 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLang2Str: Two-Stage Crystal Structure Generation with LLMs and Continuous Flow Models
Mar 04, 2026Generative models hold great promise for accelerating material discovery but are often limited by their inflexible single-stage generative process in designing valid and diverse materials. To address this, we propose a two-stage generative framework, Lang2Str, that combines the strengths of large language models (LLMs) and flow-based models for flexible and precise material generation. Our method frames the generative process as a conditional generative task, where an LLM provides high-level conditions by generating descriptions of material unit cells' geometric layouts and properties. These descriptions, informed by the LLM's extensive background knowledge, ensure reasonable structure designs. A conditioned flow model then decodes these textual conditions into precise continuous coordinates and unit cell parameters. This staged approach combines the structured reasoning of LLMs and the distribution modeling capabilities of flow models. Experimental results show that our method achieves competitive performance on \textit{ab initio} material generation and crystal structure prediction tasks, with generated structures exhibiting closer alignment to ground truth in both geometry and energy levels, surpassing state-of-the-art models. The flexibility and modularity of our framework further enable fine-grained control over the generation process, potentially leading to more efficient and customizable material design.
Protenix-Mini: Efficient Structure Predictor via Compact Architecture, Few-Step Diffusion and Switchable pLM
Jul 16, 2025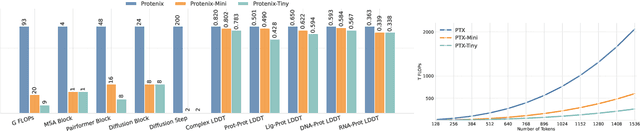



Lightweight inference is critical for biomolecular structure prediction and other downstream tasks, enabling efficient real-world deployment and inference-time scaling for large-scale applications. In this work, we address the challenge of balancing model efficiency and prediction accuracy by making several key modifications, 1) Multi-step AF3 sampler is replaced by a few-step ODE sampler, significantly reducing computational overhead for the diffusion module part during inference; 2) In the open-source Protenix framework, a subset of pairformer or diffusion transformer blocks doesn't make contributions to the final structure prediction, presenting opportunities for architectural pruning and lightweight redesign; 3) A model incorporating an ESM module is trained to substitute the conventional MSA module, reducing MSA preprocessing time. Building on these key insights, we present Protenix-Mini, a compact and optimized model designed for efficient protein structure prediction. This streamlined version incorporates a more efficient architectural design with a two-step Ordinary Differential Equation (ODE) sampling strategy. By eliminating redundant Transformer components and refining the sampling process, Protenix-Mini significantly reduces model complexity with slight accuracy drop. Evaluations on benchmark datasets demonstrate that it achieves high-fidelity predictions, with only a negligible 1 to 5 percent decrease in performance on benchmark datasets compared to its full-scale counterpart. This makes Protenix-Mini an ideal choice for applications where computational resources are limited but accurate structure prediction remains crucial.
Theoretical Guarantees for High Order Trajectory Refinement in Generative Flows
Mar 12, 2025Flow matching has emerged as a powerful framework for generative modeling, offering computational advantages over diffusion models by leveraging deterministic Ordinary Differential Equations (ODEs) instead of stochastic dynamics. While prior work established the worst case optimality of standard flow matching under Wasserstein distances, the theoretical guarantees for higher-order flow matching - which incorporates acceleration terms to refine sample trajectories - remain unexplored. In this paper, we bridge this gap by proving that higher-order flow matching preserves worst case optimality as a distribution estimator. We derive upper bounds on the estimation error for second-order flow matching, demonstrating that the convergence rates depend polynomially on the smoothness of the target distribution (quantified via Besov spaces) and key parameters of the ODE dynamics. Our analysis employs neural network approximations with carefully controlled depth, width, and sparsity to bound acceleration errors across both small and large time intervals, ultimately unifying these results into a general worst case optimal bound for all time steps.
On Computational Limits of FlowAR Models: Expressivity and Efficiency
Feb 23, 2025The expressive power and computational complexity of deep visual generative models, such as flow-based and autoregressive (AR) models, have gained considerable interest for their wide-ranging applications in generative tasks. However, the theoretical characterization of their expressiveness through the lens of circuit complexity remains underexplored, particularly for the state-of-the-art architecture like FlowAR proposed by [Ren et al., 2024], which integrates flow-based and autoregressive mechanisms. This gap limits our understanding of their inherent computational limits and practical efficiency. In this study, we address this gap by analyzing the circuit complexity of the FlowAR architecture. We demonstrate that when the largest feature map produced by the FlowAR model has dimensions $n \times n \times c$, the FlowAR model is simulable by a family of threshold circuits $\mathsf{TC}^0$, which have constant depth $O(1)$ and polynomial width $\mathrm{poly}(n)$. This is the first study to rigorously highlight the limitations in the expressive power of FlowAR models. Furthermore, we identify the conditions under which the FlowAR model computations can achieve almost quadratic time. To validate our theoretical findings, we present efficient model variant constructions based on low-rank approximations that align with the derived criteria. Our work provides a foundation for future comparisons with other generative paradigms and guides the development of more efficient and expressive implementations.
RichSpace: Enriching Text-to-Video Prompt Space via Text Embedding Interpolation
Jan 17, 2025Text-to-video generation models have made impressive progress, but they still struggle with generating videos with complex features. This limitation often arises from the inability of the text encoder to produce accurate embeddings, which hinders the video generation model. In this work, we propose a novel approach to overcome this challenge by selecting the optimal text embedding through interpolation in the embedding space. We demonstrate that this method enables the video generation model to produce the desired videos. Additionally, we introduce a simple algorithm using perpendicular foot embeddings and cosine similarity to identify the optimal interpolation embedding. Our findings highlight the importance of accurate text embeddings and offer a pathway for improving text-to-video generation performance.
Rectified Flow For Structure Based Drug Design
Dec 02, 2024Deep generative models have achieved tremendous success in structure-based drug design in recent years, especially for generating 3D ligand molecules that bind to specific protein pocket. Notably, diffusion models have transformed ligand generation by providing exceptional quality and creativity. However, traditional diffusion models are restricted by their conventional learning objectives, which limit their broader applicability. In this work, we propose a new framework FlowSBDD, which is based on rectified flow model, allows us to flexibly incorporate additional loss to optimize specific target and introduce additional condition either as an extra input condition or replacing the initial Gaussian distribution. Extensive experiments on CrossDocked2020 show that our approach could achieve state-of-the-art performance on generating high-affinity molecules while maintaining proper molecular properties without specifically designing binding site, with up to -8.50 Avg. Vina Dock score and 75.0% Diversity.
Switchable Decision: Dynamic Neural Generation Networks
May 07, 2024Auto-regressive generation models achieve competitive performance across many different NLP tasks such as summarization, question answering, and classifications. However, they are also known for being slow in inference, which makes them challenging to deploy in real-time applications. We propose a switchable decision to accelerate inference by dynamically assigning computation resources for each data instance. Automatically making decisions on where to skip and how to balance quality and computation cost with constrained optimization, our dynamic neural generation networks enforce the efficient inference path and determine the optimized trade-off. Experiments across question answering, summarization, and classification benchmarks show that our method benefits from less computation cost during inference while keeping the same accuracy. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many NLP tasks.
Language Rectified Flow: Advancing Diffusion Language Generation with Probabilistic Flows
Mar 25, 2024Recent works have demonstrated success in controlling sentence attributes ($e.g.$, sentiment) and structure ($e.g.$, syntactic structure) based on the diffusion language model. A key component that drives theimpressive performance for generating high-quality samples from noise is iteratively denoise for thousands of steps. While beneficial, the complexity of starting from the noise and the learning steps has limited its implementation to many NLP real-world applications. This paper proposes Language Rectified Flow ({\ours}). Our method is based on the reformulation of the standard probabilistic flow models. Language rectified flow learns (neural) ordinary differential equation models to transport between the source distribution and the target distribution, hence providing a unified and effective solution to generative modeling and domain transfer. From the source distribution, our language rectified flow yields fast simulation and effectively decreases the inference time. Experiments on three challenging fine-grained control tasks and multiple high-quality text editing show that our method consistently outperforms its baselines. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many NLP tasks.
AutoML-GPT: Automatic Machine Learning with GPT
May 04, 2023



AI tasks encompass a wide range of domains and fields. While numerous AI models have been designed for specific tasks and applications, they often require considerable human efforts in finding the right model architecture, optimization algorithm, and hyperparameters. Recent advances in large language models (LLMs) like ChatGPT show remarkable capabilities in various aspects of reasoning, comprehension, and interaction. Consequently, we propose developing task-oriented prompts and automatically utilizing LLMs to automate the training pipeline. To implement this concept, we present the AutoML-GPT, which employs GPT as the bridge to diverse AI models and dynamically trains models with optimized hyperparameters. AutoML-GPT dynamically takes user requests from the model and data cards and composes the corresponding prompt paragraph. Ultimately, with this prompt paragraph, AutoML-GPT will automatically conduct the experiments from data processing to model architecture, hyperparameter tuning, and predicted training log. By leveraging {\ours}'s robust language capabilities and the available AI models, AutoML-GPT can tackle numerous intricate AI tasks across various tasks and datasets. This approach achieves remarkable results in computer vision, natural language processing, and other challenging areas. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many AI tasks.
Fast Point Cloud Generation with Straight Flows
Dec 04, 2022



Diffusion models have emerged as a powerful tool for point cloud generation. A key component that drives the impressive performance for generating high-quality samples from noise is iteratively denoise for thousands of steps. While beneficial, the complexity of learning steps has limited its applications to many 3D real-world. To address this limitation, we propose Point Straight Flow (PSF), a model that exhibits impressive performance using one step. Our idea is based on the reformulation of the standard diffusion model, which optimizes the curvy learning trajectory into a straight path. Further, we develop a distillation strategy to shorten the straight path into one step without a performance loss, enabling applications to 3D real-world with latency constraints. We perform evaluations on multiple 3D tasks and find that our PSF performs comparably to the standard diffusion model, outperforming other efficient 3D point cloud generation methods. On real-world applications such as point cloud completion and training-free text-guided generation in a low-latency setup, PSF performs favorably.