Dataset Distillation: A Spectral Distribution Perspective
Mar 02, 2026Dataset distillation (DD) aims to compress large-scale datasets into compact synthetic counterparts for efficient model training. However, existing DD methods exhibit substantial performance degradation on long-tailed datasets. We identify two fundamental challenges: heuristic design choices for distribution discrepancy measure and uniform treatment of imbalanced classes. To address these limitations, we propose Class-Aware Spectral Distribution Matching (CSDM), which reformulates distribution alignment via the spectrum of a well-behaved kernel function. This technique maps the original samples into frequency space, resulting in the Spectral Distribution Distance (SDD). To mitigate class imbalance, we exploit the unified form of SDD to perform amplitude-phase decomposition, which adaptively prioritizes the realism in tail classes. On CIFAR-10-LT, with 10 images per class, CSDM achieves a 14.0% improvement over state-of-the-art DD methods, with only a 5.7% performance drop when the number of images in tail classes decreases from 500 to 25, demonstrating strong stability on long-tailed data.
Qwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
Grounding and Enhancing Informativeness and Utility in Dataset Distillation
Jan 29, 2026Dataset Distillation (DD) seeks to create a compact dataset from a large, real-world dataset. While recent methods often rely on heuristic approaches to balance efficiency and quality, the fundamental relationship between original and synthetic data remains underexplored. This paper revisits knowledge distillation-based dataset distillation within a solid theoretical framework. We introduce the concepts of Informativeness and Utility, capturing crucial information within a sample and essential samples in the training set, respectively. Building on these principles, we define optimal dataset distillation mathematically. We then present InfoUtil, a framework that balances informativeness and utility in synthesizing the distilled dataset. InfoUtil incorporates two key components: (1) game-theoretic informativeness maximization using Shapley Value attribution to extract key information from samples, and (2) principled utility maximization by selecting globally influential samples based on Gradient Norm. These components ensure that the distilled dataset is both informative and utility-optimized. Experiments demonstrate that our method achieves a 6.1\% performance improvement over the previous state-of-the-art approach on ImageNet-1K dataset using ResNet-18.
CrownGen: Patient-customized Crown Generation via Point Diffusion Model
Dec 26, 2025



Digital crown design remains a labor-intensive bottleneck in restorative dentistry. We present \textbf{CrownGen}, a generative framework that automates patient-customized crown design using a denoising diffusion model on a novel tooth-level point cloud representation. The system employs two core components: a boundary prediction module to establish spatial priors and a diffusion-based generative module to synthesize high-fidelity morphology for multiple teeth in a single inference pass. We validated CrownGen through a quantitative benchmark on 496 external scans and a clinical study of 26 restoration cases. Results demonstrate that CrownGen surpasses state-of-the-art models in geometric fidelity and significantly reduces active design time. Clinical assessments by trained dentists confirmed that CrownGen-assisted crowns are statistically non-inferior in quality to those produced by expert technicians using manual workflows. By automating complex prosthetic modeling, CrownGen offers a scalable solution to lower costs, shorten turnaround times, and enhance patient access to high-quality dental care.
MM-CRITIC: A Holistic Evaluation of Large Multimodal Models as Multimodal Critique
Nov 12, 2025



The ability of critique is vital for models to self-improve and serve as reliable AI assistants. While extensively studied in language-only settings, multimodal critique of Large Multimodal Models (LMMs) remains underexplored despite their growing capabilities in tasks like captioning and visual reasoning. In this work, we introduce MM-CRITIC, a holistic benchmark for evaluating the critique ability of LMMs across multiple dimensions: basic, correction, and comparison. Covering 8 main task types and over 500 tasks, MM-CRITIC collects responses from various LMMs with different model sizes and is composed of 4471 samples. To enhance the evaluation reliability, we integrate expert-informed ground answers into scoring rubrics that guide GPT-4o in annotating responses and generating reference critiques, which serve as anchors for trustworthy judgments. Extensive experiments validate the effectiveness of MM-CRITIC and provide a comprehensive assessment of leading LMMs' critique capabilities under multiple dimensions. Further analysis reveals some key insights, including the correlation between response quality and critique, and varying critique difficulty across evaluation dimensions. Our code is available at https://github.com/MichealZeng0420/MM-Critic.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
MemeArena: Automating Context-Aware Unbiased Evaluation of Harmfulness Understanding for Multimodal Large Language Models
Oct 31, 2025The proliferation of memes on social media necessitates the capabilities of multimodal Large Language Models (mLLMs) to effectively understand multimodal harmfulness. Existing evaluation approaches predominantly focus on mLLMs' detection accuracy for binary classification tasks, which often fail to reflect the in-depth interpretive nuance of harmfulness across diverse contexts. In this paper, we propose MemeArena, an agent-based arena-style evaluation framework that provides a context-aware and unbiased assessment for mLLMs' understanding of multimodal harmfulness. Specifically, MemeArena simulates diverse interpretive contexts to formulate evaluation tasks that elicit perspective-specific analyses from mLLMs. By integrating varied viewpoints and reaching consensus among evaluators, it enables fair and unbiased comparisons of mLLMs' abilities to interpret multimodal harmfulness. Extensive experiments demonstrate that our framework effectively reduces the evaluation biases of judge agents, with judgment results closely aligning with human preferences, offering valuable insights into reliable and comprehensive mLLM evaluations in multimodal harmfulness understanding. Our code and data are publicly available at https://github.com/Lbotirx/MemeArena.
AdamMeme: Adaptively Probe the Reasoning Capacity of Multimodal Large Language Models on Harmfulness
Jul 02, 2025The proliferation of multimodal memes in the social media era demands that multimodal Large Language Models (mLLMs) effectively understand meme harmfulness. Existing benchmarks for assessing mLLMs on harmful meme understanding rely on accuracy-based, model-agnostic evaluations using static datasets. These benchmarks are limited in their ability to provide up-to-date and thorough assessments, as online memes evolve dynamically. To address this, we propose AdamMeme, a flexible, agent-based evaluation framework that adaptively probes the reasoning capabilities of mLLMs in deciphering meme harmfulness. Through multi-agent collaboration, AdamMeme provides comprehensive evaluations by iteratively updating the meme data with challenging samples, thereby exposing specific limitations in how mLLMs interpret harmfulness. Extensive experiments show that our framework systematically reveals the varying performance of different target mLLMs, offering in-depth, fine-grained analyses of model-specific weaknesses. Our code is available at https://github.com/Lbotirx/AdamMeme.
Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning
May 18, 2025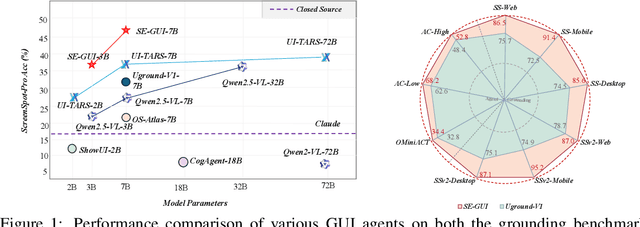
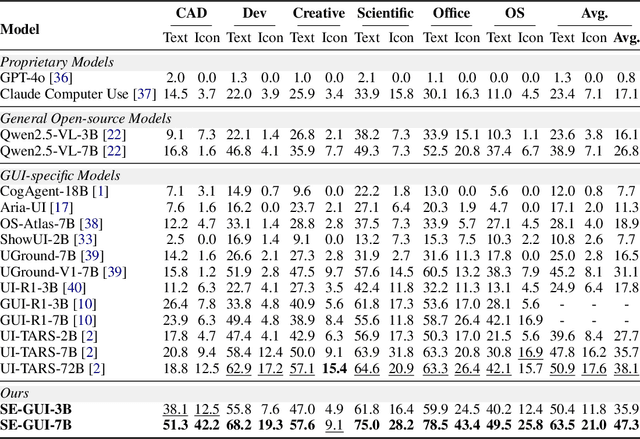
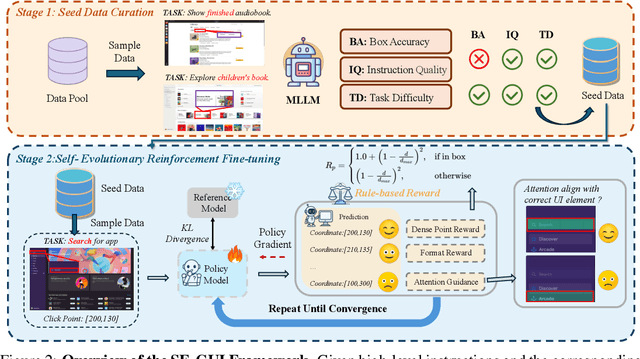
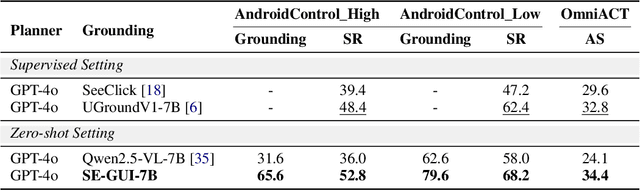
Graphical User Interface (GUI) agents have made substantial strides in understanding and executing user instructions across diverse platforms. Yet, grounding these instructions to precise interface elements remains challenging, especially in complex, high-resolution, professional environments. Traditional supervised finetuning (SFT) methods often require large volumes of diverse data and exhibit weak generalization. To overcome these limitations, we introduce a reinforcement learning (RL) based framework that incorporates three core strategies: (1) seed data curation to ensure high quality training samples, (2) a dense policy gradient that provides continuous feedback based on prediction accuracy, and (3) a self evolutionary reinforcement finetuning mechanism that iteratively refines the model using attention maps. With only 3k training samples, our 7B-parameter model achieves state-of-the-art results among similarly sized models on three grounding benchmarks. Notably, it attains 47.3\% accuracy on the ScreenSpot-Pro dataset, outperforming much larger models, such as UI-TARS-72B, by a margin of 24.2\%. These findings underscore the effectiveness of RL-based approaches in enhancing GUI agent performance, particularly in high-resolution, complex environments.