 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORI-RAN: Multi-view Robust Representation Learning via Hybrid Contrastive Fusion
Paper and Code
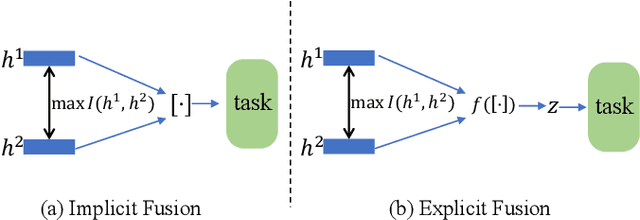
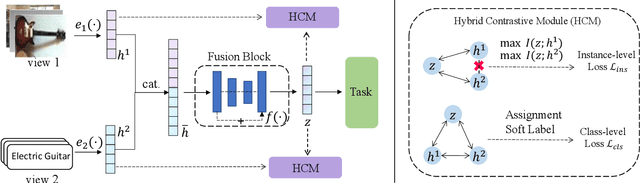
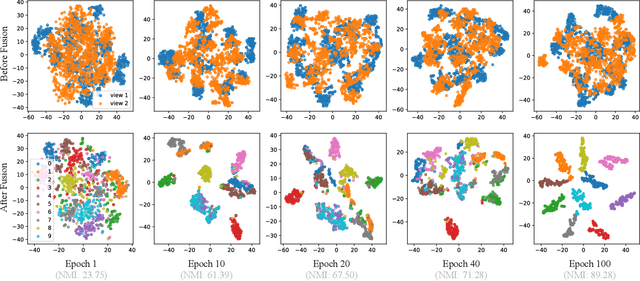
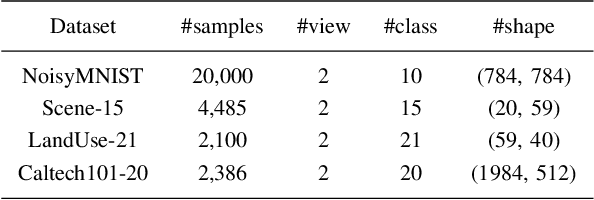
Multi-view representation learning is essential for many multi-view tasks, such as clustering and classification. However, there are two challenging problems plaguing the community: i)how to learn robust multi-view representation from mass unlabeled data and ii) how to balance the view consistency and the view specificity. To this end, in this paper, we proposed a hybrid contrastive fusion algorithm to extract robust view-common representation from unlabeled data. Specifically, we found that introducing an additional representation space and aligning representations on this space enables the model to learn robust view-common representations. At the same time, we designed an asymmetric contrastive strategy to ensure that the model does not obtain trivial solutions. Experimental results demonstrated that the proposed method outperforms 12 competitive multi-view methods on four real-world datasets in terms of clustering and classification. Our source code will be available soon at \url{https://github.com/guanzhou-ke/mori-ran}.