 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitchable Decision: Dynamic Neural Generation Networks
May 07, 2024Auto-regressive generation models achieve competitive performance across many different NLP tasks such as summarization, question answering, and classifications. However, they are also known for being slow in inference, which makes them challenging to deploy in real-time applications. We propose a switchable decision to accelerate inference by dynamically assigning computation resources for each data instance. Automatically making decisions on where to skip and how to balance quality and computation cost with constrained optimization, our dynamic neural generation networks enforce the efficient inference path and determine the optimized trade-off. Experiments across question answering, summarization, and classification benchmarks show that our method benefits from less computation cost during inference while keeping the same accuracy. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many NLP tasks.
POUF: Prompt-oriented unsupervised fine-tuning for large pre-trained models
Apr 29, 2023Through prompting, large-scale pre-trained models have become more expressive and powerful, gaining significant attention in recent years. Though these big models have zero-shot capabilities, in general, labeled data are still required to adapt them to downstream tasks. To overcome this critical limitation, we propose an unsupervised fine-tuning framework to directly fine-tune the model or prompt on the unlabeled target data. We demonstrate how to apply our method to both language-augmented vision and masked-language models by aligning the discrete distributions extracted from the prompts and target data. To verify our approach's applicability, we conduct extensive experiments on image classification, sentiment analysis, and natural language inference tasks. Across 13 image-related tasks and 15 language-related ones, the proposed approach achieves consistent improvements over the baselines.
A Prototype-Oriented Clustering for Domain Shift with Source Privacy
Feb 09, 2023Unsupervised clustering under domain shift (UCDS) studies how to transfer the knowledge from abundant unlabeled data from multiple source domains to learn the representation of the unlabeled data in a target domain. In this paper, we introduce Prototype-oriented Clustering with Distillation (PCD) to not only improve the performance and applicability of existing methods for UCDS, but also address the concerns on protecting the privacy of both the data and model of the source domains. PCD first constructs a source clustering model by aligning the distributions of prototypes and data. It then distills the knowledge to the target model through cluster labels provided by the source model while simultaneously clustering the target data. Finally, it refines the target model on the target domain data without guidance from the source model. Experiments across multiple benchmarks show the effectiveness and generalizability of our source-private clustering method.
Representing Mixtures of Word Embeddings with Mixtures of Topic Embeddings
Mar 15, 2022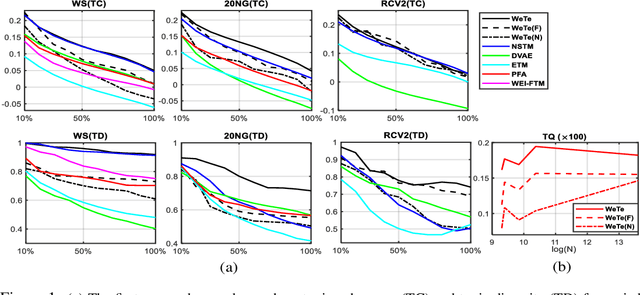
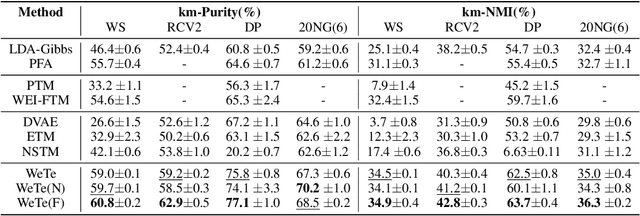
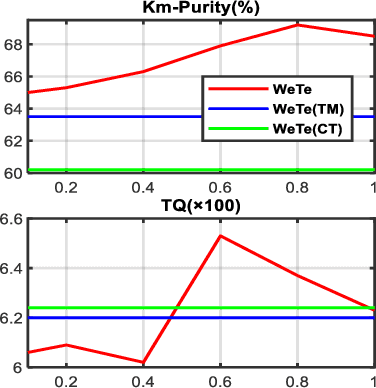

A topic model is often formulated as a generative model that explains how each word of a document is generated given a set of topics and document-specific topic proportions. It is focused on capturing the word co-occurrences in a document and hence often suffers from poor performance in analyzing short documents. In addition, its parameter estimation often relies on approximate posterior inference that is either not scalable or suffers from large approximation error. This paper introduces a new topic-modeling framework where each document is viewed as a set of word embedding vectors and each topic is modeled as an embedding vector in the same embedding space. Embedding the words and topics in the same vector space, we define a method to measure the semantic difference between the embedding vectors of the words of a document and these of the topics, and optimize the topic embeddings to minimize the expected difference over all documents. Experiments on text analysis demonstrate that the proposed method, which is amenable to mini-batch stochastic gradient descent based optimization and hence scalable to big corpora, provides competitive performance in discovering more coherent and diverse topics and extracting better document representations.
Alignment Attention by Matching Key and Query Distributions
Oct 25, 2021



The neural attention mechanism has been incorporated into deep neural networks to achieve state-of-the-art performance in various domains. Most such models use multi-head self-attention which is appealing for the ability to attend to information from different perspectives. This paper introduces alignment attention that explicitly encourages self-attention to match the distributions of the key and query within each head. The resulting alignment attention networks can be optimized as an unsupervised regularization in the existing attention framework. It is simple to convert any models with self-attention, including pre-trained ones, to the proposed alignment attention. On a variety of language understanding tasks, we show the effectiveness of our method in accuracy, uncertainty estimation, generalization across domains, and robustness to adversarial attacks. We further demonstrate the general applicability of our approach on graph attention and visual question answering, showing the great potential of incorporating our alignment method into various attention-related tasks.
A Prototype-Oriented Framework for Unsupervised Domain Adaptation
Oct 22, 2021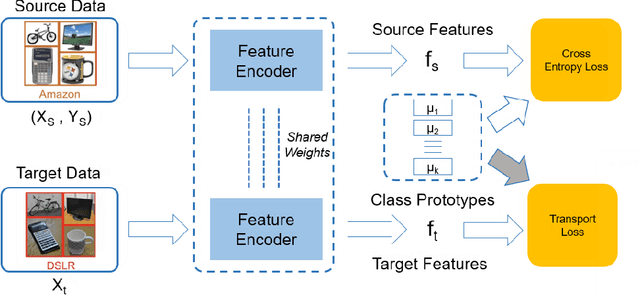
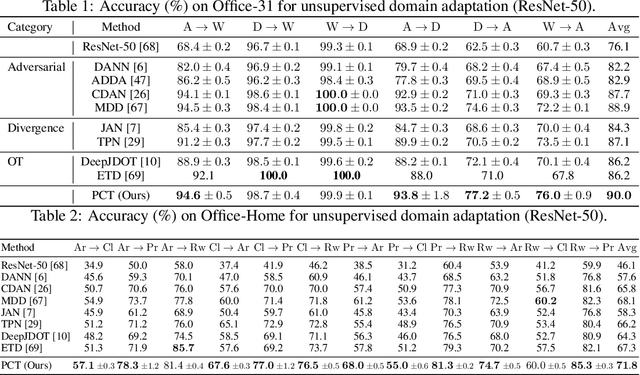

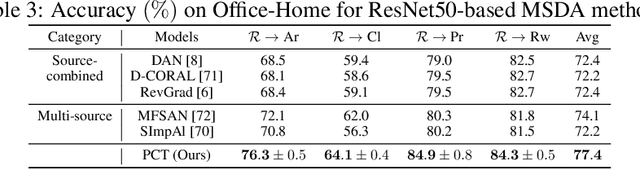
Existing methods for unsupervised domain adaptation often rely on minimizing some statistical distance between the source and target samples in the latent space. To avoid the sampling variability, class imbalance, and data-privacy concerns that often plague these methods, we instead provide a memory and computation-efficient probabilistic framework to extract class prototypes and align the target features with them. We demonstrate the general applicability of our method on a wide range of scenarios, including single-source, multi-source, class-imbalance, and source-private domain adaptation. Requiring no additional model parameters and having a moderate increase in computation over the source model alone, the proposed method achieves competitive performance with state-of-the-art methods.
Contextual Dropout: An Efficient Sample-Dependent Dropout Module
Mar 06, 2021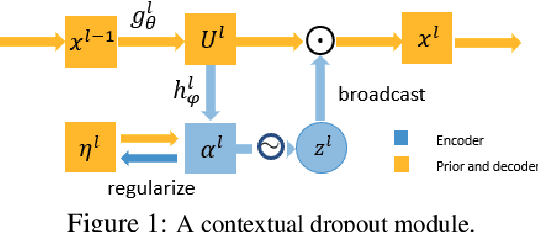
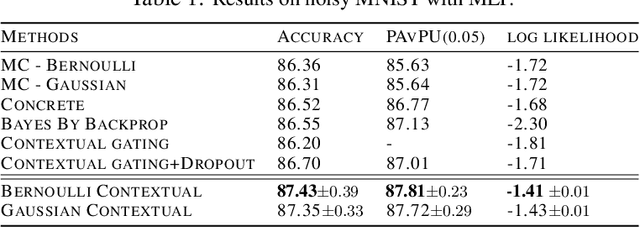
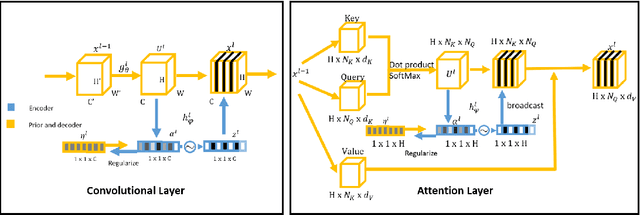
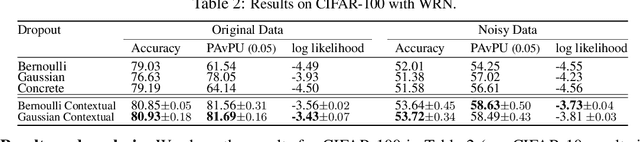
Dropout has been demonstrated as a simple and effective module to not only regularize the training process of deep neural networks, but also provide the uncertainty estimation for prediction. However, the quality of uncertainty estimation is highly dependent on the dropout probabilities. Most current models use the same dropout distributions across all data samples due to its simplicity. Despite the potential gains in the flexibility of modeling uncertainty, sample-dependent dropout, on the other hand, is less explored as it often encounters scalability issues or involves non-trivial model changes. In this paper, we propose contextual dropout with an efficient structural design as a simple and scalable sample-dependent dropout module, which can be applied to a wide range of models at the expense of only slightly increased memory and computational cost. We learn the dropout probabilities with a variational objective, compatible with both Bernoulli dropout and Gaussian dropout. We apply the contextual dropout module to various models with applications to image classification and visual question answering and demonstrate the scalability of the method with large-scale datasets, such as ImageNet and VQA 2.0. Our experimental results show that the proposed method outperforms baseline methods in terms of both accuracy and quality of uncertainty estimation.