 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Self-Evolving Anomaly Detection in Cloud Computing Environments
Nov 16, 2021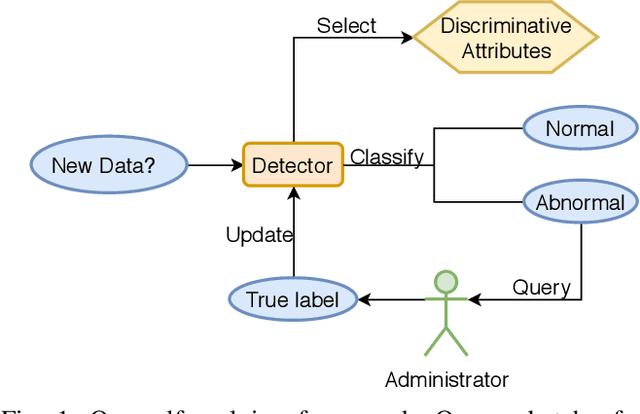
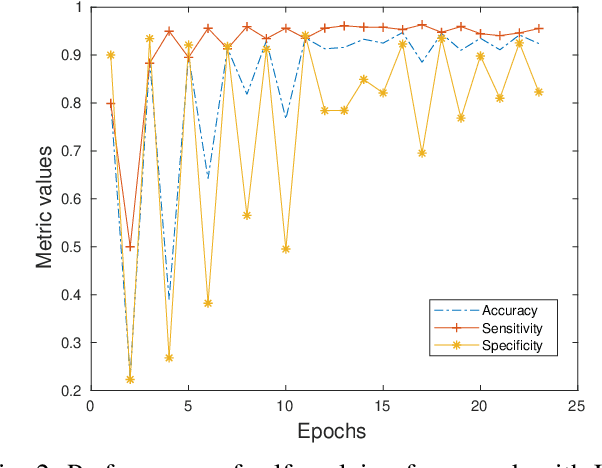

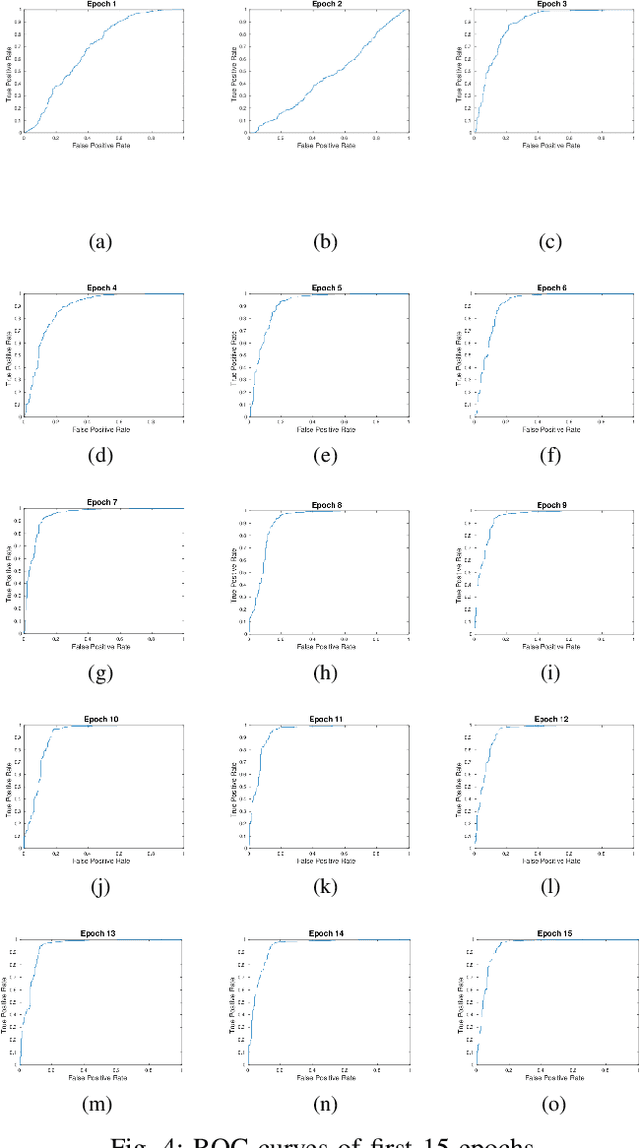
Modern cloud computing systems contain hundreds to thousands of computing and storage servers. Such a scale, combined with ever-growing system complexity, is causing a key challenge to failure and resource management for dependable cloud computing. Autonomic failure detection is a crucial technique for understanding emergent, cloud-wide phenomena and self-managing cloud resources for system-level dependability assurance. To detect failures, we need to monitor the cloud execution and collect runtime performance data. These data are usually unlabeled, and thus a prior failure history is not always available in production clouds. In this paper, we present a \emph{self-evolving anomaly detection} (SEAD) framework for cloud dependability assurance. Our framework self-evolves by recursively exploring newly verified anomaly records and continuously updating the anomaly detector online. As a distinct advantage of our framework, cloud system administrators only need to check a small number of detected anomalies, and their decisions are leveraged to update the detector. Thus, the detector evolves following the upgrade of system hardware, update of the software stack, and change of user workloads. Moreover, we design two types of detectors, one for general anomaly detection and the other for type-specific anomaly detection. With the help of self-evolving techniques, our detectors can achieve 88.94\% in sensitivity and 94.60\% in specificity on average, which makes them suitable for real-world deployment.