 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding and Enhancing Informativeness and Utility in Dataset Distillation
Jan 29, 2026Dataset Distillation (DD) seeks to create a compact dataset from a large, real-world dataset. While recent methods often rely on heuristic approaches to balance efficiency and quality, the fundamental relationship between original and synthetic data remains underexplored. This paper revisits knowledge distillation-based dataset distillation within a solid theoretical framework. We introduce the concepts of Informativeness and Utility, capturing crucial information within a sample and essential samples in the training set, respectively. Building on these principles, we define optimal dataset distillation mathematically. We then present InfoUtil, a framework that balances informativeness and utility in synthesizing the distilled dataset. InfoUtil incorporates two key components: (1) game-theoretic informativeness maximization using Shapley Value attribution to extract key information from samples, and (2) principled utility maximization by selecting globally influential samples based on Gradient Norm. These components ensure that the distilled dataset is both informative and utility-optimized. Experiments demonstrate that our method achieves a 6.1\% performance improvement over the previous state-of-the-art approach on ImageNet-1K dataset using ResNet-18.
Numerical Pruning for Efficient Autoregressive Models
Dec 17, 2024



Transformers have emerged as the leading architecture in deep learning, proving to be versatile and highly effective across diverse domains beyond language and image processing. However, their impressive performance often incurs high computational costs due to their substantial model size. This paper focuses on compressing decoder-only transformer-based autoregressive models through structural weight pruning to improve the model efficiency while preserving performance for both language and image generation tasks. Specifically, we propose a training-free pruning method that calculates a numerical score with Newton's method for the Attention and MLP modules, respectively. Besides, we further propose another compensation algorithm to recover the pruned model for better performance. To verify the effectiveness of our method, we provide both theoretical support and extensive experiments. Our experiments show that our method achieves state-of-the-art performance with reduced memory usage and faster generation speeds on GPUs.
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Dec 17, 2024Diffusion Transformers have emerged as the preeminent models for a wide array of generative tasks, demonstrating superior performance and efficacy across various applications. The promising results come at the cost of slow inference, as each denoising step requires running the whole transformer model with a large amount of parameters. In this paper, we show that performing the full computation of the model at each diffusion step is unnecessary, as some computations can be skipped by lazily reusing the results of previous steps. Furthermore, we show that the lower bound of similarity between outputs at consecutive steps is notably high, and this similarity can be linearly approximated using the inputs. To verify our demonstrations, we propose the \textbf{LazyDiT}, a lazy learning framework that efficiently leverages cached results from earlier steps to skip redundant computations. Specifically, we incorporate lazy learning layers into the model, effectively trained to maximize laziness, enabling dynamic skipping of redundant computations. Experimental results show that LazyDiT outperforms the DDIM sampler across multiple diffusion transformer models at various resolutions. Furthermore, we implement our method on mobile devices, achieving better performance than DDIM with similar latency.
Beyond Linear Approximations: A Novel Pruning Approach for Attention Matrix
Oct 15, 2024
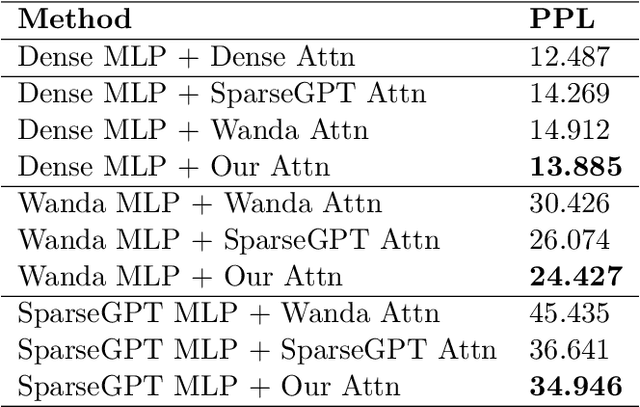


Large Language Models (LLMs) have shown immense potential in enhancing various aspects of our daily lives, from conversational AI to search and AI assistants. However, their growing capabilities come at the cost of extremely large model sizes, making deployment on edge devices challenging due to memory and computational constraints. This paper introduces a novel approach to LLM weight pruning that directly optimizes for approximating the attention matrix, a core component of transformer architectures. Unlike existing methods that focus on linear approximations, our approach accounts for the non-linear nature of the Softmax attention mechanism. We provide theoretical guarantees for the convergence of our Gradient Descent-based optimization method to a near-optimal pruning mask solution. Our preliminary empirical results demonstrate the effectiveness of this approach in maintaining model performance while significantly reducing computational costs. This work establishes a new theoretical foundation for pruning algorithm design in LLMs, potentially paving the way for more efficient LLM inference on resource-constrained devices.
Fine-grained Attention I/O Complexity: Comprehensive Analysis for Backward Passes
Oct 12, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities in processing long-context information. However, the quadratic complexity of attention computation with respect to sequence length poses significant computational challenges, and I/O aware algorithms have been proposed. This paper presents a comprehensive analysis of the I/O complexity for attention mechanisms, focusing on backward passes by categorizing into small and large cache scenarios. Using the red-blue pebble game framework, we establish tight bounds on I/O complexity across all cache sizes. We confirm that the de facto standard I/O aware algorithm FlashAttention is optimal for both forward and backward passes for the large cache size scenario. For small cache sizes, we provide an algorithm that improves over existing methods and achieves the tight bounds. Additionally, we extend our analysis to sparse attention, a mainstream speeding-up approach, deriving fine-grained lower bounds for both forward and backward passes and both small and large caches. Our findings complete the theoretical foundation for I/O complexity in attention mechanisms, offering insights for designing efficient algorithms of LLM training and inference.
Looped ReLU MLPs May Be All You Need as Practical Programmable Computers
Oct 12, 2024Previous work has demonstrated that attention mechanisms are Turing complete. More recently, it has been shown that a looped 13-layer Transformer can function as a universal programmable computer. In contrast, the multi-layer perceptrons with $\mathsf{ReLU}$ activation ($\mathsf{ReLU}$-$\mathsf{MLP}$), one of the most fundamental components of neural networks, is known to be expressive; specifically, a two-layer neural network is a universal approximator given an exponentially large number of hidden neurons. However, it remains unclear whether a $\mathsf{ReLU}$-$\mathsf{MLP}$ can be made into a universal programmable computer using a practical number of weights. In this work, we provide an affirmative answer that a looped 23-layer $\mathsf{ReLU}$-$\mathsf{MLP}$ is capable to perform the basic necessary operations, effectively functioning as a programmable computer. This indicates that simple modules have stronger expressive power than previously expected and have not been fully explored. Our work provides insights into the mechanisms of neural networks and demonstrates that complex tasks, such as functioning as a programmable computer, do not necessarily require advanced architectures like Transformers.
Multi-Layer Transformers Gradient Can be Approximated in Almost Linear Time
Aug 23, 2024The quadratic computational complexity in the self-attention mechanism of popular transformer architectures poses significant challenges for training and inference, particularly in terms of efficiency and memory requirements. Towards addressing these challenges, this paper introduces a novel fast computation method for gradient calculation in multi-layer transformer models. Our approach enables the computation of gradients for the entire multi-layer transformer model in almost linear time $n^{1+o(1)}$, where $n$ is the input sequence length. This breakthrough significantly reduces the computational bottleneck associated with the traditional quadratic time complexity. Our theory holds for any loss function and maintains a bounded approximation error across the entire model. Furthermore, our analysis can hold when the multi-layer transformer model contains many practical sub-modules, such as residual connection, casual mask, and multi-head attention. By improving the efficiency of gradient computation in large language models, we hope that our work will facilitate the more effective training and deployment of long-context language models based on our theoretical results.
Differential Privacy of Cross-Attention with Provable Guarantee
Jul 20, 2024
Cross-attention has become a fundamental module nowadays in many important artificial intelligence applications, e.g., retrieval-augmented generation (RAG), system prompt, guided stable diffusion, and many so on. Ensuring cross-attention privacy is crucial and urgently needed because its key and value matrices may contain sensitive information about companies and their users, many of which profit solely from their system prompts or RAG data. In this work, we design a novel differential privacy (DP) data structure to address the privacy security of cross-attention with a theoretical guarantee. In detail, let $n$ be the input token length of system prompt/RAG data, $d$ be the feature dimension, $0 < \alpha \le 1$ be the relative error parameter, $R$ be the maximum value of the query and key matrices, $R_w$ be the maximum value of the value matrix, and $r,s,\epsilon_s$ be parameters of polynomial kernel methods. Then, our data structure requires $\widetilde{O}(ndr^2)$ memory consumption with $\widetilde{O}(nr^2)$ initialization time complexity and $\widetilde{O}(\alpha^{-1} r^2)$ query time complexity for a single token query. In addition, our data structure can guarantee that the user query is $(\epsilon, \delta)$-DP with $\widetilde{O}(n^{-1} \epsilon^{-1} \alpha^{-1/2} R^{2s} R_w r^2)$ additive error and $n^{-1} (\alpha + \epsilon_s)$ relative error between our output and the true answer. Furthermore, our result is robust to adaptive queries in which users can intentionally attack the cross-attention system. To our knowledge, this is the first work to provide DP for cross-attention. We believe it can inspire more privacy algorithm design in large generative models (LGMs).
Tensor Attention Training: Provably Efficient Learning of Higher-order Transformers
May 26, 2024


Tensor Attention, a multi-view attention that is able to capture high-order correlations among multiple modalities, can overcome the representational limitations of classical matrix attention. However, the $\Omega(n^3)$ time complexity of tensor attention poses a significant obstacle to its practical implementation in transformers, where $n$ is the input sequence length. In this work, we prove that the backward gradient of tensor attention training can be computed in almost linear $n^{1+o(1)}$ time, the same complexity as its forward computation under a bounded entries assumption. We provide a closed-form solution for the gradient and propose a fast computation method utilizing polynomial approximation methods and tensor algebraic tricks. Furthermore, we prove the necessity and tightness of our assumption through hardness analysis, showing that slightly weakening it renders the gradient problem unsolvable in truly subcubic time. Our theoretical results establish the feasibility of efficient higher-order transformer training and may facilitate practical applications of tensor attention architectures.
Unraveling the Smoothness Properties of Diffusion Models: A Gaussian Mixture Perspective
May 26, 2024Diffusion models have made rapid progress in generating high-quality samples across various domains. However, a theoretical understanding of the Lipschitz continuity and second momentum properties of the diffusion process is still lacking. In this paper, we bridge this gap by providing a detailed examination of these smoothness properties for the case where the target data distribution is a mixture of Gaussians, which serves as a universal approximator for smooth densities such as image data. We prove that if the target distribution is a $k$-mixture of Gaussians, the density of the entire diffusion process will also be a $k$-mixture of Gaussians. We then derive tight upper bounds on the Lipschitz constant and second momentum that are independent of the number of mixture components $k$. Finally, we apply our analysis to various diffusion solvers, both SDE and ODE based, to establish concrete error guarantees in terms of the total variation distance and KL divergence between the target and learned distributions. Our results provide deeper theoretical insights into the dynamics of the diffusion process under common data distributions.