 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Attention by Matching Key and Query Distributions
Oct 25, 2021



The neural attention mechanism has been incorporated into deep neural networks to achieve state-of-the-art performance in various domains. Most such models use multi-head self-attention which is appealing for the ability to attend to information from different perspectives. This paper introduces alignment attention that explicitly encourages self-attention to match the distributions of the key and query within each head. The resulting alignment attention networks can be optimized as an unsupervised regularization in the existing attention framework. It is simple to convert any models with self-attention, including pre-trained ones, to the proposed alignment attention. On a variety of language understanding tasks, we show the effectiveness of our method in accuracy, uncertainty estimation, generalization across domains, and robustness to adversarial attacks. We further demonstrate the general applicability of our approach on graph attention and visual question answering, showing the great potential of incorporating our alignment method into various attention-related tasks.
A Prototype-Oriented Framework for Unsupervised Domain Adaptation
Oct 22, 2021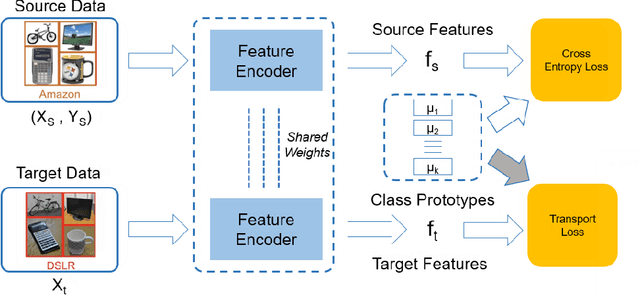
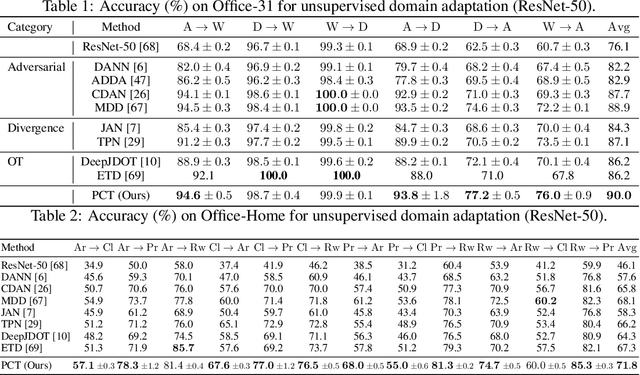

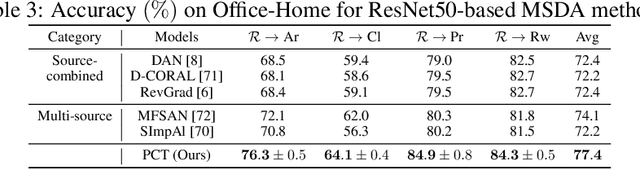
Existing methods for unsupervised domain adaptation often rely on minimizing some statistical distance between the source and target samples in the latent space. To avoid the sampling variability, class imbalance, and data-privacy concerns that often plague these methods, we instead provide a memory and computation-efficient probabilistic framework to extract class prototypes and align the target features with them. We demonstrate the general applicability of our method on a wide range of scenarios, including single-source, multi-source, class-imbalance, and source-private domain adaptation. Requiring no additional model parameters and having a moderate increase in computation over the source model alone, the proposed method achieves competitive performance with state-of-the-art methods.
Bayesian Attention Belief Networks
Jun 09, 2021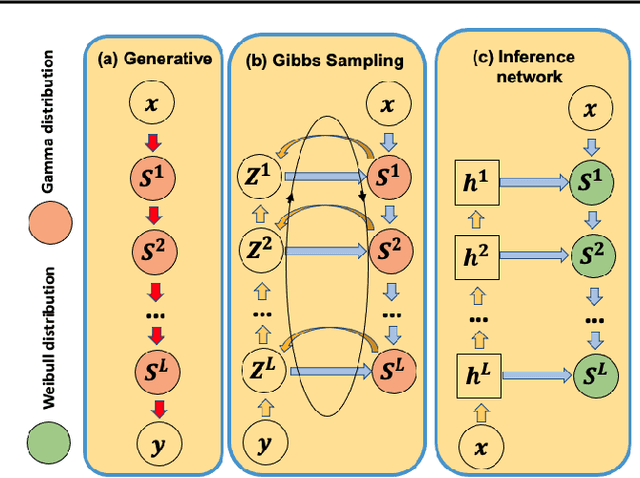

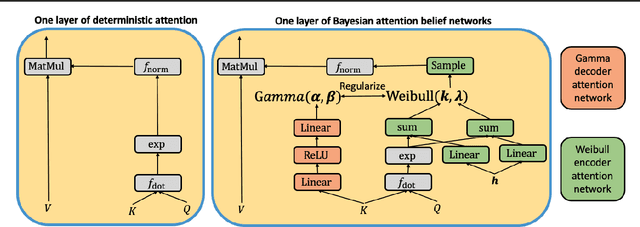
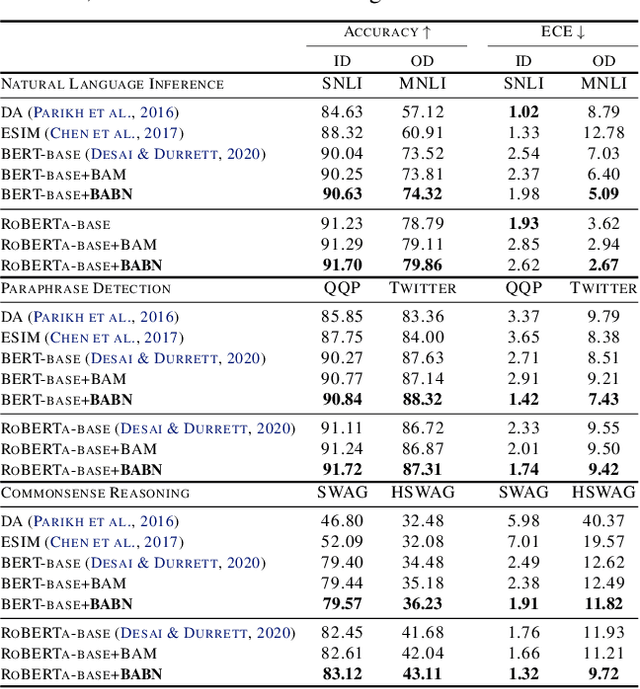
Attention-based neural networks have achieved state-of-the-art results on a wide range of tasks. Most such models use deterministic attention while stochastic attention is less explored due to the optimization difficulties or complicated model design. This paper introduces Bayesian attention belief networks, which construct a decoder network by modeling unnormalized attention weights with a hierarchy of gamma distributions, and an encoder network by stacking Weibull distributions with a deterministic-upward-stochastic-downward structure to approximate the posterior. The resulting auto-encoding networks can be optimized in a differentiable way with a variational lower bound. It is simple to convert any models with deterministic attention, including pretrained ones, to the proposed Bayesian attention belief networks. On a variety of language understanding tasks, we show that our method outperforms deterministic attention and state-of-the-art stochastic attention in accuracy, uncertainty estimation, generalization across domains, and robustness to adversarial attacks. We further demonstrate the general applicability of our method on neural machine translation and visual question answering, showing great potential of incorporating our method into various attention-related tasks.
Adversarially Adaptive Normalization for Single Domain Generalization
Jun 01, 2021
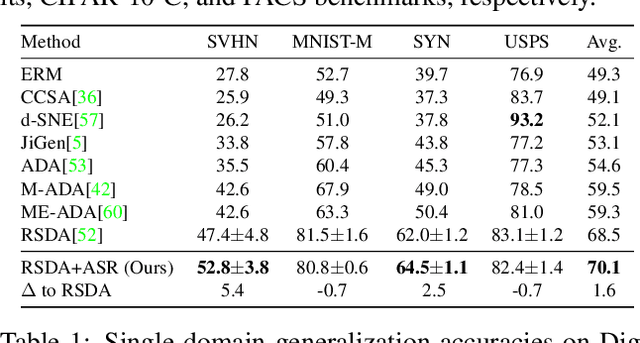
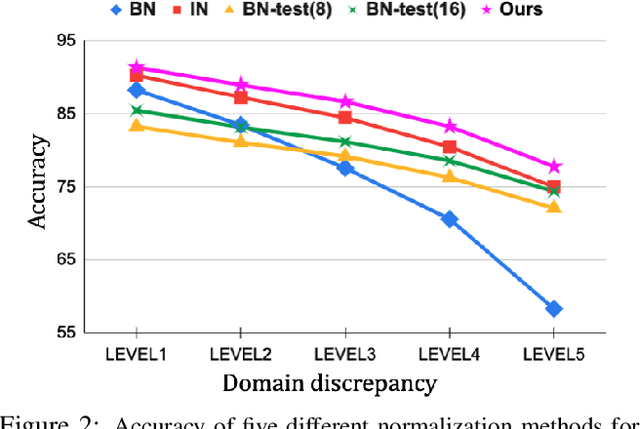
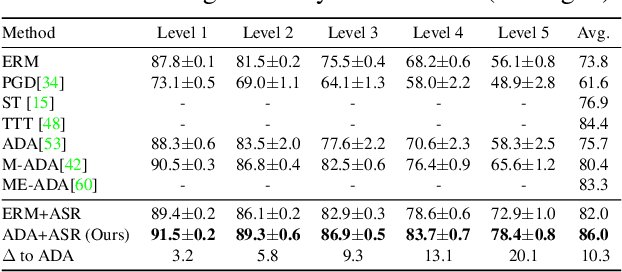
Single domain generalization aims to learn a model that performs well on many unseen domains with only one domain data for training. Existing works focus on studying the adversarial domain augmentation (ADA) to improve the model's generalization capability. The impact on domain generalization of the statistics of normalization layers is still underinvestigated. In this paper, we propose a generic normalization approach, adaptive standardization and rescaling normalization (ASR-Norm), to complement the missing part in previous works. ASR-Norm learns both the standardization and rescaling statistics via neural networks. This new form of normalization can be viewed as a generic form of the traditional normalizations. When trained with ADA, the statistics in ASR-Norm are learned to be adaptive to the data coming from different domains, and hence improves the model generalization performance across domains, especially on the target domain with large discrepancy from the source domain. The experimental results show that ASR-Norm can bring consistent improvement to the state-of-the-art ADA approaches by 1.6%, 2.7%, and 6.3% averagely on the Digits, CIFAR-10-C, and PACS benchmarks, respectively. As a generic tool, the improvement introduced by ASR-Norm is agnostic to the choice of ADA methods.
Contextual Dropout: An Efficient Sample-Dependent Dropout Module
Mar 06, 2021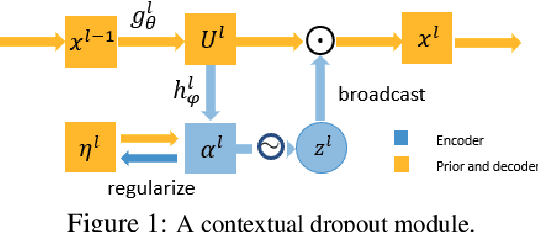
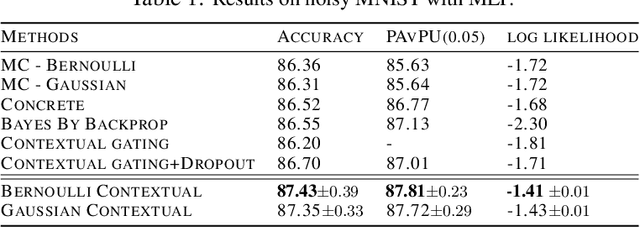
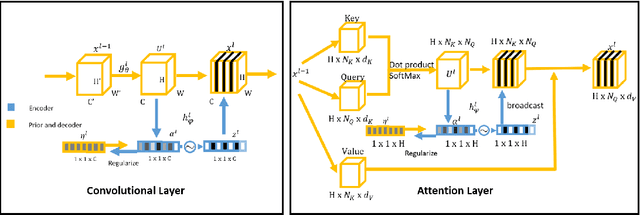
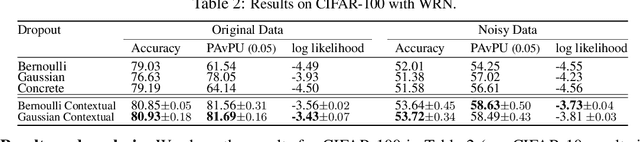
Dropout has been demonstrated as a simple and effective module to not only regularize the training process of deep neural networks, but also provide the uncertainty estimation for prediction. However, the quality of uncertainty estimation is highly dependent on the dropout probabilities. Most current models use the same dropout distributions across all data samples due to its simplicity. Despite the potential gains in the flexibility of modeling uncertainty, sample-dependent dropout, on the other hand, is less explored as it often encounters scalability issues or involves non-trivial model changes. In this paper, we propose contextual dropout with an efficient structural design as a simple and scalable sample-dependent dropout module, which can be applied to a wide range of models at the expense of only slightly increased memory and computational cost. We learn the dropout probabilities with a variational objective, compatible with both Bernoulli dropout and Gaussian dropout. We apply the contextual dropout module to various models with applications to image classification and visual question answering and demonstrate the scalability of the method with large-scale datasets, such as ImageNet and VQA 2.0. Our experimental results show that the proposed method outperforms baseline methods in terms of both accuracy and quality of uncertainty estimation.
Bayesian Attention Modules
Oct 20, 2020
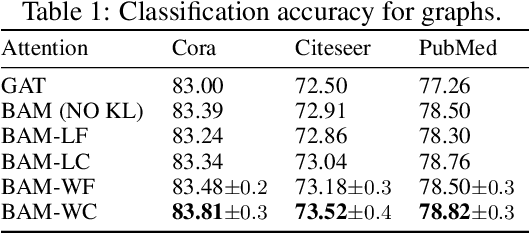
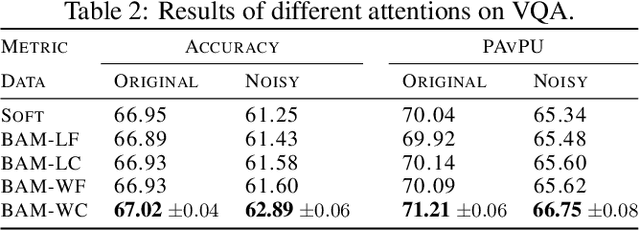

Attention modules, as simple and effective tools, have not only enabled deep neural networks to achieve state-of-the-art results in many domains, but also enhanced their interpretability. Most current models use deterministic attention modules due to their simplicity and ease of optimization. Stochastic counterparts, on the other hand, are less popular despite their potential benefits. The main reason is that stochastic attention often introduces optimization issues or requires significant model changes. In this paper, we propose a scalable stochastic version of attention that is easy to implement and optimize. We construct simplex-constrained attention distributions by normalizing reparameterizable distributions, making the training process differentiable. We learn their parameters in a Bayesian framework where a data-dependent prior is introduced for regularization. We apply the proposed stochastic attention modules to various attention-based models, with applications to graph node classification, visual question answering, image captioning, machine translation, and language understanding. Our experiments show the proposed method brings consistent improvements over the corresponding baselines.
Attention that does not Explain Away
Sep 29, 2020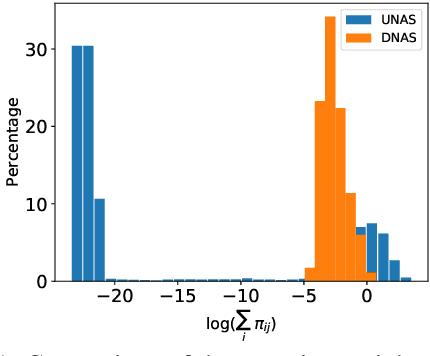

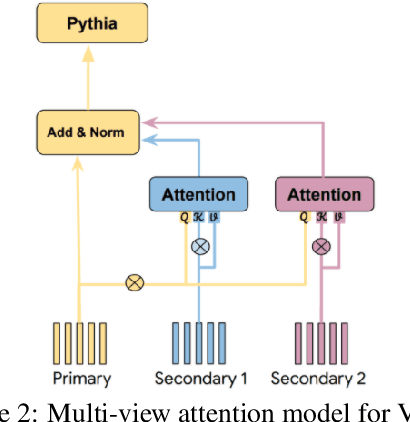

Models based on the Transformer architecture have achieved better accuracy than the ones based on competing architectures for a large set of tasks. A unique feature of the Transformer is its universal application of a self-attention mechanism, which allows for free information flow at arbitrary distances. Following a probabilistic view of the attention via the Gaussian mixture model, we find empirical evidence that the Transformer attention tends to "explain away" certain input neurons. To compensate for this, we propose a doubly-normalized attention scheme that is simple to implement and provides theoretical guarantees for avoiding the "explaining away" effect without introducing significant computational or memory cost. Empirically, we show that the new attention schemes result in improved performance on several well-known benchmarks.
Adaptive Correlated Monte Carlo for Contextual Categorical Sequence Generation
Dec 31, 2019


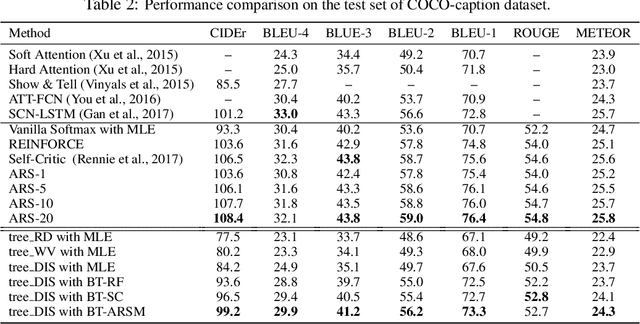
Sequence generation models are commonly refined with reinforcement learning over user-defined metrics. However, high gradient variance hinders the practical use of this method. To stabilize this method, we adapt to contextual generation of categorical sequences a policy gradient estimator, which evaluates a set of correlated Monte Carlo (MC) rollouts for variance control. Due to the correlation, the number of unique rollouts is random and adaptive to model uncertainty; those rollouts naturally become baselines for each other, and hence are combined to effectively reduce gradient variance. We also demonstrate the use of correlated MC rollouts for binary-tree softmax models, which reduce the high generation cost in large vocabulary scenarios by decomposing each categorical action into a sequence of binary actions. We evaluate our methods on both neural program synthesis and image captioning. The proposed methods yield lower gradient variance and consistent improvement over related baselines.
A Unified Framework for Tuning Hyperparameters in Clustering Problems
Oct 17, 2019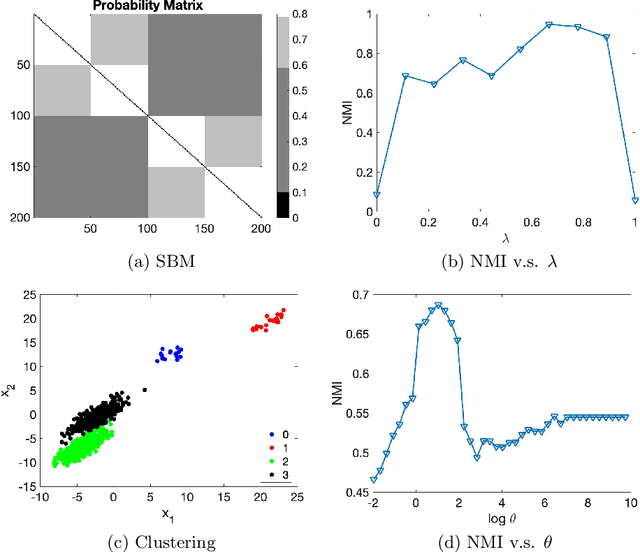
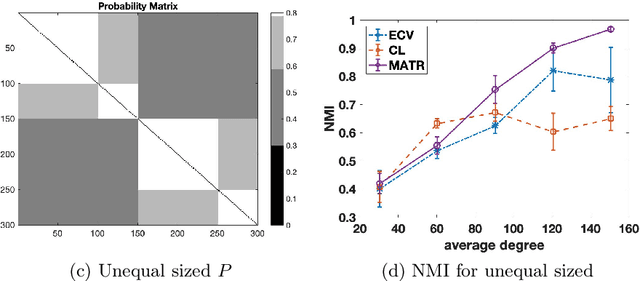
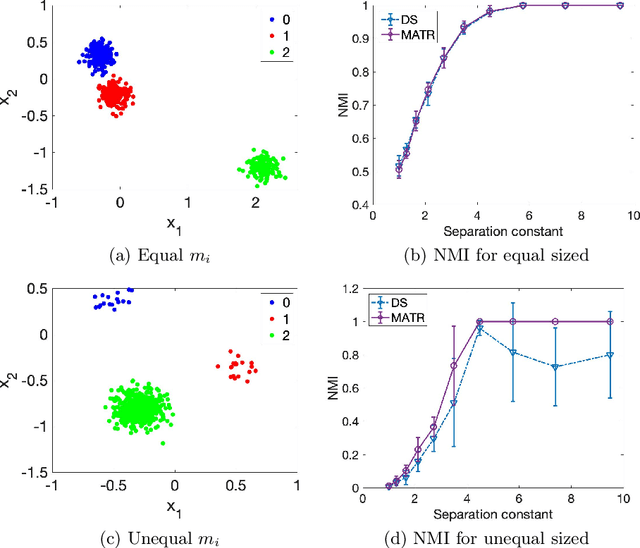
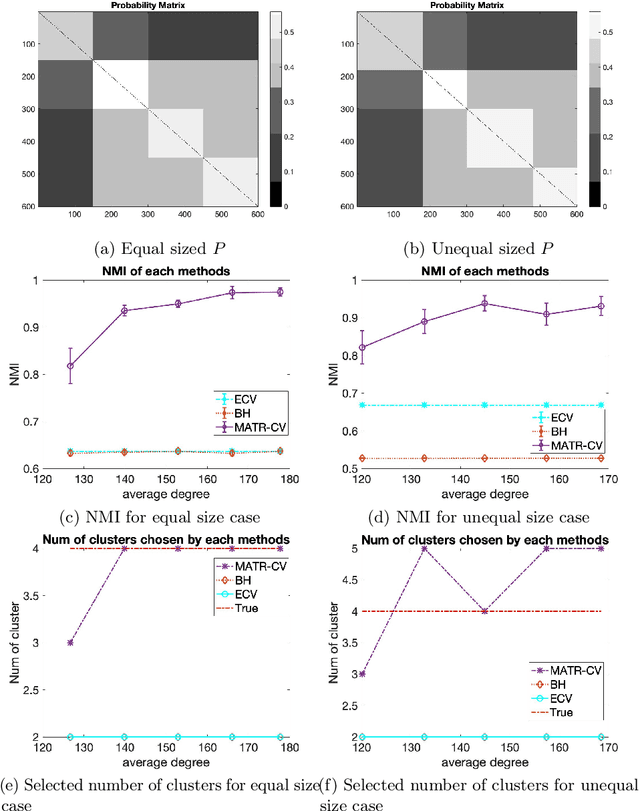
Selecting hyperparameters for unsupervised learning problems is difficult in general due to the lack of ground truth for validation. However, this issue is prevalent in machine learning, especially in clustering problems with examples including the Lagrange multipliers of penalty terms in semidefinite programming (SDP) relaxations and the bandwidths used for constructing kernel similarity matrices for Spectral Clustering. Despite this, there are not many provable algorithms for tuning these hyperparameters. In this paper, we provide a unified framework with provable guarantees for the above class of problems. We demonstrate our method on two distinct models. First, we show how to tune the hyperparameters in widely used SDP algorithms for community detection in networks. In this case, our method can also be used for model selection. Second, we show the same framework works for choosing the bandwidth for the kernel similarity matrix in Spectral Clustering for subgaussian mixtures under suitable model specification. In a variety of simulation experiments, we show that our framework outperforms other widely used tuning procedures in a broad range of parameter settings.