 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealDPO: Real or Not Real, that is the Preference
Oct 16, 2025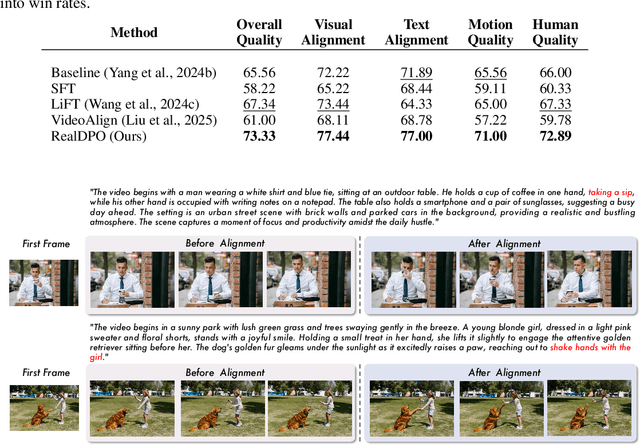

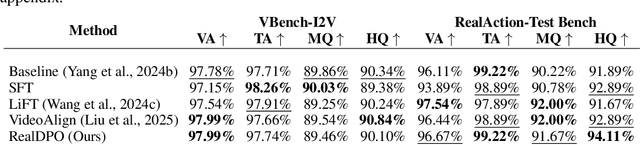
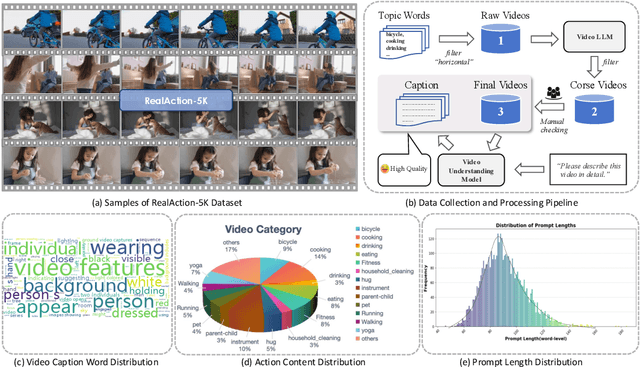
Video generative models have recently achieved notable advancements in synthesis quality. However, generating complex motions remains a critical challenge, as existing models often struggle to produce natural, smooth, and contextually consistent movements. This gap between generated and real-world motions limits their practical applicability. To address this issue, we introduce RealDPO, a novel alignment paradigm that leverages real-world data as positive samples for preference learning, enabling more accurate motion synthesis. Unlike traditional supervised fine-tuning (SFT), which offers limited corrective feedback, RealDPO employs Direct Preference Optimization (DPO) with a tailored loss function to enhance motion realism. By contrasting real-world videos with erroneous model outputs, RealDPO enables iterative self-correction, progressively refining motion quality. To support post-training in complex motion synthesis, we propose RealAction-5K, a curated dataset of high-quality videos capturing human daily activities with rich and precise motion details. Extensive experiments demonstrate that RealDPO significantly improves video quality, text alignment, and motion realism compared to state-of-the-art models and existing preference optimization techniques.
Style4D-Bench: A Benchmark Suite for 4D Stylization
Aug 26, 2025We introduce Style4D-Bench, the first benchmark suite specifically designed for 4D stylization, with the goal of standardizing evaluation and facilitating progress in this emerging area. Style4D-Bench comprises: 1) a comprehensive evaluation protocol measuring spatial fidelity, temporal coherence, and multi-view consistency through both perceptual and quantitative metrics, 2) a strong baseline that make an initial attempt for 4D stylization, and 3) a curated collection of high-resolution dynamic 4D scenes with diverse motions and complex backgrounds. To establish a strong baseline, we present Style4D, a novel framework built upon 4D Gaussian Splatting. It consists of three key components: a basic 4DGS scene representation to capture reliable geometry, a Style Gaussian Representation that leverages lightweight per-Gaussian MLPs for temporally and spatially aware appearance control, and a Holistic Geometry-Preserved Style Transfer module designed to enhance spatio-temporal consistency via contrastive coherence learning and structural content preservation. Extensive experiments on Style4D-Bench demonstrate that Style4D achieves state-of-the-art performance in 4D stylization, producing fine-grained stylistic details with stable temporal dynamics and consistent multi-view rendering. We expect Style4D-Bench to become a valuable resource for benchmarking and advancing research in stylized rendering of dynamic 3D scenes. Project page: https://becky-catherine.github.io/Style4D . Code: https://github.com/Becky-catherine/Style4D-Bench .
Trajectory Attention for Fine-grained Video Motion Control
Nov 28, 2024
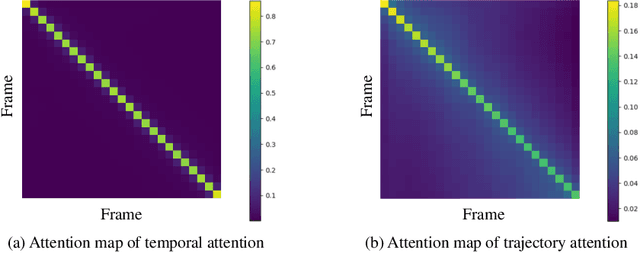

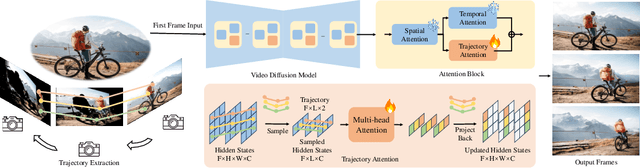
Recent advancements in video generation have been greatly driven by video diffusion models, with camera motion control emerging as a crucial challenge in creating view-customized visual content. This paper introduces trajectory attention, a novel approach that performs attention along available pixel trajectories for fine-grained camera motion control. Unlike existing methods that often yield imprecise outputs or neglect temporal correlations, our approach possesses a stronger inductive bias that seamlessly injects trajectory information into the video generation process. Importantly, our approach models trajectory attention as an auxiliary branch alongside traditional temporal attention. This design enables the original temporal attention and the trajectory attention to work in synergy, ensuring both precise motion control and new content generation capability, which is critical when the trajectory is only partially available. Experiments on camera motion control for images and videos demonstrate significant improvements in precision and long-range consistency while maintaining high-quality generation. Furthermore, we show that our approach can be extended to other video motion control tasks, such as first-frame-guided video editing, where it excels in maintaining content consistency over large spatial and temporal ranges.
Self-Supervised Vision Transformer for Enhanced Virtual Clothes Try-On
Jun 15, 2024Virtual clothes try-on has emerged as a vital feature in online shopping, offering consumers a critical tool to visualize how clothing fits. In our research, we introduce an innovative approach for virtual clothes try-on, utilizing a self-supervised Vision Transformer (ViT) coupled with a diffusion model. Our method emphasizes detail enhancement by contrasting local clothing image embeddings, generated by ViT, with their global counterparts. Techniques such as conditional guidance and focus on key regions have been integrated into our approach. These combined strategies empower the diffusion model to reproduce clothing details with increased clarity and realism. The experimental results showcase substantial advancements in the realism and precision of details in virtual try-on experiences, significantly surpassing the capabilities of existing technologies.
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
May 26, 2024



The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
Virtual Accessory Try-On via Keypoint Hallucination
Oct 26, 2023The virtual try-on task refers to fitting the clothes from one image onto another portrait image. In this paper, we focus on virtual accessory try-on, which fits accessory (e.g., glasses, ties) onto a face or portrait image. Unlike clothing try-on, which relies on human silhouette as guidance, accessory try-on warps the accessory into an appropriate location and shape to generate a plausible composite image. In contrast to previous try-on methods that treat foreground (i.e., accessories) and background (i.e., human faces or bodies) equally, we propose a background-oriented network to utilize the prior knowledge of human bodies and accessories. Specifically, our approach learns the human body priors and hallucinates the target locations of specified foreground keypoints in the background. Then our approach will inject foreground information with accessory priors into the background UNet. Based on the hallucinated target locations, the warping parameters are calculated to warp the foreground. Moreover, this background-oriented network can also easily incorporate auxiliary human face/body semantic segmentation supervision to further boost performance. Experiments conducted on STRAT dataset validate the effectiveness of our proposed method.
Taming the Power of Diffusion Models for High-Quality Virtual Try-On with Appearance Flow
Aug 11, 2023Virtual try-on is a critical image synthesis task that aims to transfer clothes from one image to another while preserving the details of both humans and clothes. While many existing methods rely on Generative Adversarial Networks (GANs) to achieve this, flaws can still occur, particularly at high resolutions. Recently, the diffusion model has emerged as a promising alternative for generating high-quality images in various applications. However, simply using clothes as a condition for guiding the diffusion model to inpaint is insufficient to maintain the details of the clothes. To overcome this challenge, we propose an exemplar-based inpainting approach that leverages a warping module to guide the diffusion model's generation effectively. The warping module performs initial processing on the clothes, which helps to preserve the local details of the clothes. We then combine the warped clothes with clothes-agnostic person image and add noise as the input of diffusion model. Additionally, the warped clothes is used as local conditions for each denoising process to ensure that the resulting output retains as much detail as possible. Our approach, namely Diffusion-based Conditional Inpainting for Virtual Try-ON (DCI-VTON), effectively utilizes the power of the diffusion model, and the incorporation of the warping module helps to produce high-quality and realistic virtual try-on results. Experimental results on VITON-HD demonstrate the effectiveness and superiority of our method.
Weak-shot Semantic Segmentation via Dual Similarity Transfer
Oct 05, 2022
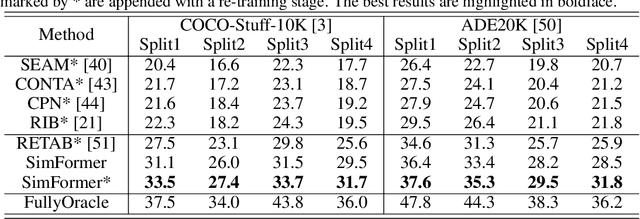
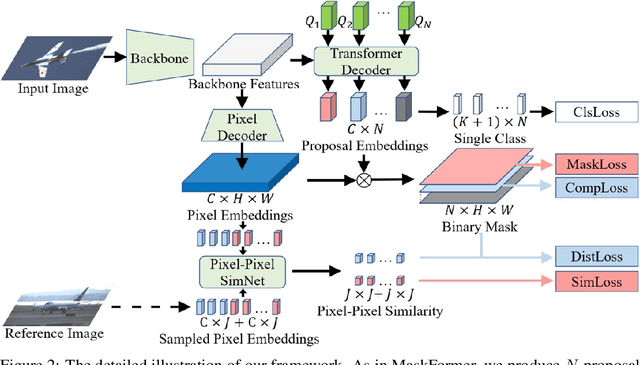
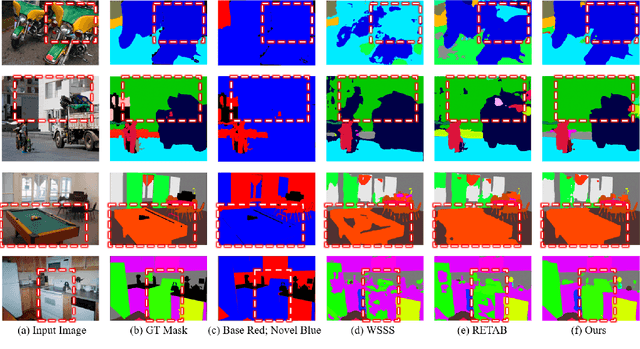
Semantic segmentation is an important and prevalent task, but severely suffers from the high cost of pixel-level annotations when extending to more classes in wider applications. To this end, we focus on the problem named weak-shot semantic segmentation, where the novel classes are learnt from cheaper image-level labels with the support of base classes having off-the-shelf pixel-level labels. To tackle this problem, we propose SimFormer, which performs dual similarity transfer upon MaskFormer. Specifically, MaskFormer disentangles the semantic segmentation task into two sub-tasks: proposal classification and proposal segmentation for each proposal. Proposal segmentation allows proposal-pixel similarity transfer from base classes to novel classes, which enables the mask learning of novel classes. We also learn pixel-pixel similarity from base classes and distill such class-agnostic semantic similarity to the semantic masks of novel classes, which regularizes the segmentation model with pixel-level semantic relationship across images. In addition, we propose a complementary loss to facilitate the learning of novel classes. Comprehensive experiments on the challenging COCO-Stuff-10K and ADE20K datasets demonstrate the effectiveness of our method. Codes are available at https://github.com/bcmi/SimFormer-Weak-Shot-Semantic-Segmentation.
Weak-shot Semantic Segmentation by Transferring Semantic Affinity and Boundary
Oct 04, 2021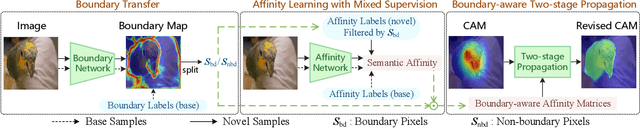
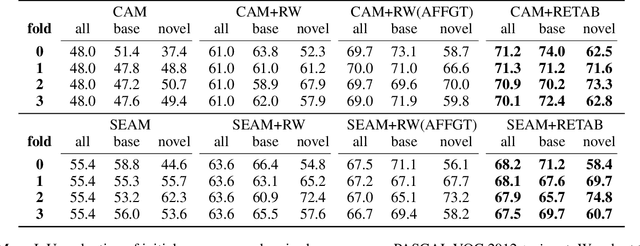


Weakly-supervised semantic segmentation (WSSS) with image-level labels has been widely studied to relieve the annotation burden of the traditional segmentation task. In this paper, we show that existing fully-annotated base categories can help segment objects of novel categories with only image-level labels, even if base and novel categories have no overlap. We refer to this task as weak-shot semantic segmentation, which could also be treated as WSSS with auxiliary fully-annotated categories. Recent advanced WSSS methods usually obtain class activation maps (CAMs) and refine them by affinity propagation. Based on the observation that semantic affinity and boundary are class-agnostic, we propose a method under the WSSS framework to transfer semantic affinity and boundary from base categories to novel ones. As a result, we find that pixel-level annotation of base categories can facilitate affinity learning and propagation, leading to higher-quality CAMs of novel categories. Extensive experiments on PASCAL VOC 2012 dataset demonstrate that our method significantly outperforms WSSS baselines on novel categories.
Dual Attention Matching Network for Context-Aware Feature Sequence based Person Re-Identification
Mar 27, 2018
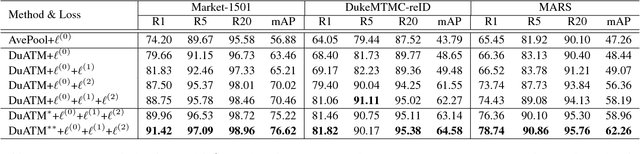
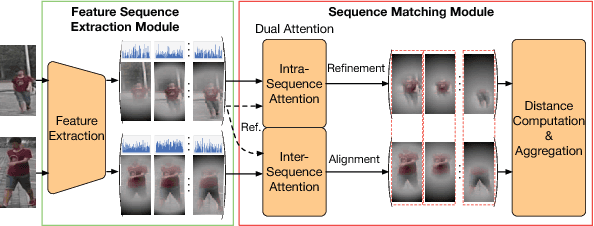
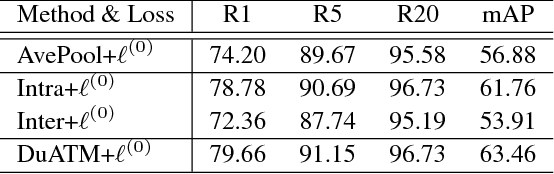
Typical person re-identification (ReID) methods usually describe each pedestrian with a single feature vector and match them in a task-specific metric space. However, the methods based on a single feature vector are not sufficient enough to overcome visual ambiguity, which frequently occurs in real scenario. In this paper, we propose a novel end-to-end trainable framework, called Dual ATtention Matching network (DuATM), to learn context-aware feature sequences and perform attentive sequence comparison simultaneously. The core component of our DuATM framework is a dual attention mechanism, in which both intra-sequence and inter-sequence attention strategies are used for feature refinement and feature-pair alignment, respectively. Thus, detailed visual cues contained in the intermediate feature sequences can be automatically exploited and properly compared. We train the proposed DuATM network as a siamese network via a triplet loss assisted with a de-correlation loss and a cross-entropy loss. We conduct extensive experiments on both image and video based ReID benchmark datasets. Experimental results demonstrate the significant advantages of our approach compared to the state-of-the-art methods.