 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
Dec 31, 2025Evaluating the quality of multi-turn conversations is crucial for developing capable Large Language Models (LLMs), yet remains a significant challenge, often requiring costly human evaluation. Multi-turn reward models (RMs) offer a scalable alternative and can provide valuable signals for guiding LLM training. While recent work has advanced multi-turn \textit{training} techniques, effective automated \textit{evaluation} specifically for multi-turn interactions lags behind. We observe that standard preference datasets, typically contrasting responses based only on the final conversational turn, provide insufficient signal to capture the nuances of multi-turn interactions. Instead, we find that incorporating contrasts spanning \textit{multiple} turns is critical for building robust multi-turn RMs. Motivated by this finding, we propose \textbf{MU}lti-\textbf{S}tep \textbf{I}nstruction \textbf{C}ontrast (MUSIC), an unsupervised data augmentation strategy that synthesizes contrastive conversation pairs exhibiting differences across multiple turns. Leveraging MUSIC on the Skywork preference dataset, we train a multi-turn RM based on the Gemma-2-9B-Instruct model. Empirical results demonstrate that our MUSIC-augmented RM outperforms baseline methods, achieving higher alignment with judgments from advanced proprietary LLM judges on multi-turn conversations, crucially, without compromising performance on standard single-turn RM benchmarks.
Fantastic Reasoning Behaviors and Where to Find Them: Unsupervised Discovery of the Reasoning Process
Dec 30, 2025Despite the growing reasoning capabilities of recent large language models (LLMs), their internal mechanisms during the reasoning process remain underexplored. Prior approaches often rely on human-defined concepts (e.g., overthinking, reflection) at the word level to analyze reasoning in a supervised manner. However, such methods are limited, as it is infeasible to capture the full spectrum of potential reasoning behaviors, many of which are difficult to define in token space. In this work, we propose an unsupervised framework (namely, RISE: Reasoning behavior Interpretability via Sparse auto-Encoder) for discovering reasoning vectors, which we define as directions in the activation space that encode distinct reasoning behaviors. By segmenting chain-of-thought traces into sentence-level 'steps' and training sparse auto-encoders (SAEs) on step-level activations, we uncover disentangled features corresponding to interpretable behaviors such as reflection and backtracking. Visualization and clustering analyses show that these behaviors occupy separable regions in the decoder column space. Moreover, targeted interventions on SAE-derived vectors can controllably amplify or suppress specific reasoning behaviors, altering inference trajectories without retraining. Beyond behavior-specific disentanglement, SAEs capture structural properties such as response length, revealing clusters of long versus short reasoning traces. More interestingly, SAEs enable the discovery of novel behaviors beyond human supervision. We demonstrate the ability to control response confidence by identifying confidence-related vectors in the SAE decoder space. These findings underscore the potential of unsupervised latent discovery for both interpreting and controllably steering reasoning in LLMs.
Eliciting Behaviors in Multi-Turn Conversations
Dec 29, 2025Identifying specific and often complex behaviors from large language models (LLMs) in conversational settings is crucial for their evaluation. Recent work proposes novel techniques to find natural language prompts that induce specific behaviors from a target model, yet they are mainly studied in single-turn settings. In this work, we study behavior elicitation in the context of multi-turn conversations. We first offer an analytical framework that categorizes existing methods into three families based on their interactions with the target model: those that use only prior knowledge, those that use offline interactions, and those that learn from online interactions. We then introduce a generalized multi-turn formulation of the online method, unifying single-turn and multi-turn elicitation. We evaluate all three families of methods on automatically generating multi-turn test cases. We investigate the efficiency of these approaches by analyzing the trade-off between the query budget, i.e., the number of interactions with the target model, and the success rate, i.e., the discovery rate of behavior-eliciting inputs. We find that online methods can achieve an average success rate of 45/19/77% with just a few thousand queries over three tasks where static methods from existing multi-turn conversation benchmarks find few or even no failure cases. Our work highlights a novel application of behavior elicitation methods in multi-turn conversation evaluation and the need for the community to move towards dynamic benchmarks.
Optimized scheduling of electricity-heat cooperative system considering wind energy consumption and peak shaving and valley filling
Nov 19, 2025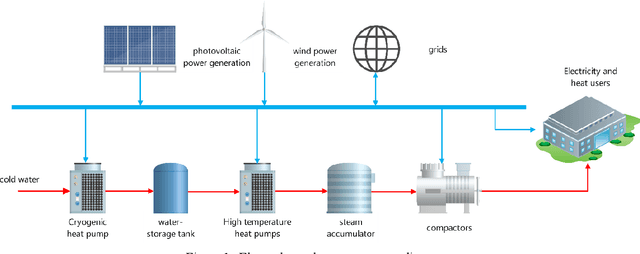



With the global energy transition and rapid development of renewable energy, the scheduling optimization challenge for combined power-heat systems under new energy integration and multiple uncertainties has become increasingly prominent. Addressing this challenge, this study proposes an intelligent scheduling method based on the improved Dual-Delay Deep Deterministic Policy Gradient (PVTD3) algorithm. System optimization is achieved by introducing a penalty term for grid power purchase variations. Simulation results demonstrate that under three typical scenarios (10%, 20%, and 30% renewable penetration), the PVTD3 algorithm reduces the system's comprehensive cost by 6.93%, 12.68%, and 13.59% respectively compared to the traditional TD3 algorithm. Concurrently, it reduces the average fluctuation amplitude of grid power purchases by 12.8%. Regarding energy storage management, the PVTD3 algorithm reduces the end-time state values of low-temperature thermal storage tanks by 7.67-17.67 units while maintaining high-temperature tanks within the 3.59-4.25 safety operating range. Multi-scenario comparative validation demonstrates that the proposed algorithm not only excels in economic efficiency and grid stability but also exhibits superior sustainable scheduling capabilities in energy storage device management.
Principled Foundations for Preference Optimization
Jul 10, 2025In this paper, we show that direct preference optimization (DPO) is a very specific form of a connection between two major theories in the ML context of learning from preferences: loss functions (Savage) and stochastic choice (Doignon-Falmagne and Machina). The connection is established for all of Savage's losses and at this level of generality, (i) it includes support for abstention on the choice theory side, (ii) it includes support for non-convex objectives on the ML side, and (iii) it allows to frame for free some notable extensions of the DPO setting, including margins and corrections for length. Getting to understand how DPO operates from a general principled perspective is crucial because of the huge and diverse application landscape of models, because of the current momentum around DPO, but also -- and importantly -- because many state of the art variations on DPO definitely occupy a small region of the map that we cover. It also helps to understand the pitfalls of departing from this map, and figure out workarounds.
T-REG: Preference Optimization with Token-Level Reward Regularization
Dec 03, 2024Reinforcement learning from human feedback (RLHF) has been crucial in aligning large language models (LLMs) with human values. Traditionally, RLHF involves generating responses to a query and using a reward model to assign a reward to the entire response. However, this approach faces challenges due to its reliance on a single, sparse reward, which makes it challenging for the model to identify which parts of the sequence contribute most significantly to the final reward. Recent methods have attempted to address this limitation by introducing token-level rewards. However, these methods often rely on either a trained credit assignment model or AI annotators, raising concerns about the quality and reliability of the rewards. In this paper, we propose token-level reward regularization (T-REG), a novel approach that leverages both sequence-level and token-level rewards for preference optimization. Harnessing the self-refinement capabilities of LLMs, our method uses contrastive prompting to enable LLMs to self-generate token-level rewards. These self-generated rewards then act as reward regularization, guiding the model to more effectively distribute sequence-level rewards across tokens. This facilitates better token-level credit assignment and enhances alignment performance. Experiments on the instruction following benchmarks, including Alpaca Eval 2 and Arena-Hard, show that our method consistently outperforms baseline methods by up to 3.8% and 4.4%, respectively. We will release the code and models at https://github.com/wzhouad/T-REG.
Instructional Segment Embedding: Improving LLM Safety with Instruction Hierarchy
Oct 09, 2024



Large Language Models (LLMs) are susceptible to security and safety threats, such as prompt injection, prompt extraction, and harmful requests. One major cause of these vulnerabilities is the lack of an instruction hierarchy. Modern LLM architectures treat all inputs equally, failing to distinguish between and prioritize various types of instructions, such as system messages, user prompts, and data. As a result, lower-priority user prompts may override more critical system instructions, including safety protocols. Existing approaches to achieving instruction hierarchy, such as delimiters and instruction-based training, do not address this issue at the architectural level. We introduce the Instructional Segment Embedding (ISE) technique, inspired by BERT, to modern large language models, which embeds instruction priority information directly into the model. This approach enables models to explicitly differentiate and prioritize various instruction types, significantly improving safety against malicious prompts that attempt to override priority rules. Our experiments on the Structured Query and Instruction Hierarchy benchmarks demonstrate an average robust accuracy increase of up to 15.75% and 18.68%, respectively. Furthermore, we observe an improvement in instruction-following capability of up to 4.1% evaluated on AlpacaEval. Overall, our approach offers a promising direction for enhancing the safety and effectiveness of LLM architectures.
SFTMix: Elevating Language Model Instruction Tuning with Mixup Recipe
Oct 07, 2024



To induce desired behaviors in large language models (LLMs) for interaction-driven tasks, the instruction-tuning stage typically trains LLMs on instruction-response pairs using the next-token prediction (NTP) loss. Previous work aiming to improve instruction-tuning performance often emphasizes the need for higher-quality supervised fine-tuning (SFT) datasets, which typically involves expensive data filtering with proprietary LLMs or labor-intensive data generation by human annotators. However, these approaches do not fully leverage the datasets' intrinsic properties, resulting in high computational and labor costs, thereby limiting scalability and performance gains. In this paper, we propose SFTMix, a novel recipe that elevates instruction-tuning performance beyond the conventional NTP paradigm, without the need for well-curated datasets. Observing that LLMs exhibit uneven confidence across the semantic representation space, we argue that examples with different confidence levels should play distinct roles during the instruction-tuning process. Based on this insight, SFTMix leverages training dynamics to identify examples with varying confidence levels, then applies a Mixup-based regularization to mitigate overfitting on confident examples while propagating supervision signals to improve learning on relatively unconfident ones. This approach enables SFTMix to significantly outperform NTP across a wide range of instruction-following and healthcare domain-specific SFT tasks, demonstrating its adaptability to diverse LLM families and scalability to datasets of any size. Comprehensive ablation studies further verify the robustness of SFTMix's design choices, underscoring its versatility in consistently enhancing performance across different LLMs and datasets in broader natural language processing applications.
Score Forgetting Distillation: A Swift, Data-Free Method for Machine Unlearning in Diffusion Models
Sep 17, 2024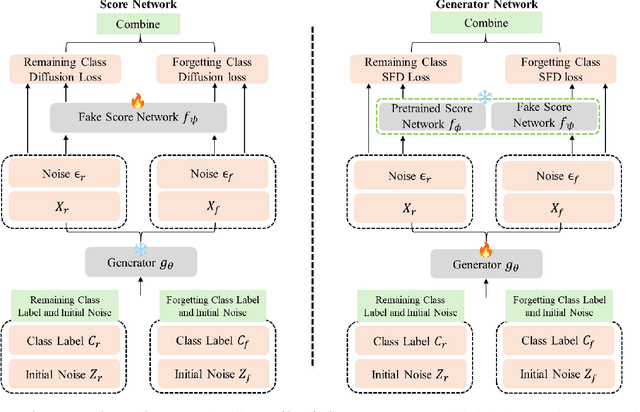



The machine learning community is increasingly recognizing the importance of fostering trust and safety in modern generative AI (GenAI) models. We posit machine unlearning (MU) as a crucial foundation for developing safe, secure, and trustworthy GenAI models. Traditional MU methods often rely on stringent assumptions and require access to real data. This paper introduces Score Forgetting Distillation (SFD), an innovative MU approach that promotes the forgetting of undesirable information in diffusion models by aligning the conditional scores of ``unsafe'' classes or concepts with those of ``safe'' ones. To eliminate the need for real data, our SFD framework incorporates a score-based MU loss into the score distillation objective of a pretrained diffusion model. This serves as a regularization term that preserves desired generation capabilities while enabling the production of synthetic data through a one-step generator. Our experiments on pretrained label-conditional and text-to-image diffusion models demonstrate that our method effectively accelerates the forgetting of target classes or concepts during generation, while preserving the quality of other classes or concepts. This unlearned and distilled diffusion not only pioneers a novel concept in MU but also accelerates the generation speed of diffusion models. Our experiments and studies on a range of diffusion models and datasets confirm that our approach is generalizable, effective, and advantageous for MU in diffusion models.
WPO: Enhancing RLHF with Weighted Preference Optimization
Jun 17, 2024Reinforcement learning from human feedback (RLHF) is a promising solution to align large language models (LLMs) more closely with human values. Off-policy preference optimization, where the preference data is obtained from other models, is widely adopted due to its cost efficiency and scalability. However, off-policy preference optimization often suffers from a distributional gap between the policy used for data collection and the target policy, leading to suboptimal optimization. In this paper, we propose a novel strategy to mitigate this problem by simulating on-policy learning with off-policy preference data. Our Weighted Preference Optimization (WPO) method adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. This method not only addresses the distributional gap problem but also enhances the optimization process without incurring additional costs. We validate our method on instruction following benchmarks including Alpaca Eval 2 and MT-bench. WPO not only outperforms Direct Preference Optimization (DPO) by up to 5.6% on Alpaca Eval 2 but also establishes a remarkable length-controlled winning rate against GPT-4-turbo of 48.6% based on Llama-3-8B-Instruct, making it the strongest 8B model on the leaderboard. We will release the code and models at https://github.com/wzhouad/WPO.