 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Selection to Scheduling: Federated Geometry-Aware Correction Makes Exemplar Replay Work Better under Continual Dynamic Heterogeneity
Apr 09, 2026Exemplar replay has become an effective strategy for mitigating catastrophic forgetting in federated continual learning (FCL) by retaining representative samples from past tasks. Existing studies focus on designing sample-importance estimation mechanisms to identify information-rich samples. However, they typically overlook strategies for effectively utilizing the selected exemplars, which limits their performance under continual dynamic heterogeneity across clients and tasks. To address this issue, this paper proposes a Federated gEometry-Aware correcTion method, termed FEAT, which alleviates imbalance-induced representation collapse that drags rare-class features toward frequent classes across clients. Specifically, it consists of two key modules: 1) the Geometric Structure Alignment module performs structural knowledge distillation by aligning the pairwise angular similarities between feature representations and their corresponding Equiangular Tight Frame prototypes, which are fixed and shared across clients to serve as a class-discriminative reference structure. This encourages geometric consistency across tasks and helps mitigate representation drift; 2) the Energy-based Geometric Correction module removes task-irrelevant directional components from feature embeddings, which reduces prediction bias toward majority classes. This improves sensitivity to minority classes and enhances the model's robustness under class-imbalanced distributions.
Dynamic Deep Graph Learning for Incomplete Multi-View Clustering with Masked Graph Reconstruction Loss
Nov 14, 2025The prevalence of real-world multi-view data makes incomplete multi-view clustering (IMVC) a crucial research. The rapid development of Graph Neural Networks (GNNs) has established them as one of the mainstream approaches for multi-view clustering. Despite significant progress in GNNs-based IMVC, some challenges remain: (1) Most methods rely on the K-Nearest Neighbors (KNN) algorithm to construct static graphs from raw data, which introduces noise and diminishes the robustness of the graph topology. (2) Existing methods typically utilize the Mean Squared Error (MSE) loss between the reconstructed graph and the sparse adjacency graph directly as the graph reconstruction loss, leading to substantial gradient noise during optimization. To address these issues, we propose a novel \textbf{D}ynamic Deep \textbf{G}raph Learning for \textbf{I}ncomplete \textbf{M}ulti-\textbf{V}iew \textbf{C}lustering with \textbf{M}asked Graph Reconstruction Loss (DGIMVCM). Firstly, we construct a missing-robust global graph from the raw data. A graph convolutional embedding layer is then designed to extract primary features and refined dynamic view-specific graph structures, leveraging the global graph for imputation of missing views. This process is complemented by graph structure contrastive learning, which identifies consistency among view-specific graph structures. Secondly, a graph self-attention encoder is introduced to extract high-level representations based on the imputed primary features and view-specific graphs, and is optimized with a masked graph reconstruction loss to mitigate gradient noise during optimization. Finally, a clustering module is constructed and optimized through a pseudo-label self-supervised training mechanism. Extensive experiments on multiple datasets validate the effectiveness and superiority of DGIMVCM.
Semantic-Space-Intervened Diffusive Alignment for Visual Classification
May 09, 2025Cross-modal alignment is an effective approach to improving visual classification. Existing studies typically enforce a one-step mapping that uses deep neural networks to project the visual features to mimic the distribution of textual features. However, they typically face difficulties in finding such a projection due to the two modalities in both the distribution of class-wise samples and the range of their feature values. To address this issue, this paper proposes a novel Semantic-Space-Intervened Diffusive Alignment method, termed SeDA, models a semantic space as a bridge in the visual-to-textual projection, considering both types of features share the same class-level information in classification. More importantly, a bi-stage diffusion framework is developed to enable the progressive alignment between the two modalities. Specifically, SeDA first employs a Diffusion-Controlled Semantic Learner to model the semantic features space of visual features by constraining the interactive features of the diffusion model and the category centers of visual features. In the later stage of SeDA, the Diffusion-Controlled Semantic Translator focuses on learning the distribution of textual features from the semantic space. Meanwhile, the Progressive Feature Interaction Network introduces stepwise feature interactions at each alignment step, progressively integrating textual information into mapped features. Experimental results show that SeDA achieves stronger cross-modal feature alignment, leading to superior performance over existing methods across multiple scenarios.
ScaleGNN: Towards Scalable Graph Neural Networks via Adaptive High-order Neighboring Feature Fusion
Apr 22, 2025Graph Neural Networks (GNNs) have demonstrated strong performance across various graph-based tasks by effectively capturing relational information between nodes. These models rely on iterative message passing to propagate node features, enabling nodes to aggregate information from their neighbors. Recent research has significantly improved the message-passing mechanism, enhancing GNN scalability on large-scale graphs. However, GNNs still face two main challenges: over-smoothing, where excessive message passing results in indistinguishable node representations, especially in deep networks incorporating high-order neighbors; and scalability issues, as traditional architectures suffer from high model complexity and increased inference time due to redundant information aggregation. This paper proposes a novel framework for large-scale graphs named ScaleGNN that simultaneously addresses both challenges by adaptively fusing multi-level graph features. We first construct neighbor matrices for each order, learning their relative information through trainable weights through an adaptive high-order feature fusion module. This allows the model to selectively emphasize informative high-order neighbors while reducing unnecessary computational costs. Additionally, we introduce a High-order redundant feature masking mechanism based on a Local Contribution Score (LCS), which enables the model to retain only the most relevant neighbors at each order, preventing redundant information propagation. Furthermore, low-order enhanced feature aggregation adaptively integrates low-order and high-order features based on task relevance, ensuring effective capture of both local and global structural information without excessive complexity. Extensive experiments on real-world datasets demonstrate that our approach consistently outperforms state-of-the-art GNN models in both accuracy and computational efficiency.
Efficient Discovery of Motif Transition Process for Large-Scale Temporal Graphs
Apr 22, 2025Understanding the dynamic transition of motifs in temporal graphs is essential for revealing how graph structures evolve over time, identifying critical patterns, and predicting future behaviors, yet existing methods often focus on predefined motifs, limiting their ability to comprehensively capture transitions and interrelationships. We propose a parallel motif transition process discovery algorithm, PTMT, a novel parallel method for discovering motif transition processes in large-scale temporal graphs. PTMT integrates a tree-based framework with the temporal zone partitioning (TZP) strategy, which partitions temporal graphs by time and structure while preserving lossless motif transitions and enabling massive parallelism. PTMT comprises three phases: growth zone parallel expansion, overlap-aware result aggregation, and deterministic encoding of motif transitions, ensuring accurate tracking of dynamic transitions and interactions. Results on 10 real-world datasets demonstrate that PTMT achieves speedups ranging from 12.0$\times$ to 50.3$\times$ compared to the SOTA method.
Knowledge Bridger: Towards Training-free Missing Multi-modality Completion
Feb 27, 2025Previous successful approaches to missing modality completion rely on carefully designed fusion techniques and extensive pre-training on complete data, which can limit their generalizability in out-of-domain (OOD) scenarios. In this study, we pose a new challenge: can we develop a missing modality completion model that is both resource-efficient and robust to OOD generalization? To address this, we present a training-free framework for missing modality completion that leverages large multimodal models (LMMs). Our approach, termed the "Knowledge Bridger", is modality-agnostic and integrates generation and ranking of missing modalities. By defining domain-specific priors, our method automatically extracts structured information from available modalities to construct knowledge graphs. These extracted graphs connect the missing modality generation and ranking modules through the LMM, resulting in high-quality imputations of missing modalities. Experimental results across both general and medical domains show that our approach consistently outperforms competing methods, including in OOD generalization. Additionally, our knowledge-driven generation and ranking techniques demonstrate superiority over variants that directly employ LMMs for generation and ranking, offering insights that may be valuable for applications in other domains.
Global Graph Propagation with Hierarchical Information Transfer for Incomplete Contrastive Multi-view Clustering
Feb 26, 2025



Incomplete multi-view clustering has become one of the important research problems due to the extensive missing multi-view data in the real world. Although the existing methods have made great progress, there are still some problems: 1) most methods cannot effectively mine the information hidden in the missing data; 2) most methods typically divide representation learning and clustering into two separate stages, but this may affect the clustering performance as the clustering results directly depend on the learned representation. To address these problems, we propose a novel incomplete multi-view clustering method with hierarchical information transfer. Firstly, we design the view-specific Graph Convolutional Networks (GCN) to obtain the representation encoding the graph structure, which is then fused into the consensus representation. Secondly, considering that one layer of GCN transfers one-order neighbor node information, the global graph propagation with the consensus representation is proposed to handle the missing data and learn deep representation. Finally, we design a weight-sharing pseudo-classifier with contrastive learning to obtain an end-to-end framework that combines view-specific representation learning, global graph propagation with hierarchical information transfer, and contrastive clustering for joint optimization. Extensive experiments conducted on several commonly-used datasets demonstrate the effectiveness and superiority of our method in comparison with other state-of-the-art approaches. The code is available at https://github.com/KelvinXuu/GHICMC.
CDW-CoT: Clustered Distance-Weighted Chain-of-Thoughts Reasoning
Jan 21, 2025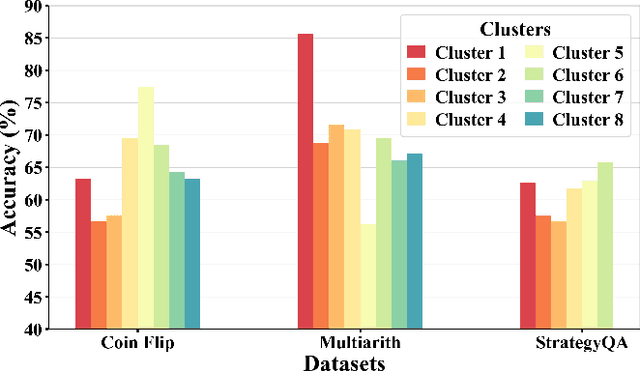
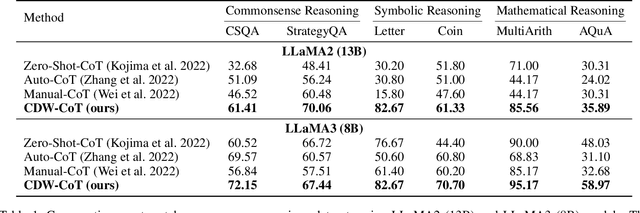
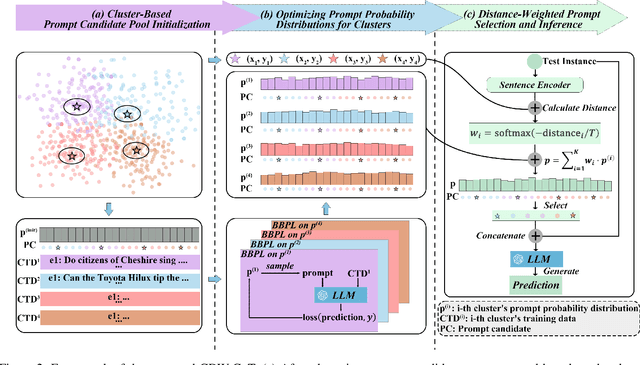
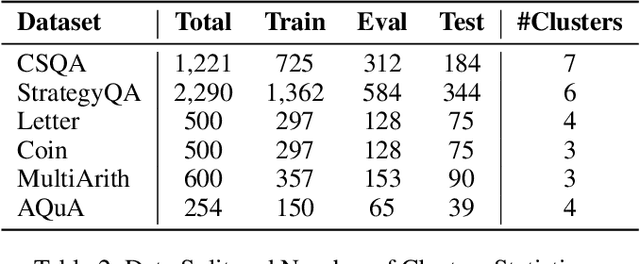
Large Language Models (LLMs) have recently achieved impressive results in complex reasoning tasks through Chain of Thought (CoT) prompting. However, most existing CoT methods rely on using the same prompts, whether manually designed or automatically generated, to handle the entire dataset. This one-size-fits-all approach may fail to meet the specific needs arising from the diversities within a single dataset. To solve this problem, we propose the Clustered Distance-Weighted Chain of Thought (CDW-CoT) method, which dynamically constructs prompts tailored to the characteristics of each data instance by integrating clustering and prompt optimization techniques. Our method employs clustering algorithms to categorize the dataset into distinct groups, from which a candidate pool of prompts is selected to reflect the inherent diversity within the dataset. For each cluster, CDW-CoT trains the optimal prompt probability distribution tailored to their specific characteristics. Finally, it dynamically constructs a unique prompt probability distribution for each test instance, based on its proximity to cluster centers, from which prompts are selected for reasoning. CDW-CoT consistently outperforms traditional CoT methods across six datasets, including commonsense, symbolic, and mathematical reasoning tasks. Specifically, when compared to manual CoT, CDW-CoT achieves an average accuracy improvement of 25.34% on LLaMA2 (13B) and 15.72% on LLaMA3 (8B).
OTLRM: Orthogonal Learning-based Low-Rank Metric for Multi-Dimensional Inverse Problems
Dec 15, 2024

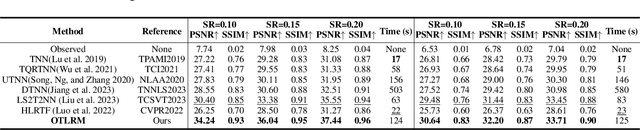

In real-world scenarios, complex data such as multispectral images and multi-frame videos inherently exhibit robust low-rank property. This property is vital for multi-dimensional inverse problems, such as tensor completion, spectral imaging reconstruction, and multispectral image denoising. Existing tensor singular value decomposition (t-SVD) definitions rely on hand-designed or pre-given transforms, which lack flexibility for defining tensor nuclear norm (TNN). The TNN-regularized optimization problem is solved by the singular value thresholding (SVT) operator, which leverages the t-SVD framework to obtain the low-rank tensor. However, it is quite complicated to introduce SVT into deep neural networks due to the numerical instability problem in solving the derivatives of the eigenvectors. In this paper, we introduce a novel data-driven generative low-rank t-SVD model based on the learnable orthogonal transform, which can be naturally solved under its representation. Prompted by the linear algebra theorem of the Householder transformation, our learnable orthogonal transform is achieved by constructing an endogenously orthogonal matrix adaptable to neural networks, optimizing it as arbitrary orthogonal matrices. Additionally, we propose a low-rank solver as a generalization of SVT, which utilizes an efficient representation of generative networks to obtain low-rank structures. Extensive experiments highlight its significant restoration enhancements.
Incomplete Contrastive Multi-View Clustering with High-Confidence Guiding
Dec 14, 2023Incomplete multi-view clustering becomes an important research problem, since multi-view data with missing values are ubiquitous in real-world applications. Although great efforts have been made for incomplete multi-view clustering, there are still some challenges: 1) most existing methods didn't make full use of multi-view information to deal with missing values; 2) most methods just employ the consistent information within multi-view data but ignore the complementary information; 3) For the existing incomplete multi-view clustering methods, incomplete multi-view representation learning and clustering are treated as independent processes, which leads to performance gap. In this work, we proposed a novel Incomplete Contrastive Multi-View Clustering method with high-confidence guiding (ICMVC). Firstly, we proposed a multi-view consistency relation transfer plus graph convolutional network to tackle missing values problem. Secondly, instance-level attention fusion and high-confidence guiding are proposed to exploit the complementary information while instance-level contrastive learning for latent representation is designed to employ the consistent information. Thirdly, an end-to-end framework is proposed to integrate multi-view missing values handling, multi-view representation learning and clustering assignment for joint optimization. Experiments compared with state-of-the-art approaches demonstrated the effectiveness and superiority of our method. Our code is publicly available at https://github.com/liunian-Jay/ICMVC.