 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning
May 30, 2025Recent advances in model distillation demonstrate that data from advanced reasoning models (e.g., DeepSeek-R1, OpenAI's o1) can effectively transfer complex reasoning abilities to smaller, efficient student models. However, standard practices employ rejection sampling, discarding incorrect reasoning examples -- valuable, yet often underutilized data. This paper addresses the critical question: How can both positive and negative distilled reasoning traces be effectively leveraged to maximize LLM reasoning performance in an offline setting? To this end, We propose Reinforcement Distillation (REDI), a two-stage framework. Stage 1 learns from positive traces via Supervised Fine-Tuning (SFT). Stage 2 further refines the model using both positive and negative traces through our proposed REDI objective. This novel objective is a simple, reference-free loss function that outperforms established methods like DPO and SimPO in this distillation context. Our empirical evaluations demonstrate REDI's superiority over baseline Rejection Sampling SFT or SFT combined with DPO/SimPO on mathematical reasoning tasks. Notably, the Qwen-REDI-1.5B model, post-trained on just 131k positive and negative examples from the open Open-R1 dataset, achieves an 83.1% score on MATH-500 (pass@1). Its performance matches or surpasses that of DeepSeek-R1-Distill-Qwen-1.5B (a model post-trained on 800k proprietary data) across various mathematical reasoning benchmarks, establishing a new state-of-the-art for 1.5B models post-trained offline with openly available data.
Theoretical Foundation of Flow-Based Time Series Generation: Provable Approximation, Generalization, and Efficiency
Mar 18, 2025Recent studies suggest utilizing generative models instead of traditional auto-regressive algorithms for time series forecasting (TSF) tasks. These non-auto-regressive approaches involving different generative methods, including GAN, Diffusion, and Flow Matching for time series, have empirically demonstrated high-quality generation capability and accuracy. However, we still lack an appropriate understanding of how it processes approximation and generalization. This paper presents the first theoretical framework from the perspective of flow-based generative models to relieve the knowledge of limitations. In particular, we provide our insights with strict guarantees from three perspectives: $\textbf{Approximation}$, $\textbf{Generalization}$ and $\textbf{Efficiency}$. In detail, our analysis achieves the contributions as follows: $\bullet$ By assuming a general data model, the fitting of the flow-based generative models is confirmed to converge to arbitrary error under the universal approximation of Diffusion Transformer (DiT). $\bullet$ Introducing a polynomial-based regularization for flow matching, the generalization error thus be bounded since the generalization of polynomial approximation. $\bullet$ The sampling for generation is considered as an optimization process, we demonstrate its fast convergence with updating standard first-order gradient descent of some objective.
Theoretical Guarantees for High Order Trajectory Refinement in Generative Flows
Mar 12, 2025Flow matching has emerged as a powerful framework for generative modeling, offering computational advantages over diffusion models by leveraging deterministic Ordinary Differential Equations (ODEs) instead of stochastic dynamics. While prior work established the worst case optimality of standard flow matching under Wasserstein distances, the theoretical guarantees for higher-order flow matching - which incorporates acceleration terms to refine sample trajectories - remain unexplored. In this paper, we bridge this gap by proving that higher-order flow matching preserves worst case optimality as a distribution estimator. We derive upper bounds on the estimation error for second-order flow matching, demonstrating that the convergence rates depend polynomially on the smoothness of the target distribution (quantified via Besov spaces) and key parameters of the ODE dynamics. Our analysis employs neural network approximations with carefully controlled depth, width, and sparsity to bound acceleration errors across both small and large time intervals, ultimately unifying these results into a general worst case optimal bound for all time steps.
Simulation of Hypergraph Algorithms with Looped Transformers
Jan 18, 2025Looped Transformers have shown exceptional capability in simulating traditional graph algorithms, but their application to more complex structures like hypergraphs remains underexplored. Hypergraphs generalize graphs by modeling higher-order relationships among multiple entities, enabling richer representations but introducing significant computational challenges. In this work, we extend the Loop Transformer architecture to simulate hypergraph algorithms efficiently, addressing the gap between neural networks and combinatorial optimization over hypergraphs. In this paper, we extend the Loop Transformer architecture to simulate hypergraph algorithms efficiently, addressing the gap between neural networks and combinatorial optimization over hypergraphs. Specifically, we propose a novel degradation mechanism for reducing hypergraphs to graph representations, enabling the simulation of graph-based algorithms, such as Dijkstra's shortest path. Furthermore, we introduce a hyperedge-aware encoding scheme to simulate hypergraph-specific algorithms, exemplified by Helly's algorithm. The paper establishes theoretical guarantees for these simulations, demonstrating the feasibility of processing high-dimensional and combinatorial data using Loop Transformers. This work highlights the potential of Transformers as general-purpose algorithmic solvers for structured data.
Circuit Complexity Bounds for RoPE-based Transformer Architecture
Nov 12, 2024Characterizing the express power of the Transformer architecture is critical to understanding its capacity limits and scaling law. Recent works provide the circuit complexity bounds to Transformer-like architecture. On the other hand, Rotary Position Embedding ($\mathsf{RoPE}$) has emerged as a crucial technique in modern large language models, offering superior performance in capturing positional information compared to traditional position embeddings, which shows great potential in application prospects, particularly for the long context scenario. Empirical evidence also suggests that $\mathsf{RoPE}$-based Transformer architectures demonstrate greater generalization capabilities compared to conventional Transformer models. In this work, we establish a tighter circuit complexity bound for Transformers with $\mathsf{RoPE}$ attention. Our key contribution is that we show that unless $\mathsf{TC}^0 = \mathsf{NC}^1$, a $\mathsf{RoPE}$-based Transformer with $\mathrm{poly}(n)$-precision, $O(1)$ layers, hidden dimension $d \leq O(n)$ cannot solve the arithmetic problem or the Boolean formula value problem. This result significantly demonstrates the fundamental limitation of the expressivity of the $\mathsf{RoPE}$-based Transformer architecture, although it achieves giant empirical success. Our theoretical framework not only establishes tighter complexity bounds but also may instruct further work on the $\mathsf{RoPE}$-based Transformer.
Beyond Linear Approximations: A Novel Pruning Approach for Attention Matrix
Oct 15, 2024
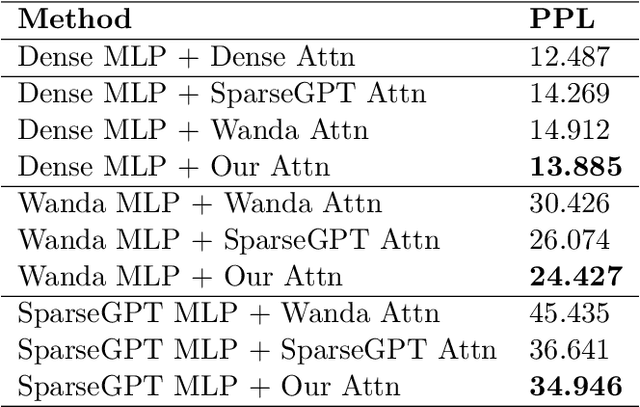


Large Language Models (LLMs) have shown immense potential in enhancing various aspects of our daily lives, from conversational AI to search and AI assistants. However, their growing capabilities come at the cost of extremely large model sizes, making deployment on edge devices challenging due to memory and computational constraints. This paper introduces a novel approach to LLM weight pruning that directly optimizes for approximating the attention matrix, a core component of transformer architectures. Unlike existing methods that focus on linear approximations, our approach accounts for the non-linear nature of the Softmax attention mechanism. We provide theoretical guarantees for the convergence of our Gradient Descent-based optimization method to a near-optimal pruning mask solution. Our preliminary empirical results demonstrate the effectiveness of this approach in maintaining model performance while significantly reducing computational costs. This work establishes a new theoretical foundation for pruning algorithm design in LLMs, potentially paving the way for more efficient LLM inference on resource-constrained devices.