 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and generalization of robotic dual-arm manipulation of boxes from demonstrations via Gaussian Mixture Models (GMMs)
Mar 07, 2025Learning from demonstration (LfD) is an effective method to teach robots to move and manipulate objects in a human-like manner. This is especially true when dealing with complex robotic systems, such as those with dual arms employed for their improved payload capacity and manipulability. However, a key challenge is in expanding the robotic movements beyond the learned scenarios to adapt to minor and major variations from the specific demonstrations. In this work, we propose a learning and novel generalization approach that adapts the learned Gaussian Mixture Model (GMM)-parameterized policy derived from human demonstrations. Our method requires only a small number of human demonstrations and eliminates the need for a robotic system during the demonstration phase, which can significantly reduce both cost and time. The generalization process takes place directly in the parameter space, leveraging the lower-dimensional representation of GMM parameters. With only three parameters per Gaussian component, this process is computationally efficient and yields immediate results upon request. We validate our approach through real-world experiments involving a dual-arm robotic manipulation of boxes. Starting with just five demonstrations for a single task, our approach successfully generalizes to new unseen scenarios, including new target locations, orientations, and box sizes. These results highlight the practical applicability and scalability of our method for complex manipulations.
Learning Dynamic Weight Adjustment for Spatial-Temporal Trajectory Planning in Crowd Navigation
Nov 30, 2024



Robot navigation in dense human crowds poses a significant challenge due to the complexity of human behavior in dynamic and obstacle-rich environments. In this work, we propose a dynamic weight adjustment scheme using a neural network to predict the optimal weights of objectives in an optimization-based motion planner. We adopt a spatial-temporal trajectory planner and incorporate diverse objectives to achieve a balance among safety, efficiency, and goal achievement in complex and dynamic environments. We design the network structure, observation encoding, and reward function to effectively train the policy network using reinforcement learning, allowing the robot to adapt its behavior in real time based on environmental and pedestrian information. Simulation results show improved safety compared to the fixed-weight planner and the state-of-the-art learning-based methods, and verify the ability of the learned policy to adaptively adjust the weights based on the observed situations. The approach's feasibility is demonstrated in a navigation task using an autonomous delivery robot across a crowded corridor over a 300 m distance.
Graph Optimality-Aware Stochastic LiDAR Bundle Adjustment with Progressive Spatial Smoothing
Oct 18, 2024



Large-scale LiDAR Bundle Adjustment (LBA) for refining sensor orientation and point cloud accuracy simultaneously is a fundamental task in photogrammetry and robotics, particularly as low-cost 3D sensors are increasingly used for 3D mapping in complex scenes. Unlike pose-graph-based methods that rely solely on pairwise relationships between LiDAR frames, LBA leverages raw LiDAR correspondences to achieve more precise results, especially when initial pose estimates are unreliable for low-cost sensors. However, existing LBA methods face challenges such as simplistic planar correspondences, extensive observations, and dense normal matrices in the least-squares problem, which limit robustness, efficiency, and scalability. To address these issues, we propose a Graph Optimality-aware Stochastic Optimization scheme with Progressive Spatial Smoothing, namely PSS-GOSO, to achieve \textit{robust}, \textit{efficient}, and \textit{scalable} LBA. The Progressive Spatial Smoothing (PSS) module extracts \textit{robust} LiDAR feature association exploiting the prior structure information obtained by the polynomial smooth kernel. The Graph Optimality-aware Stochastic Optimization (GOSO) module first sparsifies the graph according to optimality for an \textit{efficient} optimization. GOSO then utilizes stochastic clustering and graph marginalization to solve the large-scale state estimation problem for a \textit{scalable} LBA. We validate PSS-GOSO across diverse scenes captured by various platforms, demonstrating its superior performance compared to existing methods.
Few-shot Segmentation with Optimal Transport Matching and Message Flow
Aug 19, 2021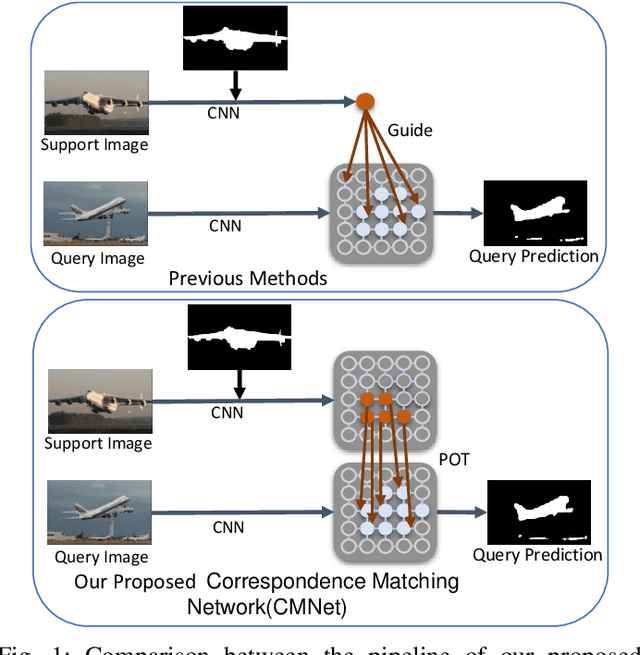
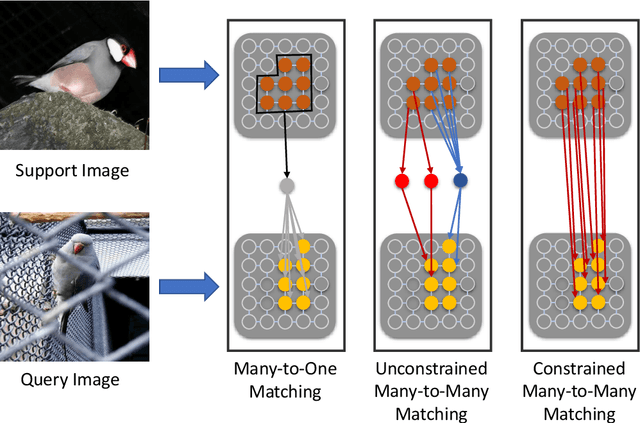
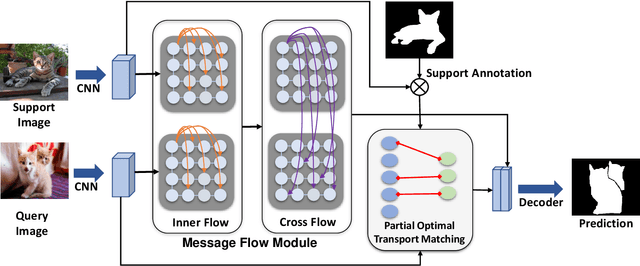

We address the challenging task of few-shot segmentation in this work. It is essential for few-shot semantic segmentation to fully utilize the support information. Previous methods typically adapt masked average pooling over the support feature to extract the support clues as a global vector, usually dominated by the salient part and loses some important clues. In this work, we argue that every support pixel's information is desired to be transferred to all query pixels and propose a Correspondence Matching Network (CMNet) with an Optimal Transport Matching module to mine out the correspondence between the query and support images. Besides, it is important to fully utilize both local and global information from the annotated support images. To this end, we propose a Message Flow module to propagate the message along the inner-flow within the same image and cross-flow between support and query images, which greatly help enhance the local feature representations. We further address the few-shot segmentation as a multi-task learning problem to alleviate the domain gap issue between different datasets. Experiments on PASCAL VOC 2012, MS COCO, and FSS-1000 datasets show that our network achieves new state-of-the-art few-shot segmentation performance.
Cross-Image Region Mining with Region Prototypical Network for Weakly Supervised Segmentation
Aug 17, 2021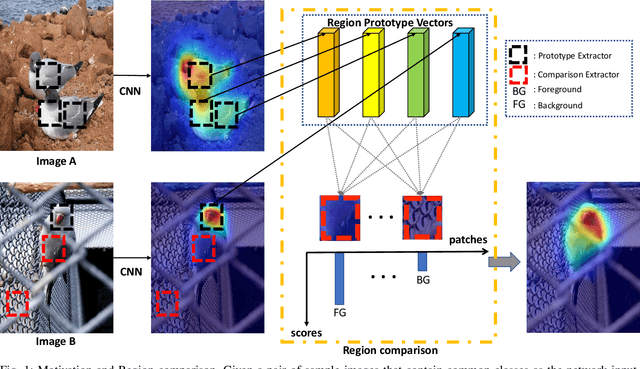
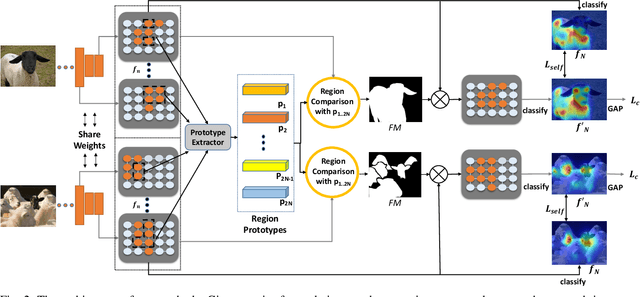
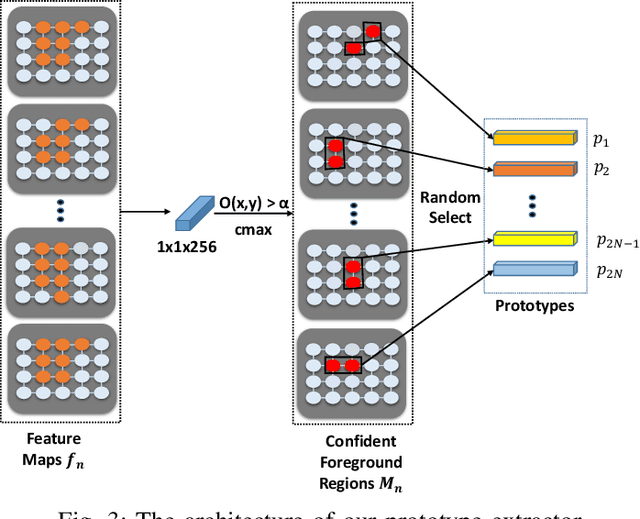
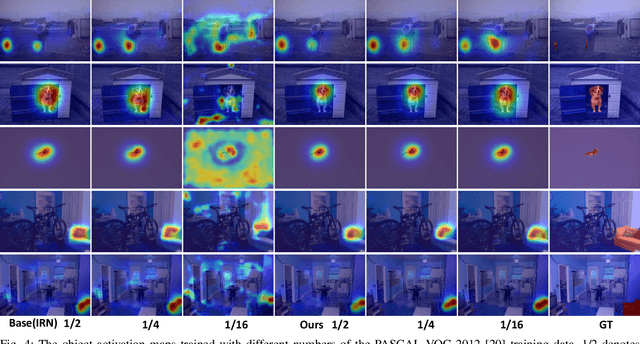
Weakly supervised image segmentation trained with image-level labels usually suffers from inaccurate coverage of object areas during the generation of the pseudo groundtruth. This is because the object activation maps are trained with the classification objective and lack the ability to generalize. To improve the generality of the objective activation maps, we propose a region prototypical network RPNet to explore the cross-image object diversity of the training set. Similar object parts across images are identified via region feature comparison. Object confidence is propagated between regions to discover new object areas while background regions are suppressed. Experiments show that the proposed method generates more complete and accurate pseudo object masks, while achieving state-of-the-art performance on PASCAL VOC 2012 and MS COCO. In addition, we investigate the robustness of the proposed method on reduced training sets.
Dense Supervision Propagation for Weakly Supervised Semantic Segmentation on 3D Point Clouds
Jul 23, 2021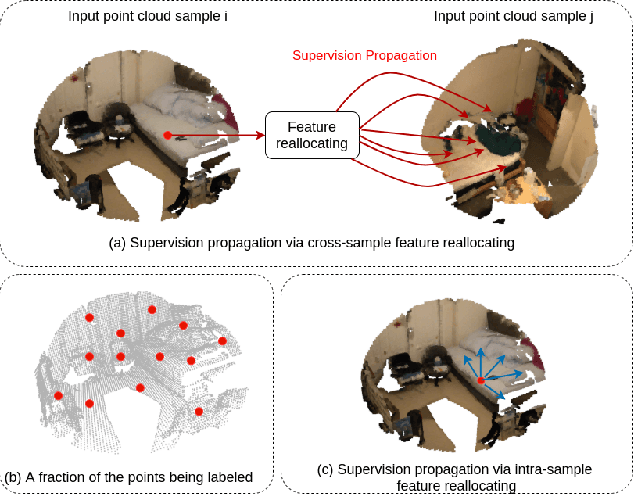
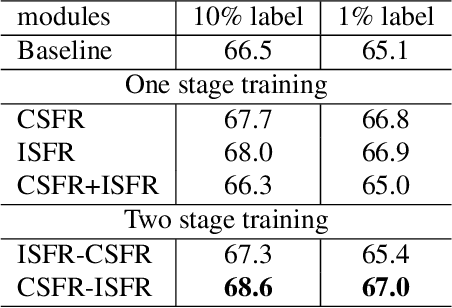
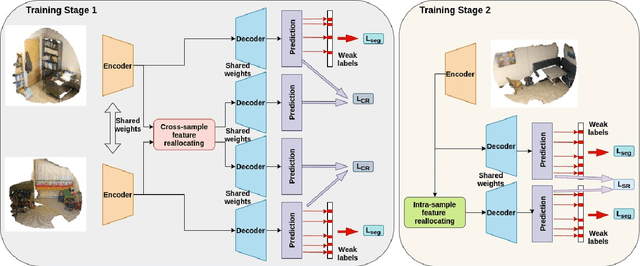
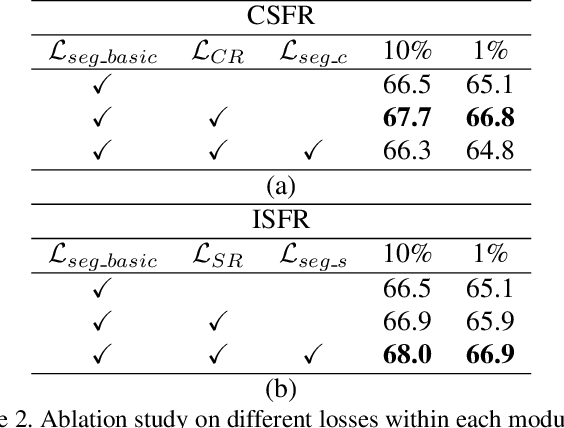
Semantic segmentation on 3D point clouds is an important task for 3D scene understanding. While dense labeling on 3D data is expensive and time-consuming, only a few works address weakly supervised semantic point cloud segmentation methods to relieve the labeling cost by learning from simpler and cheaper labels. Meanwhile, there are still huge performance gaps between existing weakly supervised methods and state-of-the-art fully supervised methods. In this paper, we train a semantic point cloud segmentation network with only a small portion of points being labeled. We argue that we can better utilize the limited supervision information as we densely propagate the supervision signal from the labeled points to other points within and across the input samples. Specifically, we propose a cross-sample feature reallocating module to transfer similar features and therefore re-route the gradients across two samples with common classes and an intra-sample feature redistribution module to propagate supervision signals on unlabeled points across and within point cloud samples. We conduct extensive experiments on public datasets S3DIS and ScanNet. Our weakly supervised method with only 10\% and 1\% of labels can produce compatible results with the fully supervised counterpart.
Defect-GAN: High-Fidelity Defect Synthesis for Automated Defect Inspection
Mar 28, 2021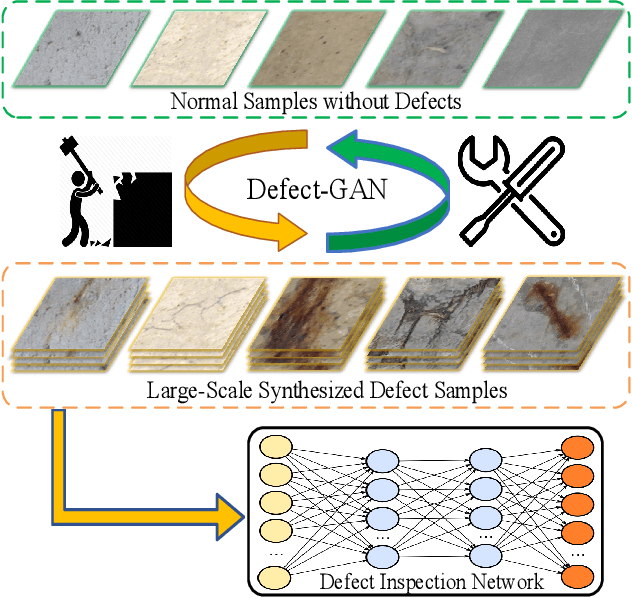
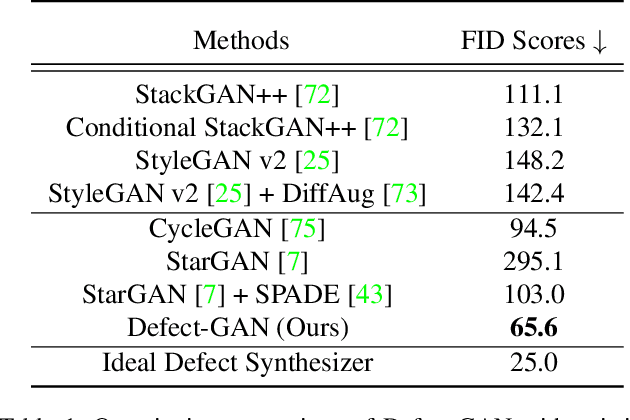
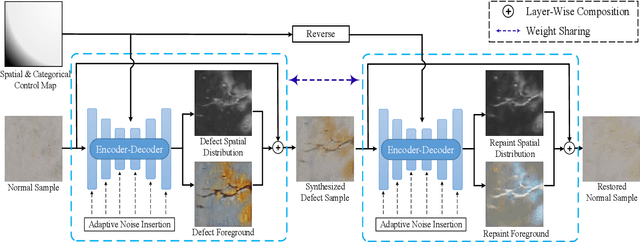
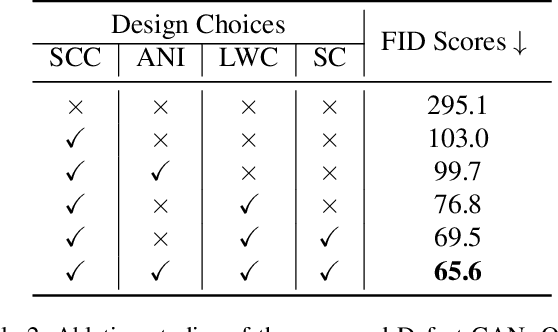
Automated defect inspection is critical for effective and efficient maintenance, repair, and operations in advanced manufacturing. On the other hand, automated defect inspection is often constrained by the lack of defect samples, especially when we adopt deep neural networks for this task. This paper presents Defect-GAN, an automated defect synthesis network that generates realistic and diverse defect samples for training accurate and robust defect inspection networks. Defect-GAN learns through defacement and restoration processes, where the defacement generates defects on normal surface images while the restoration removes defects to generate normal images. It employs a novel compositional layer-based architecture for generating realistic defects within various image backgrounds with different textures and appearances. It can also mimic the stochastic variations of defects and offer flexible control over the locations and categories of the generated defects within the image background. Extensive experiments show that Defect-GAN is capable of synthesizing various defects with superior diversity and fidelity. In addition, the synthesized defect samples demonstrate their effectiveness in training better defect inspection networks.
Multi-Path Region Mining For Weakly Supervised 3D Semantic Segmentation on Point Clouds
Mar 29, 2020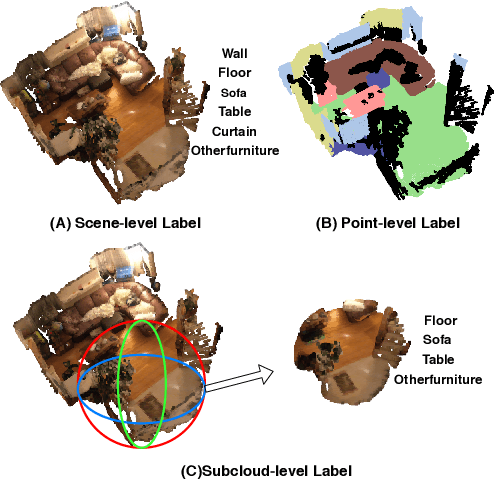
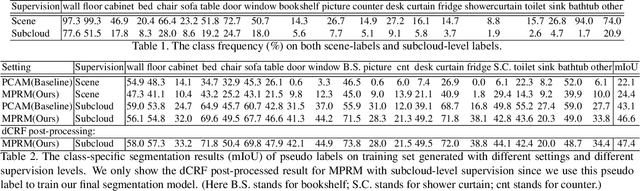
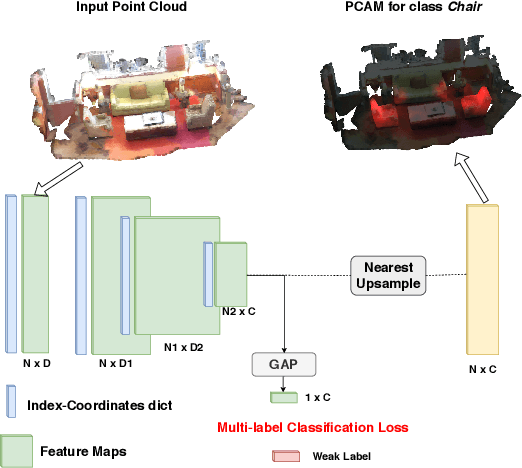
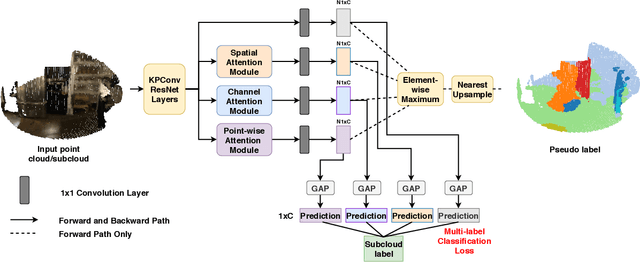
Point clouds provide intrinsic geometric information and surface context for scene understanding. Existing methods for point cloud segmentation require a large amount of fully labeled data. Using advanced depth sensors, collection of large scale 3D dataset is no longer a cumbersome process. However, manually producing point-level label on the large scale dataset is time and labor-intensive. In this paper, we propose a weakly supervised approach to predict point-level results using weak labels on 3D point clouds. We introduce our multi-path region mining module to generate pseudo point-level label from a classification network trained with weak labels. It mines the localization cues for each class from various aspects of the network feature using different attention modules. Then, we use the point-level pseudo labels to train a point cloud segmentation network in a fully supervised manner. To the best of our knowledge, this is the first method that uses cloud-level weak labels on raw 3D space to train a point cloud semantic segmentation network. In our setting, the 3D weak labels only indicate the classes that appeared in our input sample. We discuss both scene- and subcloud-level weakly labels on raw 3D point cloud data and perform in-depth experiments on them. On ScanNet dataset, our result trained with subcloud-level labels is compatible with some fully supervised methods.