 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Precision Streaming PCA
Oct 25, 2025Low-precision streaming PCA estimates the top principal component in a streaming setting under limited precision. We establish an information-theoretic lower bound on the quantization resolution required to achieve a target accuracy for the leading eigenvector. We study Oja's algorithm for streaming PCA under linear and nonlinear stochastic quantization. The quantized variants use unbiased stochastic quantization of the weight vector and the updates. Under mild moment and spectral-gap assumptions on the data distribution, we show that a batched version achieves the lower bound up to logarithmic factors under both schemes. This leads to a nearly dimension-free quantization error in the nonlinear quantization setting. Empirical evaluations on synthetic streams validate our theoretical findings and demonstrate that our low-precision methods closely track the performance of standard Oja's algorithm.
Beyond Sin-Squared Error: Linear-Time Entrywise Uncertainty Quantification for Streaming PCA
Jun 14, 2025We propose a novel statistical inference framework for streaming principal component analysis (PCA) using Oja's algorithm, enabling the construction of confidence intervals for individual entries of the estimated eigenvector. Most existing works on streaming PCA focus on providing sharp sin-squared error guarantees. Recently, there has been some interest in uncertainty quantification for the sin-squared error. However, uncertainty quantification or sharp error guarantees for entries of the estimated eigenvector in the streaming setting remains largely unexplored. We derive a sharp Bernstein-type concentration bound for elements of the estimated vector matching the optimal error rate up to logarithmic factors. We also establish a Central Limit Theorem for a suitably centered and scaled subset of the entries. To efficiently estimate the coordinate-wise variance, we introduce a provably consistent subsampling algorithm that leverages the median-of-means approach, empirically achieving similar accuracy to multiplier bootstrap methods while being significantly more computationally efficient. Numerical experiments demonstrate its effectiveness in providing reliable uncertainty estimates with a fraction of the computational cost of existing methods.
Private Geometric Median in Nearly-Linear Time
May 26, 2025Estimating the geometric median of a dataset is a robust counterpart to mean estimation, and is a fundamental problem in computational geometry. Recently, [HSU24] gave an $(\varepsilon, \delta)$-differentially private algorithm obtaining an $\alpha$-multiplicative approximation to the geometric median objective, $\frac 1 n \sum_{i \in [n]} \|\cdot - \mathbf{x}_i\|$, given a dataset $\mathcal{D} := \{\mathbf{x}_i\}_{i \in [n]} \subset \mathbb{R}^d$. Their algorithm requires $n \gtrsim \sqrt d \cdot \frac 1 {\alpha\varepsilon}$ samples, which they prove is information-theoretically optimal. This result is surprising because its error scales with the \emph{effective radius} of $\mathcal{D}$ (i.e., of a ball capturing most points), rather than the worst-case radius. We give an improved algorithm that obtains the same approximation quality, also using $n \gtrsim \sqrt d \cdot \frac 1 {\alpha\epsilon}$ samples, but in time $\widetilde{O}(nd + \frac d {\alpha^2})$. Our runtime is nearly-linear, plus the cost of the cheapest non-private first-order method due to [CLM+16]. To achieve our results, we use subsampling and geometric aggregation tools inspired by FriendlyCore [TCK+22] to speed up the "warm start" component of the [HSU24] algorithm, combined with a careful custom analysis of DP-SGD's sensitivity for the geometric median objective.
Spike-and-Slab Posterior Sampling in High Dimensions
Mar 04, 2025Posterior sampling with the spike-and-slab prior [MB88], a popular multimodal distribution used to model uncertainty in variable selection, is considered the theoretical gold standard method for Bayesian sparse linear regression [CPS09, Roc18]. However, designing provable algorithms for performing this sampling task is notoriously challenging. Existing posterior samplers for Bayesian sparse variable selection tasks either require strong assumptions about the signal-to-noise ratio (SNR) [YWJ16], only work when the measurement count grows at least linearly in the dimension [MW24], or rely on heuristic approximations to the posterior. We give the first provable algorithms for spike-and-slab posterior sampling that apply for any SNR, and use a measurement count sublinear in the problem dimension. Concretely, assume we are given a measurement matrix $\mathbf{X} \in \mathbb{R}^{n\times d}$ and noisy observations $\mathbf{y} = \mathbf{X}\mathbf{\theta}^\star + \mathbf{\xi}$ of a signal $\mathbf{\theta}^\star$ drawn from a spike-and-slab prior $\pi$ with a Gaussian diffuse density and expected sparsity k, where $\mathbf{\xi} \sim \mathcal{N}(\mathbb{0}_n, \sigma^2\mathbf{I}_n)$. We give a polynomial-time high-accuracy sampler for the posterior $\pi(\cdot \mid \mathbf{X}, \mathbf{y})$, for any SNR $\sigma^{-1}$ > 0, as long as $n \geq k^3 \cdot \text{polylog}(d)$ and $X$ is drawn from a matrix ensemble satisfying the restricted isometry property. We further give a sampler that runs in near-linear time $\approx nd$ in the same setting, as long as $n \geq k^5 \cdot \text{polylog}(d)$. To demonstrate the flexibility of our framework, we extend our result to spike-and-slab posterior sampling with Laplace diffuse densities, achieving similar guarantees when $\sigma = O(\frac{1}{k})$ is bounded.
Black-Box $k$-to-$1$-PCA Reductions: Theory and Applications
Mar 07, 2024The $k$-principal component analysis ($k$-PCA) problem is a fundamental algorithmic primitive that is widely-used in data analysis and dimensionality reduction applications. In statistical settings, the goal of $k$-PCA is to identify a top eigenspace of the covariance matrix of a distribution, which we only have implicit access to via samples. Motivated by these implicit settings, we analyze black-box deflation methods as a framework for designing $k$-PCA algorithms, where we model access to the unknown target matrix via a black-box $1$-PCA oracle which returns an approximate top eigenvector, under two popular notions of approximation. Despite being arguably the most natural reduction-based approach to $k$-PCA algorithm design, such black-box methods, which recursively call a $1$-PCA oracle $k$ times, were previously poorly-understood. Our main contribution is significantly sharper bounds on the approximation parameter degradation of deflation methods for $k$-PCA. For a quadratic form notion of approximation we term ePCA (energy PCA), we show deflation methods suffer no parameter loss. For an alternative well-studied approximation notion we term cPCA (correlation PCA), we tightly characterize the parameter regimes where deflation methods are feasible. Moreover, we show that in all feasible regimes, $k$-cPCA deflation algorithms suffer no asymptotic parameter loss for any constant $k$. We apply our framework to obtain state-of-the-art $k$-PCA algorithms robust to dataset contamination, improving prior work both in sample complexity and approximation quality.
Thresholded Oja does Sparse PCA?
Feb 20, 2024We consider the problem of Sparse Principal Component Analysis (PCA) when the ratio $d/n \rightarrow c > 0$. There has been a lot of work on optimal rates on sparse PCA in the offline setting, where all the data is available for multiple passes. In contrast, when the population eigenvector is $s$-sparse, streaming algorithms that have $O(d)$ storage and $O(nd)$ time complexity either typically require strong initialization conditions or have a suboptimal error. We show that a simple algorithm that thresholds and renormalizes the output of Oja's algorithm (the Oja vector) obtains a near-optimal error rate. This is very surprising because, without thresholding, the Oja vector has a large error. Our analysis centers around bounding the entries of the unnormalized Oja vector, which involves the projection of a product of independent random matrices on a random initial vector. This is nontrivial and novel since previous analyses of Oja's algorithm and matrix products have been done when the trace of the population covariance matrix is bounded while in our setting, this quantity can be as large as $n$.
Keep or toss? A nonparametric score to evaluate solutions for noisy ICA
Jan 16, 2024In this paper, we propose a non-parametric score to evaluate the quality of the solution to an iterative algorithm for Independent Component Analysis (ICA) with arbitrary Gaussian noise. The novelty of this score stems from the fact that it just assumes a finite second moment of the data and uses the characteristic function to evaluate the quality of the estimated mixing matrix without any knowledge of the parameters of the noise distribution. We also provide a new characteristic function-based contrast function for ICA and propose a fixed point iteration to optimize the corresponding objective function. Finally, we propose a theoretical framework to obtain sufficient conditions for the local and global optima of a family of contrast functions for ICA. This framework uses quasi-orthogonalization inherently, and our results extend the classical analysis of cumulant-based objective functions to noisy ICA. We demonstrate the efficacy of our algorithms via experimental results on simulated datasets.
Streaming PCA for Markovian Data
May 03, 2023Since its inception in Erikki Oja's seminal paper in 1982, Oja's algorithm has become an established method for streaming principle component analysis (PCA). We study the problem of streaming PCA, where the data-points are sampled from an irreducible, aperiodic, and reversible Markov chain. Our goal is to estimate the top eigenvector of the unknown covariance matrix of the stationary distribution. This setting has implications in situations where data can only be sampled from a Markov Chain Monte Carlo (MCMC) type algorithm, and the goal is to do inference for parameters of the stationary distribution of this chain. Most convergence guarantees for Oja's algorithm in the literature assume that the data-points are sampled IID. For data streams with Markovian dependence, one typically downsamples the data to get a "nearly" independent data stream. In this paper, we obtain the first sharp rate for Oja's algorithm on the entire data, where we remove the logarithmic dependence on $n$ resulting from throwing data away in downsampling strategies.
From Machine Translation to Code-Switching: Generating High-Quality Code-Switched Text
Jul 14, 2021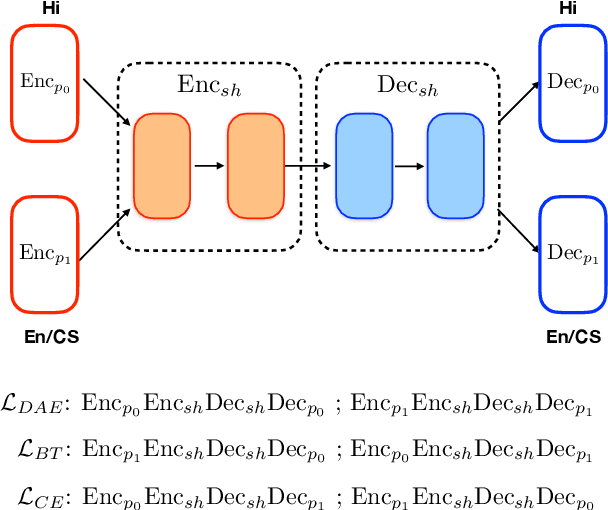


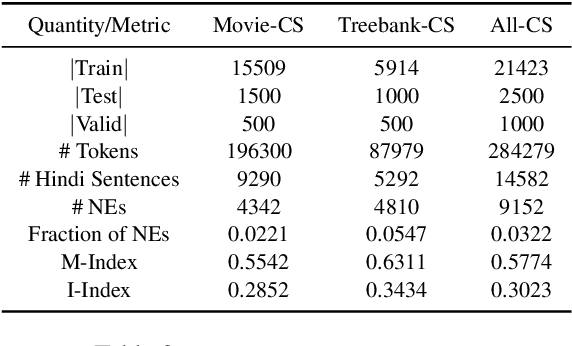
Generating code-switched text is a problem of growing interest, especially given the scarcity of corpora containing large volumes of real code-switched text. In this work, we adapt a state-of-the-art neural machine translation model to generate Hindi-English code-switched sentences starting from monolingual Hindi sentences. We outline a carefully designed curriculum of pretraining steps, including the use of synthetic code-switched text, that enable the model to generate high-quality code-switched text. Using text generated from our model as data augmentation, we show significant reductions in perplexity on a language modeling task, compared to using text from other generative models of CS text. We also show improvements using our text for a downstream code-switched natural language inference task. Our generated text is further subjected to a rigorous evaluation using a human evaluation study and a range of objective metrics, where we show performance comparable (and sometimes even superior) to code-switched text obtained via crowd workers who are native Hindi speakers.