 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQVLA: Not All Channels Are Equal in Vision-Language-Action Model's Quantization
Feb 03, 2026The advent of Vision-Language-Action (VLA) models represents a significant leap for embodied intelligence, yet their immense computational demands critically hinder deployment on resource-constrained robotic platforms. Intuitively, low-bit quantization is a prevalent and preferred technique for large-scale model compression. However, we find that a systematic analysis of VLA model's quantization is fundamentally lacking. We argue that naively applying uniform-bit quantization from Large Language Models (LLMs) to robotics is flawed, as these methods prioritize passive data fidelity while ignoring how minor action deviations compound into catastrophic task failures. To bridge this gap, we introduce QVLA, the first action-centric quantization framework specifically designed for embodied control. In a sharp departure from the rigid, uniform-bit quantization of LLM-based methods, QVLA introduces a highly granular, channel-wise bit allocation strategy. Its core mechanism is to directly measure the final action-space sensitivity when quantizing each individual channel to various bit-widths. This process yields a precise, per-channel importance metric that guides a global optimization, which elegantly unifies quantization and pruning (0-bit) into a single, cohesive framework. Extensive evaluations on different baselines demonstrate the superiority of our approach. In the LIBERO, the quantization version of OpenVLA-OFT with our method requires only 29.2% of the original model's VRAM while maintaining 98.9% of its original performance and achieving a 1.49x speedup. This translates to a 22.6% performance improvement over the LLM-derived method SmoothQuant. Our work establishes a new, principled foundation for compressing VLA models in robotics, paving the way for deploying powerful, large-scale models on real-world hardware. Code will be released.
Grounding and Enhancing Informativeness and Utility in Dataset Distillation
Jan 29, 2026Dataset Distillation (DD) seeks to create a compact dataset from a large, real-world dataset. While recent methods often rely on heuristic approaches to balance efficiency and quality, the fundamental relationship between original and synthetic data remains underexplored. This paper revisits knowledge distillation-based dataset distillation within a solid theoretical framework. We introduce the concepts of Informativeness and Utility, capturing crucial information within a sample and essential samples in the training set, respectively. Building on these principles, we define optimal dataset distillation mathematically. We then present InfoUtil, a framework that balances informativeness and utility in synthesizing the distilled dataset. InfoUtil incorporates two key components: (1) game-theoretic informativeness maximization using Shapley Value attribution to extract key information from samples, and (2) principled utility maximization by selecting globally influential samples based on Gradient Norm. These components ensure that the distilled dataset is both informative and utility-optimized. Experiments demonstrate that our method achieves a 6.1\% performance improvement over the previous state-of-the-art approach on ImageNet-1K dataset using ResNet-18.
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
Jan 05, 2026The grand vision of enabling persistent, large-scale 3D visual geometry understanding is shackled by the irreconcilable demands of scalability and long-term stability. While offline models like VGGT achieve inspiring geometry capability, their batch-based nature renders them irrelevant for live systems. Streaming architectures, though the intended solution for live operation, have proven inadequate. Existing methods either fail to support truly infinite-horizon inputs or suffer from catastrophic drift over long sequences. We shatter this long-standing dilemma with InfiniteVGGT, a causal visual geometry transformer that operationalizes the concept of a rolling memory through a bounded yet adaptive and perpetually expressive KV cache. Capitalizing on this, we devise a training-free, attention-agnostic pruning strategy that intelligently discards obsolete information, effectively ``rolling'' the memory forward with each new frame. Fully compatible with FlashAttention, InfiniteVGGT finally alleviates the compromise, enabling infinite-horizon streaming while outperforming existing streaming methods in long-term stability. The ultimate test for such a system is its performance over a truly infinite horizon, a capability that has been impossible to rigorously validate due to the lack of extremely long-term, continuous benchmarks. To address this critical gap, we introduce the Long3D benchmark, which, for the first time, enables a rigorous evaluation of continuous 3D geometry estimation on sequences about 10,000 frames. This provides the definitive evaluation platform for future research in long-term 3D geometry understanding. Code is available at: https://github.com/AutoLab-SAI-SJTU/InfiniteVGGT
EfficientVLA: Training-Free Acceleration and Compression for Vision-Language-Action Models
Jun 11, 2025
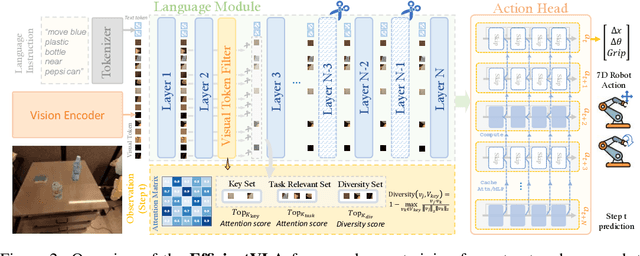

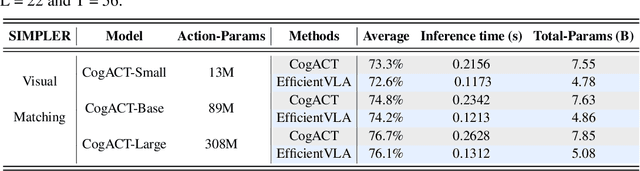
Vision-Language-Action (VLA) models, particularly diffusion-based architectures, demonstrate transformative potential for embodied intelligence but are severely hampered by high computational and memory demands stemming from extensive inherent and inference-time redundancies. While existing acceleration efforts often target isolated inefficiencies, such piecemeal solutions typically fail to holistically address the varied computational and memory bottlenecks across the entire VLA pipeline, thereby limiting practical deployability. We introduce EfficientVLA, a structured and training-free inference acceleration framework that systematically eliminates these barriers by cohesively exploiting multifaceted redundancies. EfficientVLA synergistically integrates three targeted strategies: (1) pruning of functionally inconsequential layers from the language module, guided by an analysis of inter-layer redundancies; (2) optimizing the visual processing pathway through a task-aware strategy that selects a compact, diverse set of visual tokens, balancing task-criticality with informational coverage; and (3) alleviating temporal computational redundancy within the iterative diffusion-based action head by strategically caching and reusing key intermediate features. We apply our method to a standard VLA model CogACT, yielding a 1.93X inference speedup and reduces FLOPs to 28.9%, with only a 0.6% success rate drop in the SIMPLER benchmark.
DRUPI: Dataset Reduction Using Privileged Information
Oct 02, 2024



Dataset reduction (DR) seeks to select or distill samples from large datasets into smaller subsets while preserving performance on target tasks. Existing methods primarily focus on pruning or synthesizing data in the same format as the original dataset, typically the input data and corresponding labels. However, in DR settings, we find it is possible to synthesize more information beyond the data-label pair as an additional learning target to facilitate model training. In this paper, we introduce Dataset Reduction Using Privileged Information (DRUPI), which enriches DR by synthesizing privileged information alongside the reduced dataset. This privileged information can take the form of feature labels or attention labels, providing auxiliary supervision to improve model learning. Our findings reveal that effective feature labels must balance between being overly discriminative and excessively diverse, with a moderate level proving optimal for improving the reduced dataset's efficacy. Extensive experiments on ImageNet, CIFAR-10/100, and Tiny ImageNet demonstrate that DRUPI integrates seamlessly with existing dataset reduction methods, offering significant performance gains.
Not All Samples Should Be Utilized Equally: Towards Understanding and Improving Dataset Distillation
Aug 22, 2024Dataset Distillation (DD) aims to synthesize a small dataset capable of performing comparably to the original dataset. Despite the success of numerous DD methods, theoretical exploration of this area remains unaddressed. In this paper, we take an initial step towards understanding various matching-based DD methods from the perspective of sample difficulty. We begin by empirically examining sample difficulty, measured by gradient norm, and observe that different matching-based methods roughly correspond to specific difficulty tendencies. We then extend the neural scaling laws of data pruning to DD to theoretically explain these matching-based methods. Our findings suggest that prioritizing the synthesis of easier samples from the original dataset can enhance the quality of distilled datasets, especially in low IPC (image-per-class) settings. Based on our empirical observations and theoretical analysis, we introduce the Sample Difficulty Correction (SDC) approach, designed to predominantly generate easier samples to achieve higher dataset quality. Our SDC can be seamlessly integrated into existing methods as a plugin with minimal code adjustments. Experimental results demonstrate that adding SDC generates higher-quality distilled datasets across 7 distillation methods and 6 datasets.