 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Bridger: Towards Training-free Missing Multi-modality Completion
Feb 27, 2025Previous successful approaches to missing modality completion rely on carefully designed fusion techniques and extensive pre-training on complete data, which can limit their generalizability in out-of-domain (OOD) scenarios. In this study, we pose a new challenge: can we develop a missing modality completion model that is both resource-efficient and robust to OOD generalization? To address this, we present a training-free framework for missing modality completion that leverages large multimodal models (LMMs). Our approach, termed the "Knowledge Bridger", is modality-agnostic and integrates generation and ranking of missing modalities. By defining domain-specific priors, our method automatically extracts structured information from available modalities to construct knowledge graphs. These extracted graphs connect the missing modality generation and ranking modules through the LMM, resulting in high-quality imputations of missing modalities. Experimental results across both general and medical domains show that our approach consistently outperforms competing methods, including in OOD generalization. Additionally, our knowledge-driven generation and ranking techniques demonstrate superiority over variants that directly employ LMMs for generation and ranking, offering insights that may be valuable for applications in other domains.
Rethinking Multi-view Representation Learning via Distilled Disentangling
Mar 29, 2024
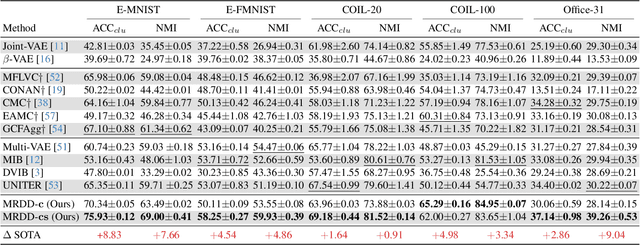
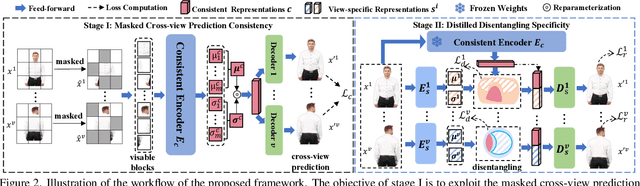
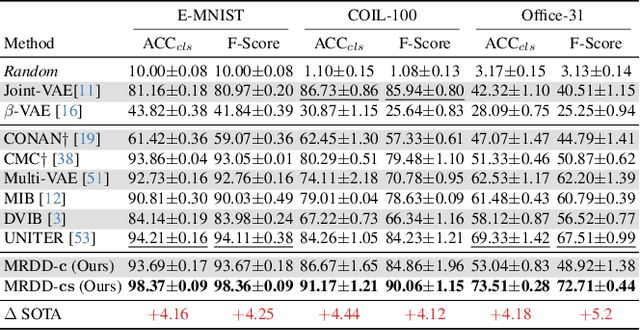
Multi-view representation learning aims to derive robust representations that are both view-consistent and view-specific from diverse data sources. This paper presents an in-depth analysis of existing approaches in this domain, highlighting a commonly overlooked aspect: the redundancy between view-consistent and view-specific representations. To this end, we propose an innovative framework for multi-view representation learning, which incorporates a technique we term 'distilled disentangling'. Our method introduces the concept of masked cross-view prediction, enabling the extraction of compact, high-quality view-consistent representations from various sources without incurring extra computational overhead. Additionally, we develop a distilled disentangling module that efficiently filters out consistency-related information from multi-view representations, resulting in purer view-specific representations. This approach significantly reduces redundancy between view-consistent and view-specific representations, enhancing the overall efficiency of the learning process. Our empirical evaluations reveal that higher mask ratios substantially improve the quality of view-consistent representations. Moreover, we find that reducing the dimensionality of view-consistent representations relative to that of view-specific representations further refines the quality of the combined representations. Our code is accessible at: https://github.com/Guanzhou-Ke/MRDD.
Disentangling Multi-view Representations Beyond Inductive Bias
Aug 04, 2023



Multi-view (or -modality) representation learning aims to understand the relationships between different view representations. Existing methods disentangle multi-view representations into consistent and view-specific representations by introducing strong inductive biases, which can limit their generalization ability. In this paper, we propose a novel multi-view representation disentangling method that aims to go beyond inductive biases, ensuring both interpretability and generalizability of the resulting representations. Our method is based on the observation that discovering multi-view consistency in advance can determine the disentangling information boundary, leading to a decoupled learning objective. We also found that the consistency can be easily extracted by maximizing the transformation invariance and clustering consistency between views. These observations drive us to propose a two-stage framework. In the first stage, we obtain multi-view consistency by training a consistent encoder to produce semantically-consistent representations across views as well as their corresponding pseudo-labels. In the second stage, we disentangle specificity from comprehensive representations by minimizing the upper bound of mutual information between consistent and comprehensive representations. Finally, we reconstruct the original data by concatenating pseudo-labels and view-specific representations. Our experiments on four multi-view datasets demonstrate that our proposed method outperforms 12 comparison methods in terms of clustering and classification performance. The visualization results also show that the extracted consistency and specificity are compact and interpretable. Our code can be found at \url{https://github.com/Guanzhou-Ke/DMRIB}.
* 9 pages, 5 figures, 4 tables
A Clustering-guided Contrastive Fusion for Multi-view Representation Learning
Jan 05, 2023



The past two decades have seen increasingly rapid advances in the field of multi-view representation learning due to it extracting useful information from diverse domains to facilitate the development of multi-view applications. However, the community faces two challenges: i) how to learn robust representations from a large amount of unlabeled data to against noise or incomplete views setting, and ii) how to balance view consistency and complementary for various downstream tasks. To this end, we utilize a deep fusion network to fuse view-specific representations into the view-common representation, extracting high-level semantics for obtaining robust representation. In addition, we employ a clustering task to guide the fusion network to prevent it from leading to trivial solutions. For balancing consistency and complementary, then, we design an asymmetrical contrastive strategy that aligns the view-common representation and each view-specific representation. These modules are incorporated into a unified method known as CLustering-guided cOntrastiVE fusioN (CLOVEN). We quantitatively and qualitatively evaluate the proposed method on five datasets, demonstrating that CLOVEN outperforms 11 competitive multi-view learning methods in clustering and classification. In the incomplete view scenario, our proposed method resists noise interference better than those of our competitors. Furthermore, the visualization analysis shows that CLOVEN can preserve the intrinsic structure of view-specific representation while also improving the compactness of view-commom representation. Our source code will be available soon at https://github.com/guanzhou-ke/cloven.
MORI-RAN: Multi-view Robust Representation Learning via Hybrid Contrastive Fusion
Aug 30, 2022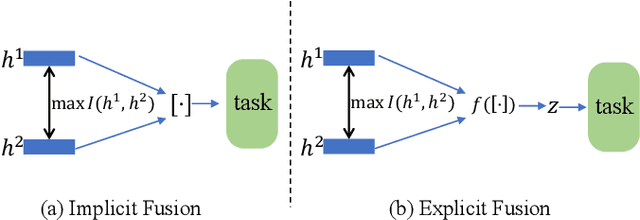
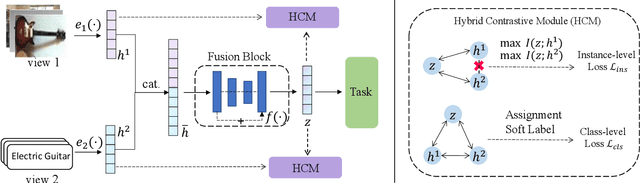
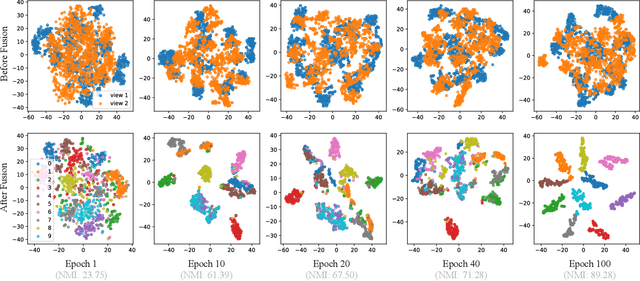
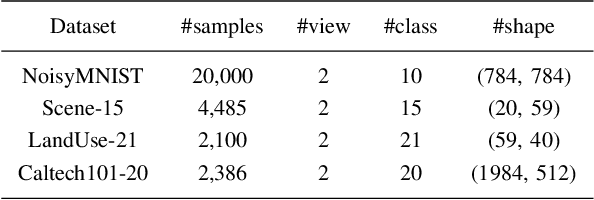
Multi-view representation learning is essential for many multi-view tasks, such as clustering and classification. However, there are two challenging problems plaguing the community: i)how to learn robust multi-view representation from mass unlabeled data and ii) how to balance the view consistency and the view specificity. To this end, in this paper, we proposed a hybrid contrastive fusion algorithm to extract robust view-common representation from unlabeled data. Specifically, we found that introducing an additional representation space and aligning representations on this space enables the model to learn robust view-common representations. At the same time, we designed an asymmetric contrastive strategy to ensure that the model does not obtain trivial solutions. Experimental results demonstrated that the proposed method outperforms 12 competitive multi-view methods on four real-world datasets in terms of clustering and classification. Our source code will be available soon at \url{https://github.com/guanzhou-ke/mori-ran}.