 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Image Region Mining with Region Prototypical Network for Weakly Supervised Segmentation
Aug 17, 2021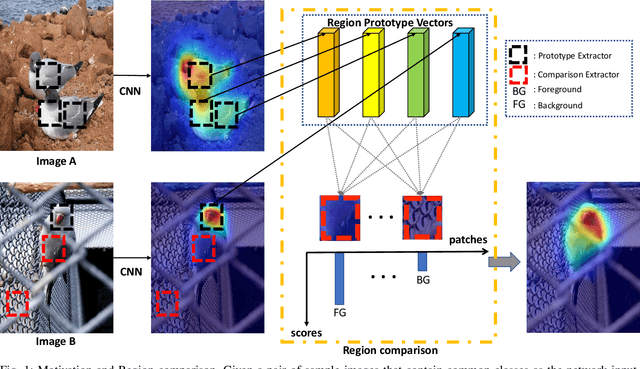
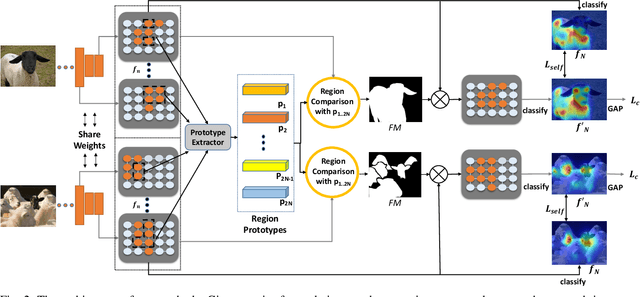
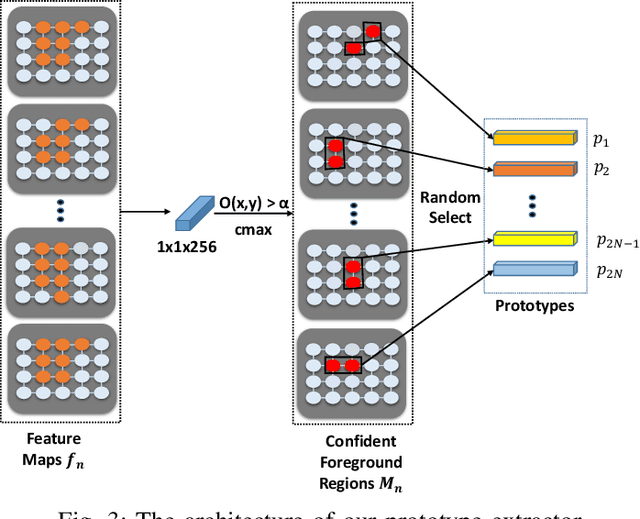
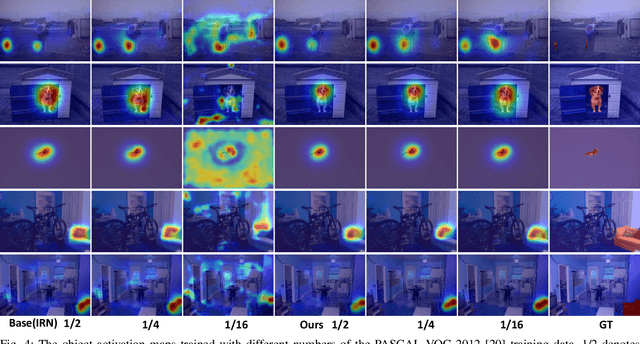
Weakly supervised image segmentation trained with image-level labels usually suffers from inaccurate coverage of object areas during the generation of the pseudo groundtruth. This is because the object activation maps are trained with the classification objective and lack the ability to generalize. To improve the generality of the objective activation maps, we propose a region prototypical network RPNet to explore the cross-image object diversity of the training set. Similar object parts across images are identified via region feature comparison. Object confidence is propagated between regions to discover new object areas while background regions are suppressed. Experiments show that the proposed method generates more complete and accurate pseudo object masks, while achieving state-of-the-art performance on PASCAL VOC 2012 and MS COCO. In addition, we investigate the robustness of the proposed method on reduced training sets.
Dual Attention Matching Network for Context-Aware Feature Sequence based Person Re-Identification
Mar 27, 2018
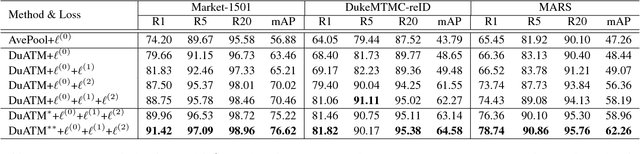
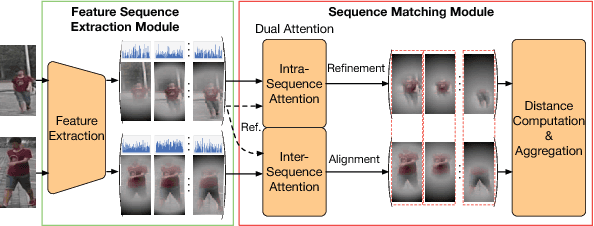
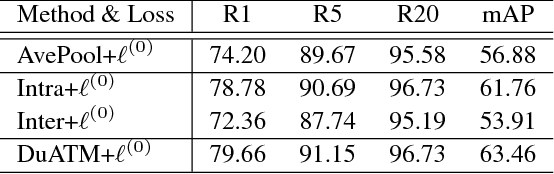
Typical person re-identification (ReID) methods usually describe each pedestrian with a single feature vector and match them in a task-specific metric space. However, the methods based on a single feature vector are not sufficient enough to overcome visual ambiguity, which frequently occurs in real scenario. In this paper, we propose a novel end-to-end trainable framework, called Dual ATtention Matching network (DuATM), to learn context-aware feature sequences and perform attentive sequence comparison simultaneously. The core component of our DuATM framework is a dual attention mechanism, in which both intra-sequence and inter-sequence attention strategies are used for feature refinement and feature-pair alignment, respectively. Thus, detailed visual cues contained in the intermediate feature sequences can be automatically exploited and properly compared. We train the proposed DuATM network as a siamese network via a triplet loss assisted with a de-correlation loss and a cross-entropy loss. We conduct extensive experiments on both image and video based ReID benchmark datasets. Experimental results demonstrate the significant advantages of our approach compared to the state-of-the-art methods.
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
Jan 29, 2018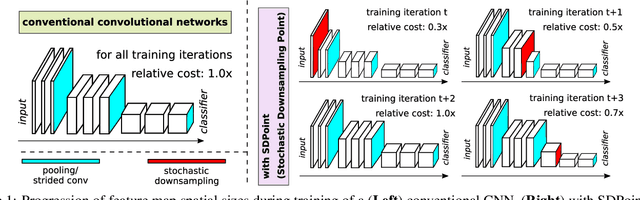



It is desirable to train convolutional networks (CNNs) to run more efficiently during inference. In many cases however, the computational budget that the system has for inference cannot be known beforehand during training, or the inference budget is dependent on the changing real-time resource availability. Thus, it is inadequate to train just inference-efficient CNNs, whose inference costs are not adjustable and cannot adapt to varied inference budgets. We propose a novel approach for cost-adjustable inference in CNNs - Stochastic Downsampling Point (SDPoint). During training, SDPoint applies feature map downsampling to a random point in the layer hierarchy, with a random downsampling ratio. The different stochastic downsampling configurations known as SDPoint instances (of the same model) have computational costs different from each other, while being trained to minimize the same prediction loss. Sharing network parameters across different instances provides significant regularization boost. During inference, one may handpick a SDPoint instance that best fits the inference budget. The effectiveness of SDPoint, as both a cost-adjustable inference approach and a regularizer, is validated through extensive experiments on image classification.
DelugeNets: Deep Networks with Efficient and Flexible Cross-layer Information Inflows
Aug 23, 2017

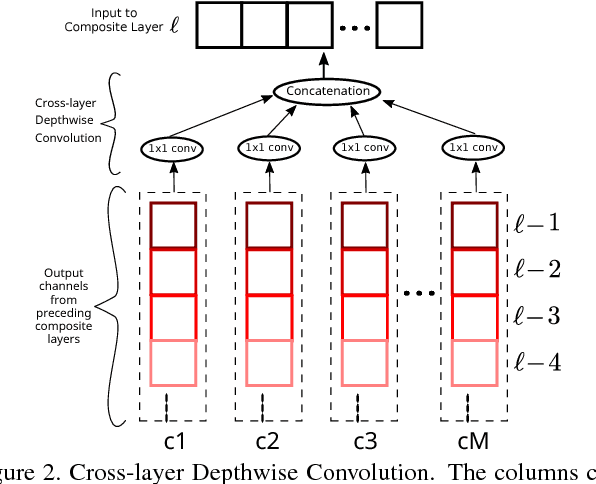

Deluge Networks (DelugeNets) are deep neural networks which efficiently facilitate massive cross-layer information inflows from preceding layers to succeeding layers. The connections between layers in DelugeNets are established through cross-layer depthwise convolutional layers with learnable filters, acting as a flexible yet efficient selection mechanism. DelugeNets can propagate information across many layers with greater flexibility and utilize network parameters more effectively compared to ResNets, whilst being more efficient than DenseNets. Remarkably, a DelugeNet model with just model complexity of 4.31 GigaFLOPs and 20.2M network parameters, achieve classification errors of 3.76% and 19.02% on CIFAR-10 and CIFAR-100 dataset respectively. Moreover, DelugeNet-122 performs competitively to ResNet-200 on ImageNet dataset, despite costing merely half of the computations needed by the latter.
Microscopic Muscle Image Enhancement
Dec 17, 2016

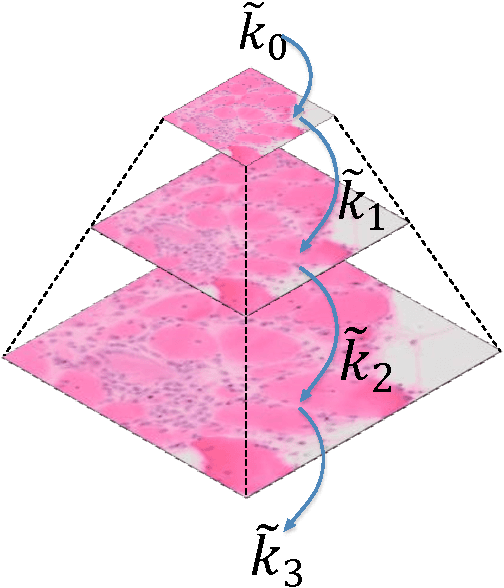

We propose a robust image enhancement algorithm dedicated for muscle fiber specimen images captured by optical microscopes. Blur or out of focus problems are prevalent in muscle images during the image acquisition stage. Traditional image deconvolution methods do not work since they assume the blur kernels are known and also produce ring artifacts. We provide a compact framework which involves a novel spatially non-uniform blind deblurring approach specialized to muscle images which automatically detects and alleviates degraded regions. Ring artifacts problems are addressed and a kernel propagation strategy is proposed to speedup the algorithm and deals with the high non-uniformity of the blur kernels on muscle images. Experiments show that the proposed framework performs well on muscle images taken with modern advanced optical microscopes. Our framework is free of laborious parameter settings and is computationally efficient.