 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization-Guided Foreground Augmentation in Autonomous Driving
Apr 21, 2026Autonomous driving systems often degrade under adverse visibility conditions-such as rain, nighttime, or snow-where online scene geometry (e.g., lane dividers, road boundaries, and pedestrian crossings) becomes sparse or fragmented. While high-definition (HD) maps can provide missing structural context, they are costly to construct and maintain at scale. We propose Localization-Guided Foreground Augmentation (LG-FA), a lightweight and plug-and-play inference module that enhances foreground perception by enriching geometric context online. LG-FA: (i) incrementally constructs a sparse global vector layer from per-frame Bird's-Eye View (BEV) predictions; (ii) estimates ego pose via class-constrained geometric alignment, jointly improving localization and completing missing local topology; and (iii) reprojects the augmented foreground into a unified global frame to improve per-frame predictions. Experiments on challenging nuScenes sequences demonstrate that LG-FA improves the geometric completeness and temporal stability of BEV representations, reduces localization error, and produces globally consistent lane and topology reconstructions. The module can be seamlessly integrated into existing BEV-based perception systems without backbone modification. By providing a reliable geometric context prior, LG-FA enhances temporal consistency and supplies stable structural support for downstream modules such as tracking and decision-making.
CooperDrive: Enhancing Driving Decisions Through Cooperative Perception
Apr 15, 2026Autonomous vehicles equipped with robust onboard perception, localization, and planning still face limitations in occlusion and non-line-of-sight (NLOS) scenarios, where delayed reactions can increase collision risk. We propose CooperDrive, a cooperative perception framework that augments situational awareness and enables earlier, safer driving decisions. CooperDrive offers two key advantages: (i) each vehicle retains its native perception, localization, and planning stack, and (ii) a lightweight object-level sharing and fusion strategy bridges perception and planning. Specifically, CooperDrive reuses detector Bird's-Eye View (BEV) features to estimate accurate vehicle poses without additional heavy encoders, thereby reconstructing BEV representations and feeding the planner with low latency. On the planning side, CooperDrive leverages the expanded object set to anticipate potential conflicts earlier and adjust speed and trajectory proactively, thereby transforming reactive behaviors into predictive and safer driving decisions. Real-world closed-loop tests at occlusion-heavy NLOS intersections demonstrate that CooperDrive increases reaction lead time, minimum time-to-collision (TTC), and stopping margin, while requiring only 90 kbps bandwidth and maintaining an average end-to-end latency of 89 ms.
M3CAD: Towards Generic Cooperative Autonomous Driving Benchmark
May 10, 2025We introduce M$^3$CAD, a novel benchmark designed to advance research in generic cooperative autonomous driving. M$^3$CAD comprises 204 sequences with 30k frames, spanning a diverse range of cooperative driving scenarios. Each sequence includes multiple vehicles and sensing modalities, e.g., LiDAR point clouds, RGB images, and GPS/IMU, supporting a variety of autonomous driving tasks, including object detection and tracking, mapping, motion forecasting, occupancy prediction, and path planning. This rich multimodal setup enables M$^3$CAD to support both single-vehicle and multi-vehicle autonomous driving research, significantly broadening the scope of research in the field. To our knowledge, M$^3$CAD is the most comprehensive benchmark specifically tailored for cooperative multi-task autonomous driving research. We evaluate the state-of-the-art end-to-end solution on M$^3$CAD to establish baseline performance. To foster cooperative autonomous driving research, we also propose E2EC, a simple yet effective framework for cooperative driving solution that leverages inter-vehicle shared information for improved path planning. We release M$^3$CAD, along with our baseline models and evaluation results, to support the development of robust cooperative autonomous driving systems. All resources will be made publicly available on https://github.com/zhumorui/M3CAD
HEAD: A Bandwidth-Efficient Cooperative Perception Approach for Heterogeneous Connected and Autonomous Vehicles
Aug 27, 2024



In cooperative perception studies, there is often a trade-off between communication bandwidth and perception performance. While current feature fusion solutions are known for their excellent object detection performance, transmitting the entire sets of intermediate feature maps requires substantial bandwidth. Furthermore, these fusion approaches are typically limited to vehicles that use identical detection models. Our goal is to develop a solution that supports cooperative perception across vehicles equipped with different modalities of sensors. This method aims to deliver improved perception performance compared to late fusion techniques, while achieving precision similar to the state-of-art intermediate fusion, but requires an order of magnitude less bandwidth. We propose HEAD, a method that fuses features from the classification and regression heads in 3D object detection networks. Our method is compatible with heterogeneous detection networks such as LiDAR PointPillars, SECOND, VoxelNet, and camera Bird's-eye View (BEV) Encoder. Given the naturally smaller feature size in the detection heads, we design a self-attention mechanism to fuse the classification head and a complementary feature fusion layer to fuse the regression head. Our experiments, comprehensively evaluated on the V2V4Real and OPV2V datasets, demonstrate that HEAD is a fusion method that effectively balances communication bandwidth and perception performance.
Real-time Motion Planning for autonomous vehicles in dynamic environments
Jun 05, 2024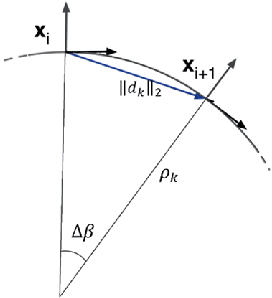
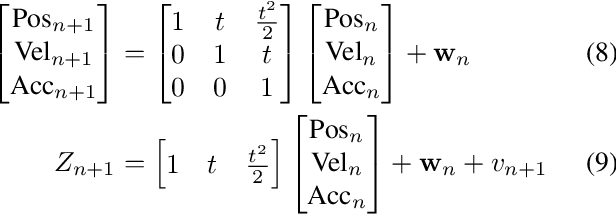
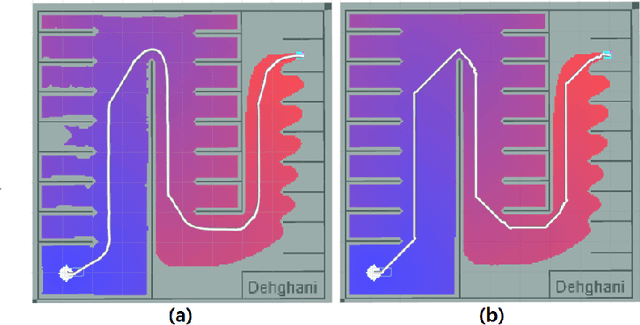
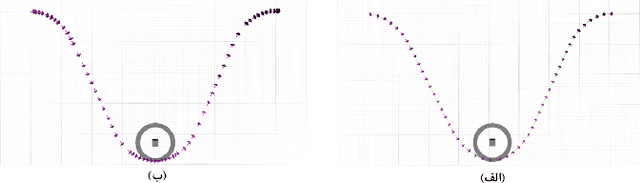
Recent advancements in self-driving car technologies have enabled them to navigate autonomously through various environments. However, one of the critical challenges in autonomous vehicle operation is trajectory planning, especially in dynamic environments with moving obstacles. This research aims to tackle this challenge by proposing a robust algorithm tailored for autonomous cars operating in dynamic environments with moving obstacles. The algorithm introduces two main innovations. Firstly, it defines path density by adjusting the number of waypoints along the trajectory, optimizing their distribution for accuracy in curved areas and reducing computational complexity in straight sections. Secondly, it integrates hierarchical motion planning algorithms, combining global planning with an enhanced $A^*$ graph-based method and local planning using the time elastic band algorithm with moving obstacle detection considering different motion models. The proposed algorithm is adaptable for different vehicle types and mobile robots, making it versatile for real-world applications. Simulation results demonstrate its effectiveness across various conditions, promising safer and more efficient navigation for autonomous vehicles in dynamic environments. These modifications significantly improve trajectory planning capabilities, addressing a crucial aspect of autonomous vehicle technology.
VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection
Dec 26, 2023In recent times, there has been a notable surge in multimodal approaches that decorates raw LiDAR point clouds with camera-derived features to improve object detection performance. However, we found that these methods still grapple with the inherent sparsity of LiDAR point cloud data, primarily because fewer points are enriched with camera-derived features for sparsely distributed objects. We present an innovative approach that involves the generation of virtual LiDAR points using camera images and enhancing these virtual points with semantic labels obtained from image-based segmentation networks to tackle this issue and facilitate the detection of sparsely distributed objects, particularly those that are occluded or distant. Furthermore, we integrate a distance aware data augmentation (DADA) technique to enhance the models capability to recognize these sparsely distributed objects by generating specialized training samples. Our approach offers a versatile solution that can be seamlessly integrated into various 3D frameworks and 2D semantic segmentation methods, resulting in significantly improved overall detection accuracy. Evaluation on the KITTI and nuScenes datasets demonstrates substantial enhancements in both 3D and birds eye view (BEV) detection benchmarks
Facial Emotion Recognition using CNN in PyTorch
Dec 17, 2023In this project, we have implemented a model to recognize real-time facial emotions given the camera images. Current approaches would read all data and input it into their model, which has high space complexity. Our model is based on the Convolutional Neural Network utilizing the PyTorch library. We believe our implementation will significantly improve the space complexity and provide a useful contribution to facial emotion recognition. Our motivation is to understanding clearly about deep learning, particularly in CNNs, and analysis real-life scenarios. Therefore, we tunned the hyper parameter of model such as learning rate, batch size, and number of epochs to meet our needs. In addition, we also used techniques to optimize the networks, such as activation function, dropout and max pooling. Finally, we analyzed the result from two optimizer to observe the relationship between number of epochs and accuracy.
SiCP: Simultaneous Individual and Cooperative Perception for 3D Object Detection in Connected and Automated Vehicles
Dec 08, 2023Cooperative perception for connected and automated vehicles is traditionally achieved through the fusion of feature maps from two or more vehicles. However, the absence of feature maps shared from other vehicles can lead to a significant decline in object detection performance for cooperative perception models compared to standalone 3D detection models. This drawback impedes the adoption of cooperative perception as vehicle resources are often insufficient to concurrently employ two perception models. To tackle this issue, we present Simultaneous Individual and Cooperative Perception (SiCP), a generic framework that supports a wide range of the state-of-the-art standalone perception backbones and enhances them with a novel Dual-Perception Network (DP-Net) designed to facilitate both individual and cooperative perception. In addition to its lightweight nature with only 0.13M parameters, DP-Net is robust and retains crucial gradient information during feature map fusion. As demonstrated in a comprehensive evaluation on the OPV2V dataset, thanks to DP-Net, SiCP surpasses state-of-the-art cooperative perception solutions while preserving the performance of standalone perception solutions.