 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF3DGS: Federated 3D Gaussian Splatting for Decentralized Multi-Agent World Modeling
Apr 02, 2026We present F3DGS, a federated 3D Gaussian Splatting framework for decentralized multi-agent 3D reconstruction. Existing 3DGS pipelines assume centralized access to all observations, which limits their applicability in distributed robotic settings where agents operate independently, and centralized data aggregation may be restricted. Directly extending centralized training to multi-agent systems introduces communication overhead and geometric inconsistency. F3DGS first constructs a shared geometric scaffold by registering locally merged LiDAR point clouds from multiple clients to initialize a global 3DGS model. During federated optimization, Gaussian positions are fixed to preserve geometric alignment, while each client updates only appearance-related attributes, including covariance, opacity, and spherical harmonic coefficients. The server aggregates these updates using visibility-aware aggregation, weighting each client's contribution by how frequently it observed each Gaussian, resolving the partial-observability challenge inherent to multi-agent exploration. To evaluate decentralized reconstruction, we collect a multi-sequence indoor dataset with synchronized LiDAR, RGB, and IMU measurements. Experiments show that F3DGS achieves reconstruction quality comparable to centralized training while enabling distributed optimization across agents. The dataset, development kit, and source code will be publicly released.
Mind the Hitch: Dynamic Calibration and Articulated Perception for Autonomous Trucks
Mar 24, 2026Autonomous trucking poses unique challenges due to articulated tractor-trailer geometry, and time-varying sensor poses caused by the fifth-wheel joint and trailer flex. Existing perception and calibration methods assume static baselines or rely on high-parallax and texture-rich scenes, limiting their reliability under real-world settings. We propose dCAP (dynamic Calibration and Articulated Perception), a vision-based framework that continuously estimates the 6-DoF (degree of freedom) relative pose between tractor and trailer cameras. dCAP employs a transformer with cross-view and temporal attention to robustly aggregate spatial cues while maintaining temporal consistency, enabling accurate perception under rapid articulation and occlusion. Integrated with BEVFormer, dCAP improves 3D object detection by replacing static calibration with dynamically predicted extrinsics. To facilitate evaluation, we introduce STT4AT, a CARLA-based benchmark simulating semi-trailer trucks with synchronized multi-sensor suites and time-varying inter-rig geometry across diverse environments. Experiments demonstrate that dCAP achieves stable, accurate perception while addressing the limitations of static calibration in autonomous trucking. The dataset, development kit, and source code will be publicly released.
M3CAD: Towards Generic Cooperative Autonomous Driving Benchmark
May 10, 2025We introduce M$^3$CAD, a novel benchmark designed to advance research in generic cooperative autonomous driving. M$^3$CAD comprises 204 sequences with 30k frames, spanning a diverse range of cooperative driving scenarios. Each sequence includes multiple vehicles and sensing modalities, e.g., LiDAR point clouds, RGB images, and GPS/IMU, supporting a variety of autonomous driving tasks, including object detection and tracking, mapping, motion forecasting, occupancy prediction, and path planning. This rich multimodal setup enables M$^3$CAD to support both single-vehicle and multi-vehicle autonomous driving research, significantly broadening the scope of research in the field. To our knowledge, M$^3$CAD is the most comprehensive benchmark specifically tailored for cooperative multi-task autonomous driving research. We evaluate the state-of-the-art end-to-end solution on M$^3$CAD to establish baseline performance. To foster cooperative autonomous driving research, we also propose E2EC, a simple yet effective framework for cooperative driving solution that leverages inter-vehicle shared information for improved path planning. We release M$^3$CAD, along with our baseline models and evaluation results, to support the development of robust cooperative autonomous driving systems. All resources will be made publicly available on https://github.com/zhumorui/M3CAD
DP-GTR: Differentially Private Prompt Protection via Group Text Rewriting
Mar 06, 2025



Prompt privacy is crucial, especially when using online large language models (LLMs), due to the sensitive information often contained within prompts. While LLMs can enhance prompt privacy through text rewriting, existing methods primarily focus on document-level rewriting, neglecting the rich, multi-granular representations of text. This limitation restricts LLM utilization to specific tasks, overlooking their generalization and in-context learning capabilities, thus hindering practical application. To address this gap, we introduce DP-GTR, a novel three-stage framework that leverages local differential privacy (DP) and the composition theorem via group text rewriting. DP-GTR is the first framework to integrate both document-level and word-level information while exploiting in-context learning to simultaneously improve privacy and utility, effectively bridging local and global DP mechanisms at the individual data point level. Experiments on CommonSense QA and DocVQA demonstrate that DP-GTR outperforms existing approaches, achieving a superior privacy-utility trade-off. Furthermore, our framework is compatible with existing rewriting techniques, serving as a plug-in to enhance privacy protection. Our code is publicly available at https://github.com/FatShion-FTD/DP-GTR for reproducibility.
GSOT3D: Towards Generic 3D Single Object Tracking in the Wild
Dec 03, 2024In this paper, we present a novel benchmark, GSOT3D, that aims at facilitating development of generic 3D single object tracking (SOT) in the wild. Specifically, GSOT3D offers 620 sequences with 123K frames, and covers a wide selection of 54 object categories. Each sequence is offered with multiple modalities, including the point cloud (PC), RGB image, and depth. This allows GSOT3D to support various 3D tracking tasks, such as single-modal 3D SOT on PC and multi-modal 3D SOT on RGB-PC or RGB-D, and thus greatly broadens research directions for 3D object tracking. To provide highquality per-frame 3D annotations, all sequences are labeled manually with multiple rounds of meticulous inspection and refinement. To our best knowledge, GSOT3D is the largest benchmark dedicated to various generic 3D object tracking tasks. To understand how existing 3D trackers perform and to provide comparisons for future research on GSOT3D, we assess eight representative point cloud-based tracking models. Our evaluation results exhibit that these models heavily degrade on GSOT3D, and more efforts are required for robust and generic 3D object tracking. Besides, to encourage future research, we present a simple yet effective generic 3D tracker, named PROT3D, that localizes the target object via a progressive spatial-temporal network and outperforms all current solutions by a large margin. By releasing GSOT3D, we expect to advance further 3D tracking in future research and applications. Our benchmark and model as well as the evaluation results will be publicly released at our webpage https://github.com/ailovejinx/GSOT3D.
HEAD: A Bandwidth-Efficient Cooperative Perception Approach for Heterogeneous Connected and Autonomous Vehicles
Aug 27, 2024



In cooperative perception studies, there is often a trade-off between communication bandwidth and perception performance. While current feature fusion solutions are known for their excellent object detection performance, transmitting the entire sets of intermediate feature maps requires substantial bandwidth. Furthermore, these fusion approaches are typically limited to vehicles that use identical detection models. Our goal is to develop a solution that supports cooperative perception across vehicles equipped with different modalities of sensors. This method aims to deliver improved perception performance compared to late fusion techniques, while achieving precision similar to the state-of-art intermediate fusion, but requires an order of magnitude less bandwidth. We propose HEAD, a method that fuses features from the classification and regression heads in 3D object detection networks. Our method is compatible with heterogeneous detection networks such as LiDAR PointPillars, SECOND, VoxelNet, and camera Bird's-eye View (BEV) Encoder. Given the naturally smaller feature size in the detection heads, we design a self-attention mechanism to fuse the classification head and a complementary feature fusion layer to fuse the regression head. Our experiments, comprehensively evaluated on the V2V4Real and OPV2V datasets, demonstrate that HEAD is a fusion method that effectively balances communication bandwidth and perception performance.
VirtualPainting: Addressing Sparsity with Virtual Points and Distance-Aware Data Augmentation for 3D Object Detection
Dec 26, 2023In recent times, there has been a notable surge in multimodal approaches that decorates raw LiDAR point clouds with camera-derived features to improve object detection performance. However, we found that these methods still grapple with the inherent sparsity of LiDAR point cloud data, primarily because fewer points are enriched with camera-derived features for sparsely distributed objects. We present an innovative approach that involves the generation of virtual LiDAR points using camera images and enhancing these virtual points with semantic labels obtained from image-based segmentation networks to tackle this issue and facilitate the detection of sparsely distributed objects, particularly those that are occluded or distant. Furthermore, we integrate a distance aware data augmentation (DADA) technique to enhance the models capability to recognize these sparsely distributed objects by generating specialized training samples. Our approach offers a versatile solution that can be seamlessly integrated into various 3D frameworks and 2D semantic segmentation methods, resulting in significantly improved overall detection accuracy. Evaluation on the KITTI and nuScenes datasets demonstrates substantial enhancements in both 3D and birds eye view (BEV) detection benchmarks
SiCP: Simultaneous Individual and Cooperative Perception for 3D Object Detection in Connected and Automated Vehicles
Dec 08, 2023Cooperative perception for connected and automated vehicles is traditionally achieved through the fusion of feature maps from two or more vehicles. However, the absence of feature maps shared from other vehicles can lead to a significant decline in object detection performance for cooperative perception models compared to standalone 3D detection models. This drawback impedes the adoption of cooperative perception as vehicle resources are often insufficient to concurrently employ two perception models. To tackle this issue, we present Simultaneous Individual and Cooperative Perception (SiCP), a generic framework that supports a wide range of the state-of-the-art standalone perception backbones and enhances them with a novel Dual-Perception Network (DP-Net) designed to facilitate both individual and cooperative perception. In addition to its lightweight nature with only 0.13M parameters, DP-Net is robust and retains crucial gradient information during feature map fusion. As demonstrated in a comprehensive evaluation on the OPV2V dataset, thanks to DP-Net, SiCP surpasses state-of-the-art cooperative perception solutions while preserving the performance of standalone perception solutions.
Online Self-Evolving Anomaly Detection in Cloud Computing Environments
Nov 16, 2021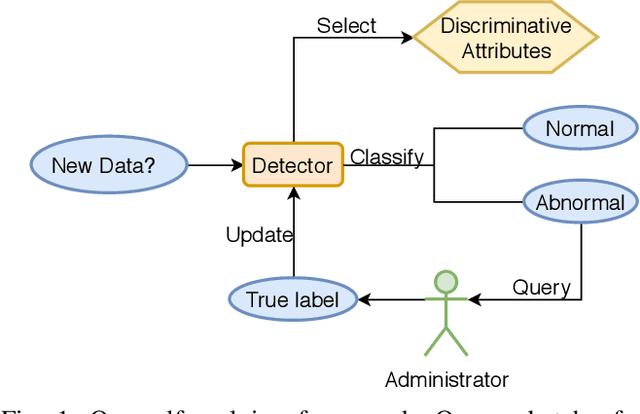
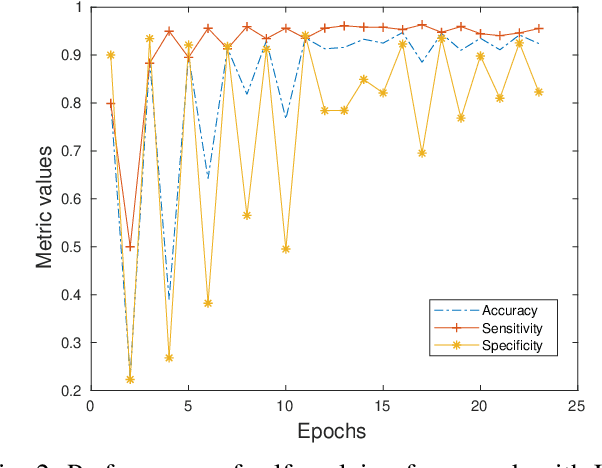

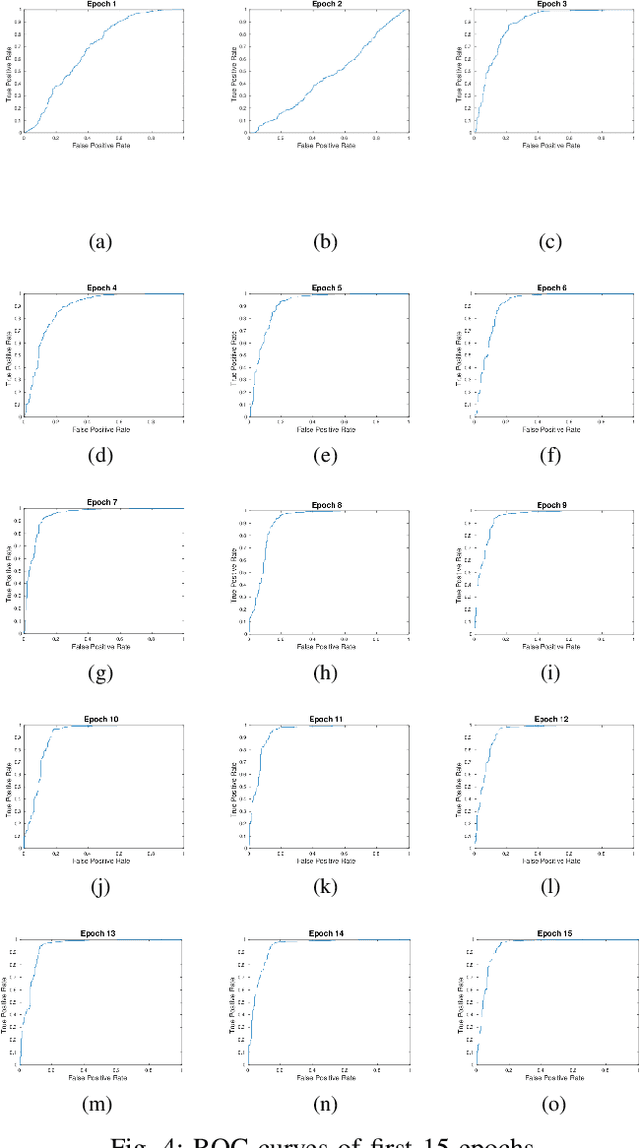
Modern cloud computing systems contain hundreds to thousands of computing and storage servers. Such a scale, combined with ever-growing system complexity, is causing a key challenge to failure and resource management for dependable cloud computing. Autonomic failure detection is a crucial technique for understanding emergent, cloud-wide phenomena and self-managing cloud resources for system-level dependability assurance. To detect failures, we need to monitor the cloud execution and collect runtime performance data. These data are usually unlabeled, and thus a prior failure history is not always available in production clouds. In this paper, we present a \emph{self-evolving anomaly detection} (SEAD) framework for cloud dependability assurance. Our framework self-evolves by recursively exploring newly verified anomaly records and continuously updating the anomaly detector online. As a distinct advantage of our framework, cloud system administrators only need to check a small number of detected anomalies, and their decisions are leveraged to update the detector. Thus, the detector evolves following the upgrade of system hardware, update of the software stack, and change of user workloads. Moreover, we design two types of detectors, one for general anomaly detection and the other for type-specific anomaly detection. With the help of self-evolving techniques, our detectors can achieve 88.94\% in sensitivity and 94.60\% in specificity on average, which makes them suitable for real-world deployment.
CoFF: Cooperative Spatial Feature Fusion for 3D Object Detection on Autonomous Vehicles
Sep 24, 2020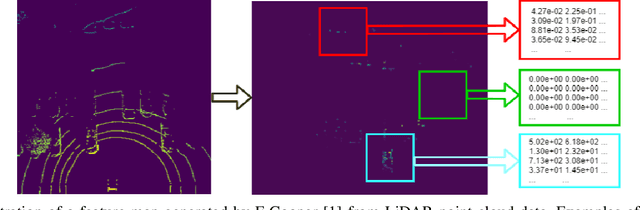

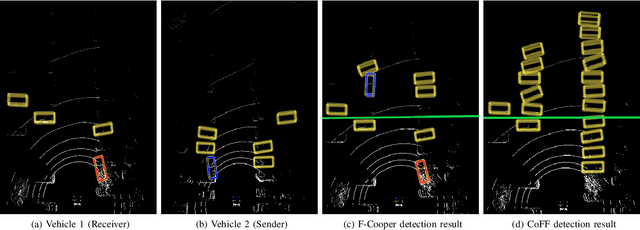
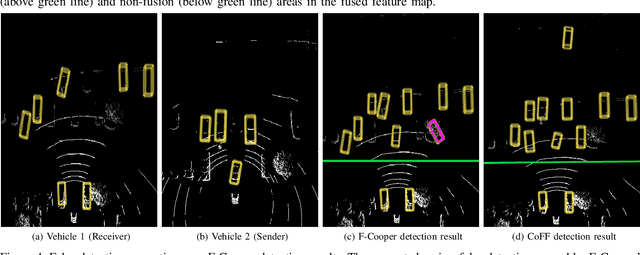
To reduce the amount of transmitted data, feature map based fusion is recently proposed as a practical solution to cooperative 3D object detection by autonomous vehicles. The precision of object detection, however, may require significant improvement, especially for objects that are far away or occluded. To address this critical issue for the safety of autonomous vehicles and human beings, we propose a cooperative spatial feature fusion (CoFF) method for autonomous vehicles to effectively fuse feature maps for achieving a higher 3D object detection performance. Specially, CoFF differentiates weights among feature maps for a more guided fusion, based on how much new semantic information is provided by the received feature maps. It also enhances the inconspicuous features corresponding to far/occluded objects to improve their detection precision. Experimental results show that CoFF achieves a significant improvement in terms of both detection precision and effective detection range for autonomous vehicles, compared to previous feature fusion solutions.