 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3CAD: Towards Generic Cooperative Autonomous Driving Benchmark
May 10, 2025We introduce M$^3$CAD, a novel benchmark designed to advance research in generic cooperative autonomous driving. M$^3$CAD comprises 204 sequences with 30k frames, spanning a diverse range of cooperative driving scenarios. Each sequence includes multiple vehicles and sensing modalities, e.g., LiDAR point clouds, RGB images, and GPS/IMU, supporting a variety of autonomous driving tasks, including object detection and tracking, mapping, motion forecasting, occupancy prediction, and path planning. This rich multimodal setup enables M$^3$CAD to support both single-vehicle and multi-vehicle autonomous driving research, significantly broadening the scope of research in the field. To our knowledge, M$^3$CAD is the most comprehensive benchmark specifically tailored for cooperative multi-task autonomous driving research. We evaluate the state-of-the-art end-to-end solution on M$^3$CAD to establish baseline performance. To foster cooperative autonomous driving research, we also propose E2EC, a simple yet effective framework for cooperative driving solution that leverages inter-vehicle shared information for improved path planning. We release M$^3$CAD, along with our baseline models and evaluation results, to support the development of robust cooperative autonomous driving systems. All resources will be made publicly available on https://github.com/zhumorui/M3CAD
HEAD: A Bandwidth-Efficient Cooperative Perception Approach for Heterogeneous Connected and Autonomous Vehicles
Aug 27, 2024



In cooperative perception studies, there is often a trade-off between communication bandwidth and perception performance. While current feature fusion solutions are known for their excellent object detection performance, transmitting the entire sets of intermediate feature maps requires substantial bandwidth. Furthermore, these fusion approaches are typically limited to vehicles that use identical detection models. Our goal is to develop a solution that supports cooperative perception across vehicles equipped with different modalities of sensors. This method aims to deliver improved perception performance compared to late fusion techniques, while achieving precision similar to the state-of-art intermediate fusion, but requires an order of magnitude less bandwidth. We propose HEAD, a method that fuses features from the classification and regression heads in 3D object detection networks. Our method is compatible with heterogeneous detection networks such as LiDAR PointPillars, SECOND, VoxelNet, and camera Bird's-eye View (BEV) Encoder. Given the naturally smaller feature size in the detection heads, we design a self-attention mechanism to fuse the classification head and a complementary feature fusion layer to fuse the regression head. Our experiments, comprehensively evaluated on the V2V4Real and OPV2V datasets, demonstrate that HEAD is a fusion method that effectively balances communication bandwidth and perception performance.
A Clustering-guided Contrastive Fusion for Multi-view Representation Learning
Jan 05, 2023



The past two decades have seen increasingly rapid advances in the field of multi-view representation learning due to it extracting useful information from diverse domains to facilitate the development of multi-view applications. However, the community faces two challenges: i) how to learn robust representations from a large amount of unlabeled data to against noise or incomplete views setting, and ii) how to balance view consistency and complementary for various downstream tasks. To this end, we utilize a deep fusion network to fuse view-specific representations into the view-common representation, extracting high-level semantics for obtaining robust representation. In addition, we employ a clustering task to guide the fusion network to prevent it from leading to trivial solutions. For balancing consistency and complementary, then, we design an asymmetrical contrastive strategy that aligns the view-common representation and each view-specific representation. These modules are incorporated into a unified method known as CLustering-guided cOntrastiVE fusioN (CLOVEN). We quantitatively and qualitatively evaluate the proposed method on five datasets, demonstrating that CLOVEN outperforms 11 competitive multi-view learning methods in clustering and classification. In the incomplete view scenario, our proposed method resists noise interference better than those of our competitors. Furthermore, the visualization analysis shows that CLOVEN can preserve the intrinsic structure of view-specific representation while also improving the compactness of view-commom representation. Our source code will be available soon at https://github.com/guanzhou-ke/cloven.
MORI-RAN: Multi-view Robust Representation Learning via Hybrid Contrastive Fusion
Aug 30, 2022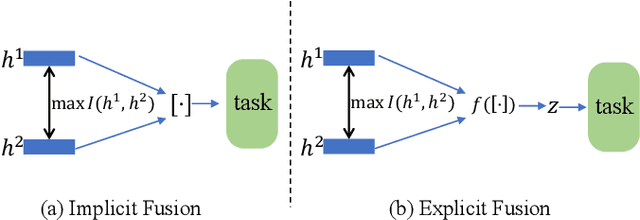
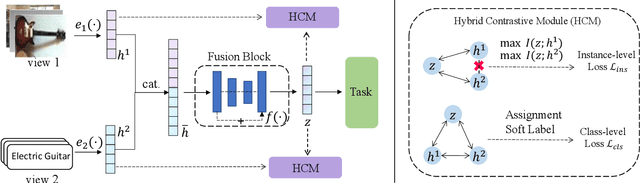
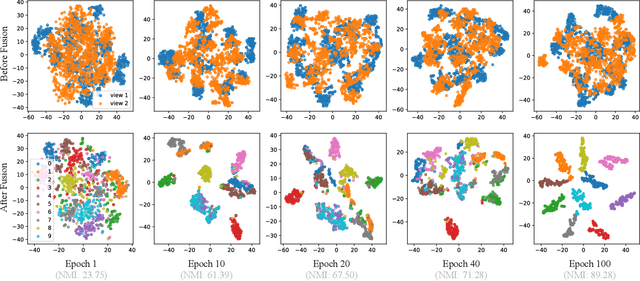
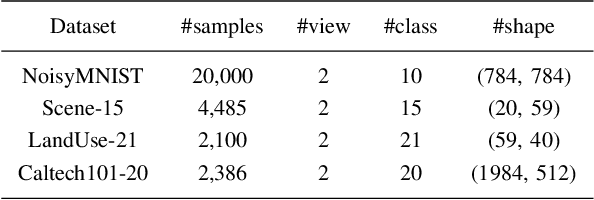
Multi-view representation learning is essential for many multi-view tasks, such as clustering and classification. However, there are two challenging problems plaguing the community: i)how to learn robust multi-view representation from mass unlabeled data and ii) how to balance the view consistency and the view specificity. To this end, in this paper, we proposed a hybrid contrastive fusion algorithm to extract robust view-common representation from unlabeled data. Specifically, we found that introducing an additional representation space and aligning representations on this space enables the model to learn robust view-common representations. At the same time, we designed an asymmetric contrastive strategy to ensure that the model does not obtain trivial solutions. Experimental results demonstrated that the proposed method outperforms 12 competitive multi-view methods on four real-world datasets in terms of clustering and classification. Our source code will be available soon at \url{https://github.com/guanzhou-ke/mori-ran}.