 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVLN: Omnidirectional 3D Perception and Token-Efficient LLM Reasoning for Visual-Language Navigation across Air and Ground Platforms
Mar 18, 2026Language-guided embodied navigation requires an agent to interpret object-referential instructions, search across multiple rooms, localize the referenced target, and execute reliable motion toward it. Existing systems remain limited in real indoor environments because narrow field-of-view sensing exposes only a partial local scene at each step, often forcing repeated rotations, delaying target discovery, and producing fragmented spatial understanding; meanwhile, directly prompting LLMs with dense 3D maps or exhaustive object lists quickly exceeds the context budget. We present OmniVLN, a zero-shot visual-language navigation framework that couples omnidirectional 3D perception with token-efficient hierarchical reasoning for both aerial and ground robots. OmniVLN fuses a rotating LiDAR and panoramic vision into a hardware-agnostic mapping stack, incrementally constructs a five-layer Dynamic Scene Graph (DSG) from mesh geometry to room- and building-level structure, and stabilizes high-level topology through persistent-homology-based room partitioning and hybrid geometric/VLM relation verification. For navigation, the global DSG is transformed into an agent-centric 3D octant representation with multi-resolution spatial attention prompting, enabling the LLM to progressively filter candidate rooms, infer egocentric orientation, localize target objects, and emit executable navigation primitives while preserving fine local detail and compact long-range memory. Experiments show that the proposed hierarchical interface improves spatial referring accuracy from 77.27\% to 93.18\%, reduces cumulative prompt tokens by up to 61.7\% in cluttered multi-room settings, and improves navigation success by up to 11.68\% over a flat-list baseline. We will release the code and an omnidirectional multimodal dataset to support reproducible research.
Aerial Manipulation with Contact-Aware Onboard Perception and Hybrid Control
Feb 09, 2026Aerial manipulation (AM) promises to move Unmanned Aerial Vehicles (UAVs) beyond passive inspection to contact-rich tasks such as grasping, assembly, and in-situ maintenance. Most prior AM demonstrations rely on external motion capture (MoCap) and emphasize position control for coarse interactions, limiting deployability. We present a fully onboard perception-control pipeline for contact-rich AM that achieves accurate motion tracking and regulated contact wrenches without MoCap. The main components are (1) an augmented visual-inertial odometry (VIO) estimator with contact-consistency factors that activate only during interaction, tightening uncertainty around the contact frame and reducing drift, and (2) image-based visual servoing (IBVS) to mitigate perception-control coupling, together with a hybrid force-motion controller that regulates contact wrenches and lateral motion for stable contact. Experiments show that our approach closes the perception-to-wrench loop using only onboard sensing, yielding an velocity estimation improvement of 66.01% at contact, reliable target approach, and stable force holding-pointing toward deployable, in-the-wild aerial manipulation.
AEOS: Active Environment-aware Optimal Scanning Control for UAV LiDAR-Inertial Odometry in Complex Scenes
Sep 11, 2025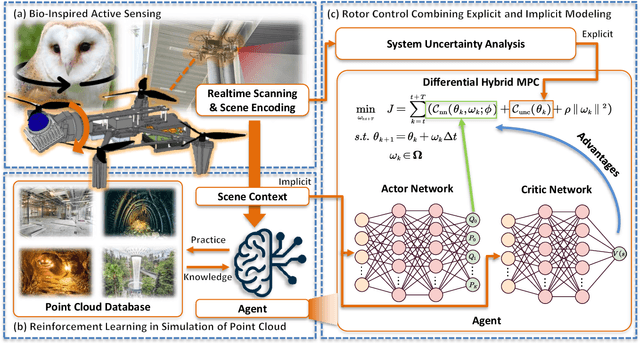

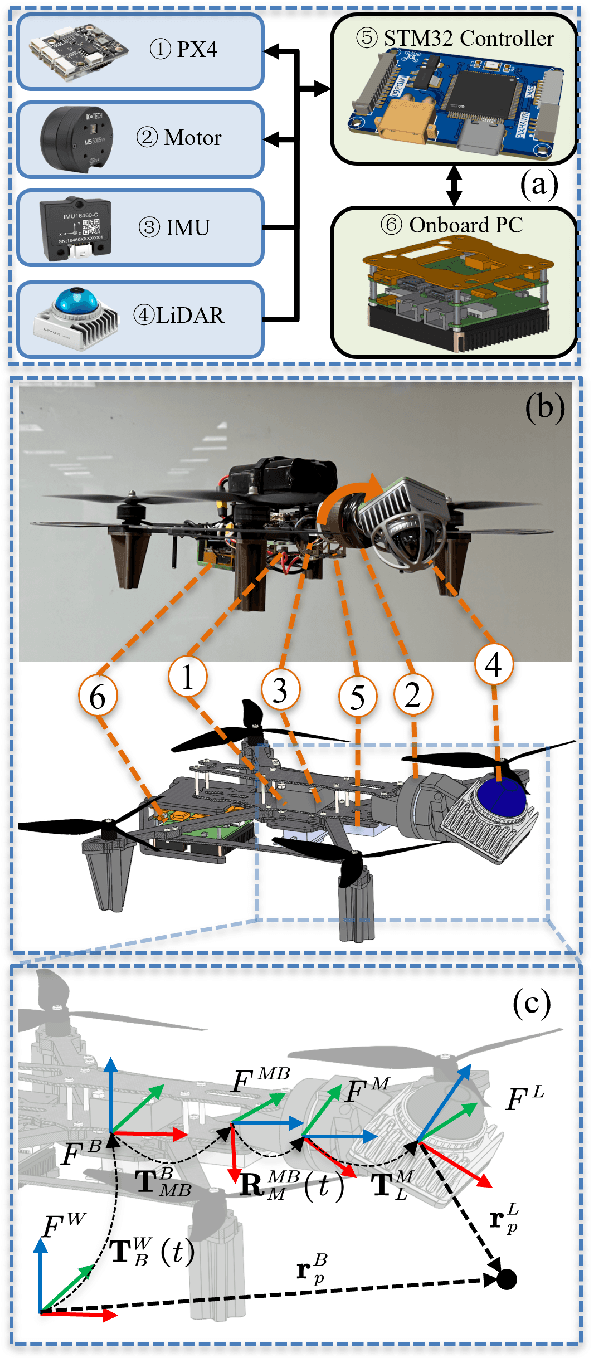
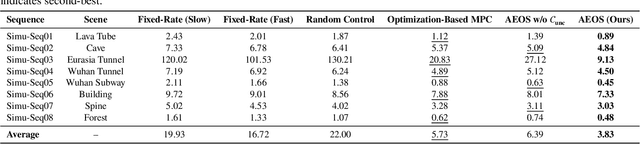
LiDAR-based 3D perception and localization on unmanned aerial vehicles (UAVs) are fundamentally limited by the narrow field of view (FoV) of compact LiDAR sensors and the payload constraints that preclude multi-sensor configurations. Traditional motorized scanning systems with fixed-speed rotations lack scene awareness and task-level adaptability, leading to degraded odometry and mapping performance in complex, occluded environments. Inspired by the active sensing behavior of owls, we propose AEOS (Active Environment-aware Optimal Scanning), a biologically inspired and computationally efficient framework for adaptive LiDAR control in UAV-based LiDAR-Inertial Odometry (LIO). AEOS combines model predictive control (MPC) and reinforcement learning (RL) in a hybrid architecture: an analytical uncertainty model predicts future pose observability for exploitation, while a lightweight neural network learns an implicit cost map from panoramic depth representations to guide exploration. To support scalable training and generalization, we develop a point cloud-based simulation environment with real-world LiDAR maps across diverse scenes, enabling sim-to-real transfer. Extensive experiments in both simulation and real-world environments demonstrate that AEOS significantly improves odometry accuracy compared to fixed-rate, optimization-only, and fully learned baselines, while maintaining real-time performance under onboard computational constraints. The project page can be found at https://kafeiyin00.github.io/AEOS/.
Following Is All You Need: Robot Crowd Navigation Using People As Planners
Apr 15, 2025Navigating in crowded environments requires the robot to be equipped with high-level reasoning and planning techniques. Existing works focus on developing complex and heavyweight planners while ignoring the role of human intelligence. Since humans are highly capable agents who are also widely available in a crowd navigation setting, we propose an alternative scheme where the robot utilises people as planners to benefit from their effective planning decisions and social behaviours. Through a set of rule-based evaluations, we identify suitable human leaders who exhibit the potential to guide the robot towards its goal. Using a simple base planner, the robot follows the selected leader through shorthorizon subgoals that are designed to be straightforward to achieve. We demonstrate through both simulated and real-world experiments that our novel framework generates safe and efficient robot plans compared to existing planners, even without predictive or data-driven modules. Our method also brings human-like robot behaviours without explicitly defining traffic rules and social norms. Code will be available at https://github.com/centiLinda/PeopleAsPlanner.git.
PIPE Planner: Pathwise Information Gain with Map Predictions for Indoor Robot Exploration
Mar 10, 2025



Autonomous exploration in unknown environments requires estimating the information gain of an action to guide planning decisions. While prior approaches often compute information gain at discrete waypoints, pathwise integration offers a more comprehensive estimation but is often computationally challenging or infeasible and prone to overestimation. In this work, we propose the Pathwise Information Gain with Map Prediction for Exploration (PIPE) planner, which integrates cumulative sensor coverage along planned trajectories while leveraging map prediction to mitigate overestimation. To enable efficient pathwise coverage computation, we introduce a method to efficiently calculate the expected observation mask along the planned path, significantly reducing computational overhead. We validate PIPE on real-world floorplan datasets, demonstrating its superior performance over state-of-the-art baselines. Our results highlight the benefits of integrating predictive mapping with pathwise information gain for efficient and informed exploration.
AToM: Adaptive Theory-of-Mind-Based Human Motion Prediction in Long-Term Human-Robot Interactions
Feb 09, 2025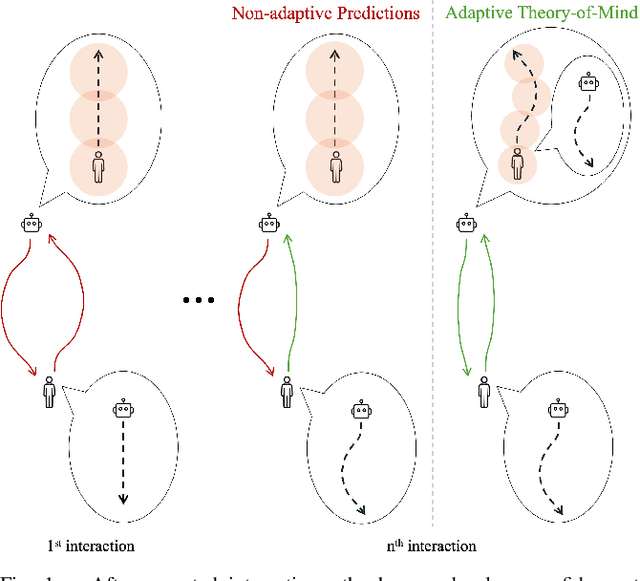
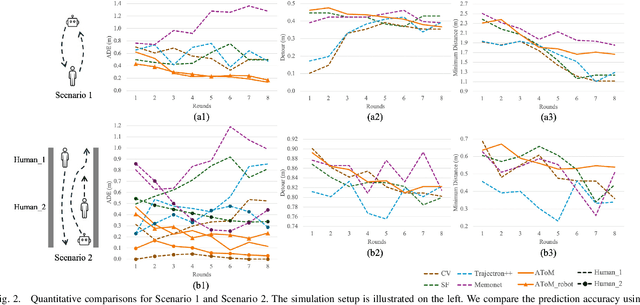
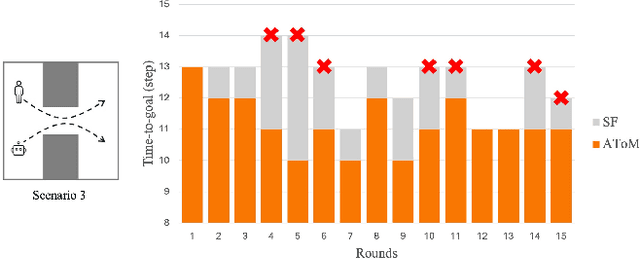
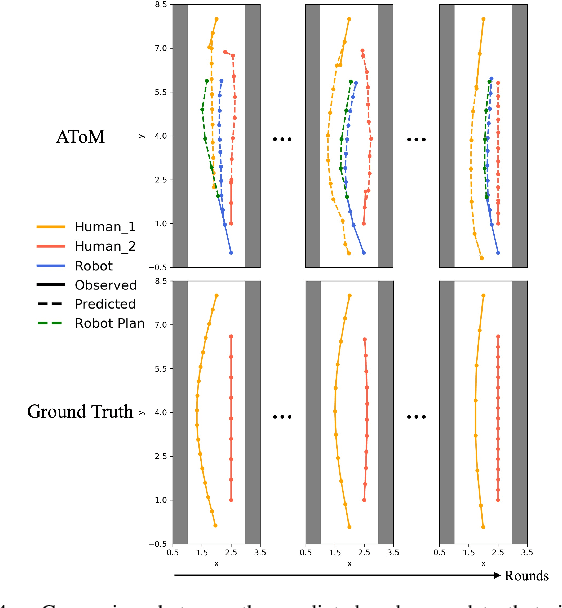
Humans learn from observations and experiences to adjust their behaviours towards better performance. Interacting with such dynamic humans is challenging, as the robot needs to predict the humans accurately for safe and efficient operations. Long-term interactions with dynamic humans have not been extensively studied by prior works. We propose an adaptive human prediction model based on the Theory-of-Mind (ToM), a fundamental social-cognitive ability that enables humans to infer others' behaviours and intentions. We formulate the human internal belief about others using a game-theoretic model, which predicts the future motions of all agents in a navigation scenario. To estimate an evolving belief, we use an Unscented Kalman Filter to update the behavioural parameters in the human internal model. Our formulation provides unique interpretability to dynamic human behaviours by inferring how the human predicts the robot. We demonstrate through long-term experiments in both simulations and real-world settings that our prediction effectively promotes safety and efficiency in downstream robot planning. Code will be available at https://github.com/centiLinda/AToM-human-prediction.git.
Cooperative Aerial Robot Inspection Challenge: A Benchmark for Heterogeneous Multi-UAV Planning and Lessons Learned
Jan 14, 2025



We propose the Cooperative Aerial Robot Inspection Challenge (CARIC), a simulation-based benchmark for motion planning algorithms in heterogeneous multi-UAV systems. CARIC features UAV teams with complementary sensors, realistic constraints, and evaluation metrics prioritizing inspection quality and efficiency. It offers a ready-to-use perception-control software stack and diverse scenarios to support the development and evaluation of task allocation and motion planning algorithms. Competitions using CARIC were held at IEEE CDC 2023 and the IROS 2024 Workshop on Multi-Robot Perception and Navigation, attracting innovative solutions from research teams worldwide. This paper examines the top three teams from CDC 2023, analyzing their exploration, inspection, and task allocation strategies while drawing insights into their performance across scenarios. The results highlight the task's complexity and suggest promising directions for future research in cooperative multi-UAV systems.
Large-Scale UWB Anchor Calibration and One-Shot Localization Using Gaussian Process
Dec 22, 2024



Ultra-wideband (UWB) is gaining popularity with devices like AirTags for precise home item localization but faces significant challenges when scaled to large environments like seaports. The main challenges are calibration and localization in obstructed conditions, which are common in logistics environments. Traditional calibration methods, dependent on line-of-sight (LoS), are slow, costly, and unreliable in seaports and warehouses, making large-scale localization a significant pain point in the industry. To overcome these challenges, we propose a UWB-LiDAR fusion-based calibration and one-shot localization framework. Our method uses Gaussian Processes to estimate anchor position from continuous-time LiDAR Inertial Odometry with sampled UWB ranges. This approach ensures accurate and reliable calibration with just one round of sampling in large-scale areas, I.e., 600x450 square meter. With the LoS issues, UWB-only localization can be problematic, even when anchor positions are known. We demonstrate that by applying a UWB-range filter, the search range for LiDAR loop closure descriptors is significantly reduced, improving both accuracy and speed. This concept can be applied to other loop closure detection methods, enabling cost-effective localization in large-scale warehouses and seaports. It significantly improves precision in challenging environments where UWB-only and LiDAR-Inertial methods fall short, as shown in the video \url{https://youtu.be/oY8jQKdM7lU }. We will open-source our datasets and calibration codes for community use.
Learning Dynamic Weight Adjustment for Spatial-Temporal Trajectory Planning in Crowd Navigation
Nov 30, 2024



Robot navigation in dense human crowds poses a significant challenge due to the complexity of human behavior in dynamic and obstacle-rich environments. In this work, we propose a dynamic weight adjustment scheme using a neural network to predict the optimal weights of objectives in an optimization-based motion planner. We adopt a spatial-temporal trajectory planner and incorporate diverse objectives to achieve a balance among safety, efficiency, and goal achievement in complex and dynamic environments. We design the network structure, observation encoding, and reward function to effectively train the policy network using reinforcement learning, allowing the robot to adapt its behavior in real time based on environmental and pedestrian information. Simulation results show improved safety compared to the fixed-weight planner and the state-of-the-art learning-based methods, and verify the ability of the learned policy to adaptively adjust the weights based on the observed situations. The approach's feasibility is demonstrated in a navigation task using an autonomous delivery robot across a crowded corridor over a 300 m distance.
AV-PedAware: Self-Supervised Audio-Visual Fusion for Dynamic Pedestrian Awareness
Nov 11, 2024



In this study, we introduce AV-PedAware, a self-supervised audio-visual fusion system designed to improve dynamic pedestrian awareness for robotics applications. Pedestrian awareness is a critical requirement in many robotics applications. However, traditional approaches that rely on cameras and LIDARs to cover multiple views can be expensive and susceptible to issues such as changes in illumination, occlusion, and weather conditions. Our proposed solution replicates human perception for 3D pedestrian detection using low-cost audio and visual fusion. This study represents the first attempt to employ audio-visual fusion to monitor footstep sounds for the purpose of predicting the movements of pedestrians in the vicinity. The system is trained through self-supervised learning based on LIDAR-generated labels, making it a cost-effective alternative to LIDAR-based pedestrian awareness. AV-PedAware achieves comparable results to LIDAR-based systems at a fraction of the cost. By utilizing an attention mechanism, it can handle dynamic lighting and occlusions, overcoming the limitations of traditional LIDAR and camera-based systems. To evaluate our approach's effectiveness, we collected a new multimodal pedestrian detection dataset and conducted experiments that demonstrate the system's ability to provide reliable 3D detection results using only audio and visual data, even in extreme visual conditions. We will make our collected dataset and source code available online for the community to encourage further development in the field of robotics perception systems.