 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exponentially Increasing Step-size for Parameter Estimation in Statistical Models
Paper and Code
May 16, 2022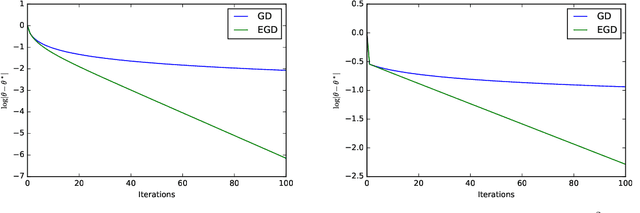
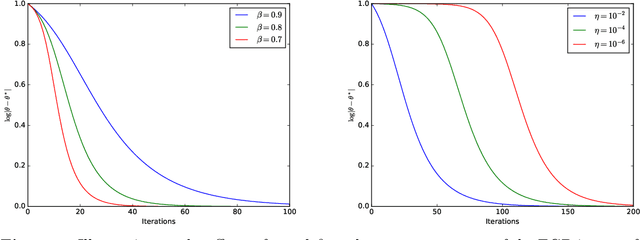
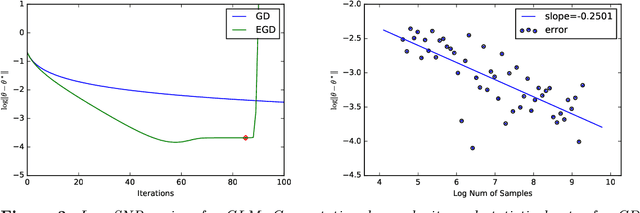
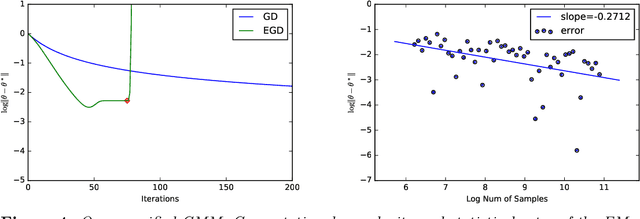
Using gradient descent (GD) with fixed or decaying step-size is standard practice in unconstrained optimization problems. However, when the loss function is only locally convex, such a step-size schedule artificially slows GD down as it cannot explore the flat curvature of the loss function. To overcome that issue, we propose to exponentially increase the step-size of the GD algorithm. Under homogeneous assumptions on the loss function, we demonstrate that the iterates of the proposed \emph{exponential step size gradient descent} (EGD) algorithm converge linearly to the optimal solution. Leveraging that optimization insight, we then consider using the EGD algorithm for solving parameter estimation under non-regular statistical models whose the loss function becomes locally convex when the sample size goes to infinity. We demonstrate that the EGD iterates reach the final statistical radius within the true parameter after a logarithmic number of iterations, which is in stark contrast to a \emph{polynomial} number of iterations of the GD algorithm. Therefore, the total computational complexity of the EGD algorithm is \emph{optimal} and exponentially cheaper than that of the GD for solving parameter estimation in non-regular statistical models. To the best of our knowledge, it resolves a long-standing gap between statistical and algorithmic computational complexities of parameter estimation in non-regular statistical models. Finally, we provide targeted applications of the general theory to several classes of statistical models, including generalized linear models with polynomial link functions and location Gaussian mixture models.