 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Parallel Samplers in Masked Diffusion via Random Walks on Graphs
Jun 22, 2026In this paper, we propose using random walks on graphs as a verifiable sandbox to study different parallel sampling strategies in masked diffusion models (MDMs). We train an MDM on random walk samples from a fixed graph. The graph or the transition kernel is never shown to the model explicitly and plays the role of latent structure in the sequences, albeit one that is controllable and can be used for quantitative evaluation. Thus, this framework enjoys a Sudoku-like validity check: verifying that an output is a valid walk and estimating the Markov kernel from the walks to measure distribution fidelity. Using simple graphs, we theoretically prove that parallel unmasking via widely used scores like lowest entropy is not uniformly better than a random parallel sampler; the performance critically depends on the structure of the underlying graph. We develop a new bisection sampler for random walks, which takes logarithmic steps in the sequence length and is provably exact under perfect training. Experiments on various graph walk tasks show that different parallel samplers are better for different graphs even in practice. Our initial experiments on a pretrained OpenWebText MDM show that the bisection-style samplers improve speed-quality tradeoffs even for language generation. Together, these results position graph random walks as a mechanistic benchmark for diagnosing and designing parallel samplers for masked diffusion models.
On the Curse of Dimensionality in Private Sparse Covariance Estimation and PCA
Jun 20, 2026We study high-dimensional differentially private (DP) covariance estimation in the operator norm, and principal component analysis (PCA), under $k$-row-column sparsity ($k$-RCS) of the covariance matrix. In the non-private setting, it is known that $\mathsf{poly}(k, \log d)$ samples suffice to solve both of these problems. However, the only comparable result known under DP (Wang et al. 2021) requires $Ω(d)$ samples under standard parameterizations of the problem. We investigate when this curse of dimensionality is inherent for sparse covariance estimation tasks under DP. On the upper bound front, we show that a $\mathsf{poly}(k, \log d)$ sample complexity for PCA is possible under DP, if we also posit sparsity of the leading eigenvector. We complement this result with $\mathsf{poly}(d)$ lower bounds under DP for both sparse covariance estimation and PCA, establishing an exponential gap between the private and non-private variants of these problems when $k = \mathsf{polylog}(d)$. To our knowledge, no such separation has previously been demonstrated for any sparse estimation problems in private high-dimensional statistics. Our techniques are flexible enough that they imply stronger lower bounds even for the well-studied problem of standard DP PCA, without sparsity assumptions.
Combinatorial Sparse PCA Beyond the Spiked Identity Model
Mar 03, 2026Sparse PCA is one of the most well-studied problems in high-dimensional statistics. In this problem, we are given samples from a distribution with covariance $Σ$, whose top eigenvector $v \in R^d$ is $s$-sparse. Existing sparse PCA algorithms can be broadly categorized into (1) combinatorial algorithms (e.g., diagonal or elementwise covariance thresholding) and (2) SDP-based algorithms. While combinatorial algorithms are much simpler, they are typically only analyzed under the spiked identity model (where $Σ= I_d + γvv^\top$ for some $γ> 0$), whereas SDP-based algorithms require no additional assumptions on $Σ$. We demonstrate explicit counterexample covariances $Σ$ against the success of standard combinatorial algorithms for sparse PCA, when moving beyond the spiked identity model. In light of this discrepancy, we give the first combinatorial method for sparse PCA that provably succeeds for general $Σ$ using $s^2 \cdot \mathrm{polylog}(d)$ samples and $d^2 \cdot \mathrm{poly}(s, \log(d))$ time, by providing a global convergence guarantee on a variant of the truncated power method of Yuan and Zhang (2013). We provide a natural generalization of our method to recovering a vector in a sparse leading eigenspace. Finally, we evaluate our method on synthetic and real-world sparse PCA datasets.
Low-Dimensional Adaptation of Rectified Flow: A New Perspective through the Lens of Diffusion and Stochastic Localization
Jan 21, 2026In recent years, Rectified flow (RF) has gained considerable popularity largely due to its generation efficiency and state-of-the-art performance. In this paper, we investigate the degree to which RF automatically adapts to the intrinsic low dimensionality of the support of the target distribution to accelerate sampling. We show that, using a carefully designed choice of the time-discretization scheme and with sufficiently accurate drift estimates, the RF sampler enjoys an iteration complexity of order $O(k/\varepsilon)$ (up to log factors), where $\varepsilon$ is the precision in total variation distance and $k$ is the intrinsic dimension of the target distribution. In addition, we show that the denoising diffusion probabilistic model (DDPM) procedure is equivalent to a stochastic version of RF by establishing a novel connection between these processes and stochastic localization. Building on this connection, we further design a stochastic RF sampler that also adapts to the low-dimensionality of the target distribution under milder requirements on the accuracy of the drift estimates, and also with a specific time schedule. We illustrate with simulations on the synthetic data and text-to-image data experiments the improved performance of the proposed samplers implementing the newly designed time-discretization schedules.
Low-Precision Streaming PCA
Oct 25, 2025Low-precision streaming PCA estimates the top principal component in a streaming setting under limited precision. We establish an information-theoretic lower bound on the quantization resolution required to achieve a target accuracy for the leading eigenvector. We study Oja's algorithm for streaming PCA under linear and nonlinear stochastic quantization. The quantized variants use unbiased stochastic quantization of the weight vector and the updates. Under mild moment and spectral-gap assumptions on the data distribution, we show that a batched version achieves the lower bound up to logarithmic factors under both schemes. This leads to a nearly dimension-free quantization error in the nonlinear quantization setting. Empirical evaluations on synthetic streams validate our theoretical findings and demonstrate that our low-precision methods closely track the performance of standard Oja's algorithm.
Beyond Sin-Squared Error: Linear-Time Entrywise Uncertainty Quantification for Streaming PCA
Jun 14, 2025We propose a novel statistical inference framework for streaming principal component analysis (PCA) using Oja's algorithm, enabling the construction of confidence intervals for individual entries of the estimated eigenvector. Most existing works on streaming PCA focus on providing sharp sin-squared error guarantees. Recently, there has been some interest in uncertainty quantification for the sin-squared error. However, uncertainty quantification or sharp error guarantees for entries of the estimated eigenvector in the streaming setting remains largely unexplored. We derive a sharp Bernstein-type concentration bound for elements of the estimated vector matching the optimal error rate up to logarithmic factors. We also establish a Central Limit Theorem for a suitably centered and scaled subset of the entries. To efficiently estimate the coordinate-wise variance, we introduce a provably consistent subsampling algorithm that leverages the median-of-means approach, empirically achieving similar accuracy to multiplier bootstrap methods while being significantly more computationally efficient. Numerical experiments demonstrate its effectiveness in providing reliable uncertainty estimates with a fraction of the computational cost of existing methods.
Spike-and-Slab Posterior Sampling in High Dimensions
Mar 04, 2025Posterior sampling with the spike-and-slab prior [MB88], a popular multimodal distribution used to model uncertainty in variable selection, is considered the theoretical gold standard method for Bayesian sparse linear regression [CPS09, Roc18]. However, designing provable algorithms for performing this sampling task is notoriously challenging. Existing posterior samplers for Bayesian sparse variable selection tasks either require strong assumptions about the signal-to-noise ratio (SNR) [YWJ16], only work when the measurement count grows at least linearly in the dimension [MW24], or rely on heuristic approximations to the posterior. We give the first provable algorithms for spike-and-slab posterior sampling that apply for any SNR, and use a measurement count sublinear in the problem dimension. Concretely, assume we are given a measurement matrix $\mathbf{X} \in \mathbb{R}^{n\times d}$ and noisy observations $\mathbf{y} = \mathbf{X}\mathbf{\theta}^\star + \mathbf{\xi}$ of a signal $\mathbf{\theta}^\star$ drawn from a spike-and-slab prior $\pi$ with a Gaussian diffuse density and expected sparsity k, where $\mathbf{\xi} \sim \mathcal{N}(\mathbb{0}_n, \sigma^2\mathbf{I}_n)$. We give a polynomial-time high-accuracy sampler for the posterior $\pi(\cdot \mid \mathbf{X}, \mathbf{y})$, for any SNR $\sigma^{-1}$ > 0, as long as $n \geq k^3 \cdot \text{polylog}(d)$ and $X$ is drawn from a matrix ensemble satisfying the restricted isometry property. We further give a sampler that runs in near-linear time $\approx nd$ in the same setting, as long as $n \geq k^5 \cdot \text{polylog}(d)$. To demonstrate the flexibility of our framework, we extend our result to spike-and-slab posterior sampling with Laplace diffuse densities, achieving similar guarantees when $\sigma = O(\frac{1}{k})$ is bounded.
Straightness of Rectified Flow: A Theoretical Insight into Wasserstein Convergence
Oct 19, 2024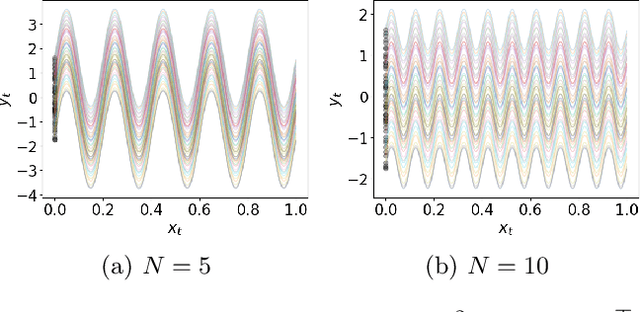
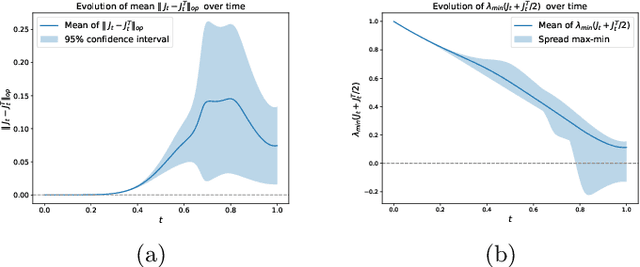

Diffusion models have emerged as a powerful tool for image generation and denoising. Typically, generative models learn a trajectory between the starting noise distribution and the target data distribution. Recently Liu et al. (2023b) designed a novel alternative generative model Rectified Flow (RF), which aims to learn straight flow trajectories from noise to data using a sequence of convex optimization problems with close ties to optimal transport. If the trajectory is curved, one must use many Euler discretization steps or novel strategies, such as exponential integrators, to achieve a satisfactory generation quality. In contrast, RF has been shown to theoretically straighten the trajectory through successive rectifications, reducing the number of function evaluations (NFEs) while sampling. It has also been shown empirically that RF may improve the straightness in two rectifications if one can solve the underlying optimization problem within a sufficiently small error. In this paper, we make two key theoretical contributions: 1) we provide the first theoretical analysis of the Wasserstein distance between the sampling distribution of RF and the target distribution. Our error rate is characterized by the number of discretization steps and a new formulation of straightness stronger than that in the original work. 2) In line with the previous empirical findings, we show that, for a rectified flow from a Gaussian to a mixture of two Gaussians, two rectifications are sufficient to achieve a straight flow. Additionally, we also present empirical results on both simulated and real datasets to validate our theoretical findings.
On Differentially Private U Statistics
Jul 06, 2024


We consider the problem of privately estimating a parameter $\mathbb{E}[h(X_1,\dots,X_k)]$, where $X_1$, $X_2$, $\dots$, $X_k$ are i.i.d. data from some distribution and $h$ is a permutation-invariant function. Without privacy constraints, standard estimators are U-statistics, which commonly arise in a wide range of problems, including nonparametric signed rank tests, symmetry testing, uniformity testing, and subgraph counts in random networks, and can be shown to be minimum variance unbiased estimators under mild conditions. Despite the recent outpouring of interest in private mean estimation, privatizing U-statistics has received little attention. While existing private mean estimation algorithms can be applied to obtain confidence intervals, we show that they can lead to suboptimal private error, e.g., constant-factor inflation in the leading term, or even $\Theta(1/n)$ rather than $O(1/n^2)$ in degenerate settings. To remedy this, we propose a new thresholding-based approach using \emph{local H\'ajek projections} to reweight different subsets of the data. This leads to nearly optimal private error for non-degenerate U-statistics and a strong indication of near-optimality for degenerate U-statistics.
Transfer Learning for Latent Variable Network Models
Jun 06, 2024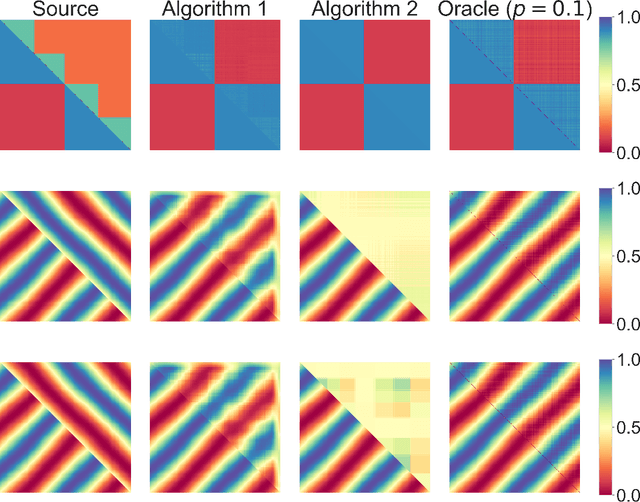
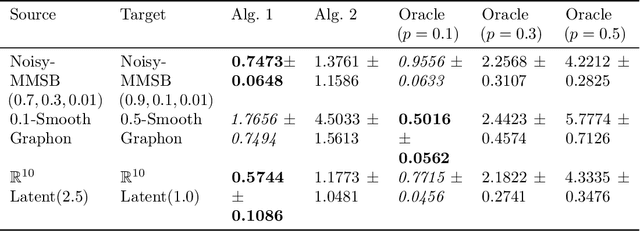
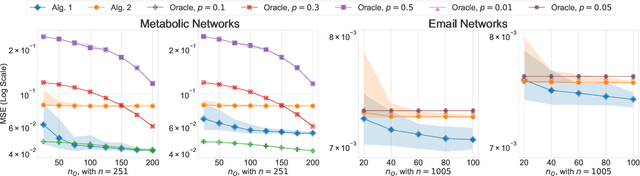
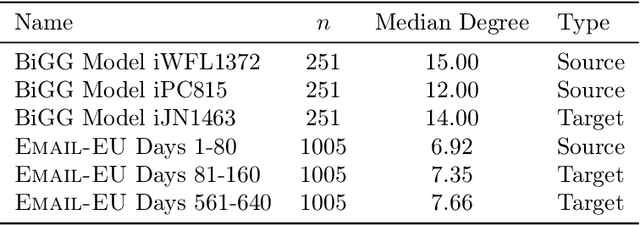
We study transfer learning for estimation in latent variable network models. In our setting, the conditional edge probability matrices given the latent variables are represented by $P$ for the source and $Q$ for the target. We wish to estimate $Q$ given two kinds of data: (1) edge data from a subgraph induced by an $o(1)$ fraction of the nodes of $Q$, and (2) edge data from all of $P$. If the source $P$ has no relation to the target $Q$, the estimation error must be $\Omega(1)$. However, we show that if the latent variables are shared, then vanishing error is possible. We give an efficient algorithm that utilizes the ordering of a suitably defined graph distance. Our algorithm achieves $o(1)$ error and does not assume a parametric form on the source or target networks. Next, for the specific case of Stochastic Block Models we prove a minimax lower bound and show that a simple algorithm achieves this rate. Finally, we empirically demonstrate our algorithm's use on real-world and simulated graph transfer problems.