 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Self-Evolving Anomaly Detection in Cloud Computing Environments
Nov 16, 2021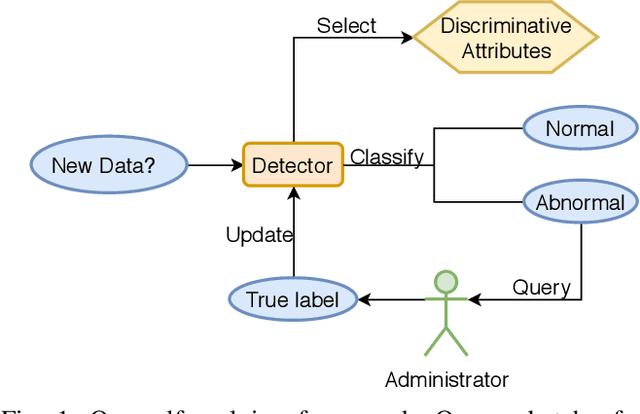
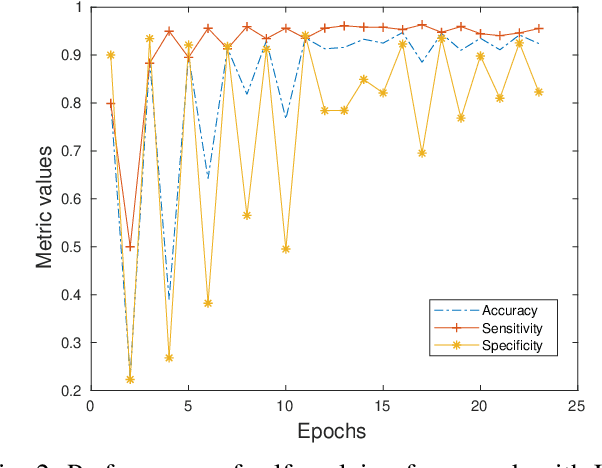

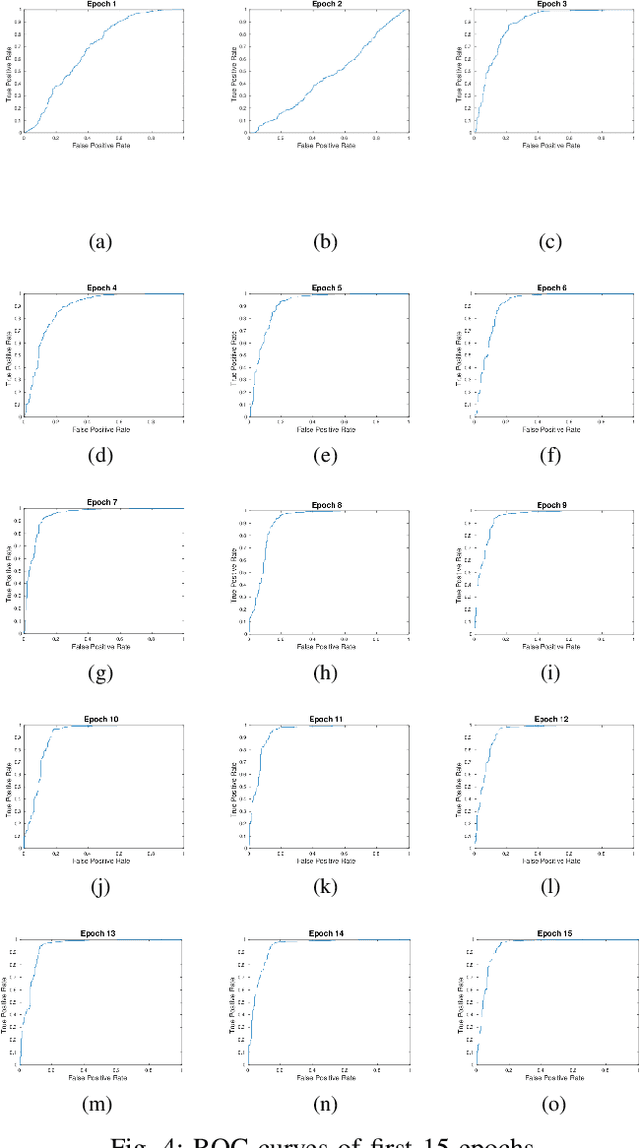
Modern cloud computing systems contain hundreds to thousands of computing and storage servers. Such a scale, combined with ever-growing system complexity, is causing a key challenge to failure and resource management for dependable cloud computing. Autonomic failure detection is a crucial technique for understanding emergent, cloud-wide phenomena and self-managing cloud resources for system-level dependability assurance. To detect failures, we need to monitor the cloud execution and collect runtime performance data. These data are usually unlabeled, and thus a prior failure history is not always available in production clouds. In this paper, we present a \emph{self-evolving anomaly detection} (SEAD) framework for cloud dependability assurance. Our framework self-evolves by recursively exploring newly verified anomaly records and continuously updating the anomaly detector online. As a distinct advantage of our framework, cloud system administrators only need to check a small number of detected anomalies, and their decisions are leveraged to update the detector. Thus, the detector evolves following the upgrade of system hardware, update of the software stack, and change of user workloads. Moreover, we design two types of detectors, one for general anomaly detection and the other for type-specific anomaly detection. With the help of self-evolving techniques, our detectors can achieve 88.94\% in sensitivity and 94.60\% in specificity on average, which makes them suitable for real-world deployment.
CoFF: Cooperative Spatial Feature Fusion for 3D Object Detection on Autonomous Vehicles
Sep 24, 2020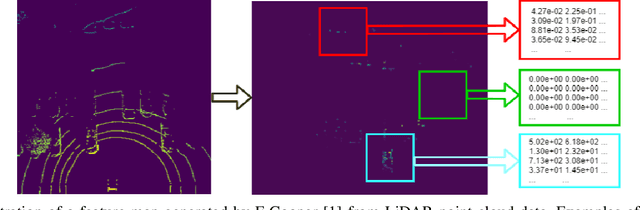

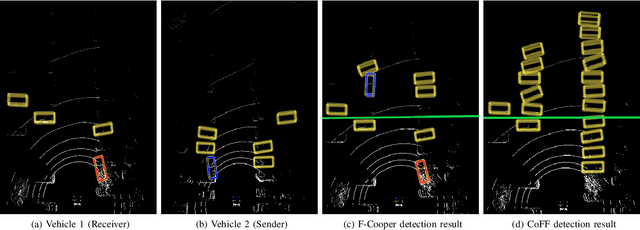
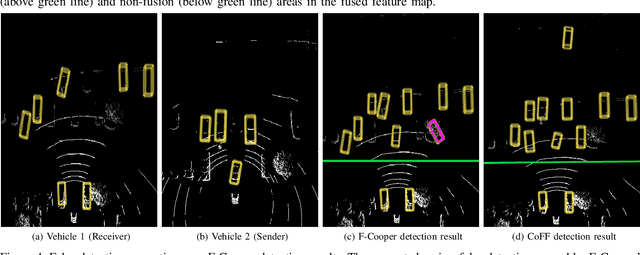
To reduce the amount of transmitted data, feature map based fusion is recently proposed as a practical solution to cooperative 3D object detection by autonomous vehicles. The precision of object detection, however, may require significant improvement, especially for objects that are far away or occluded. To address this critical issue for the safety of autonomous vehicles and human beings, we propose a cooperative spatial feature fusion (CoFF) method for autonomous vehicles to effectively fuse feature maps for achieving a higher 3D object detection performance. Specially, CoFF differentiates weights among feature maps for a more guided fusion, based on how much new semantic information is provided by the received feature maps. It also enhances the inconspicuous features corresponding to far/occluded objects to improve their detection precision. Experimental results show that CoFF achieves a significant improvement in terms of both detection precision and effective detection range for autonomous vehicles, compared to previous feature fusion solutions.
DCANet: Learning Connected Attentions for Convolutional Neural Networks
Jul 09, 2020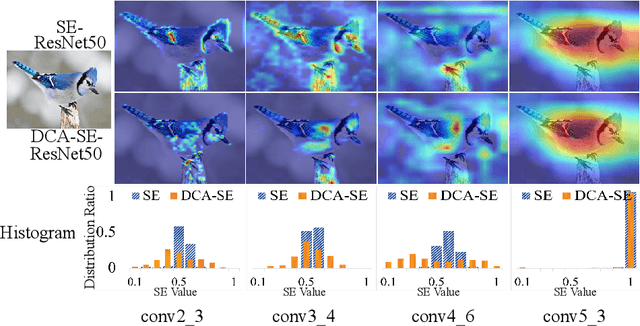

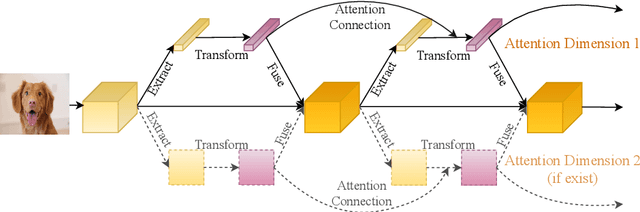

While self-attention mechanism has shown promising results for many vision tasks, it only considers the current features at a time. We show that such a manner cannot take full advantage of the attention mechanism. In this paper, we present Deep Connected Attention Network (DCANet), a novel design that boosts attention modules in a CNN model without any modification of the internal structure. To achieve this, we interconnect adjacent attention blocks, making information flow among attention blocks possible. With DCANet, all attention blocks in a CNN model are trained jointly, which improves the ability of attention learning. Our DCANet is generic. It is not limited to a specific attention module or base network architecture. Experimental results on ImageNet and MS COCO benchmarks show that DCANet consistently outperforms the state-of-the-art attention modules with a minimal additional computational overhead in all test cases. All code and models are made publicly available.