 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Deep Networks for Scene Recognition
Mar 13, 2023Most deep learning backbones are evaluated on ImageNet. Using scenery images as an example, we conducted extensive experiments to demonstrate the widely accepted principles in network design may result in dramatic performance differences when the data is altered. Exploratory experiments are engaged to explain the underlining cause of the differences. Based on our observation, this paper presents a novel network design methodology: data-oriented network design. In other words, instead of designing universal backbones, the scheming of the networks should treat the characteristics of data as a crucial component. We further proposed a Deep-Narrow Network and Dilated Pooling module, which improved the scene recognition performance using less than half of the computational resources compared to the benchmark network architecture ResNets. The source code is publicly available on https://github.com/ZN-Qiao/Deep-Narrow-Network.
Dual Temperature Helps Contrastive Learning Without Many Negative Samples: Towards Understanding and Simplifying MoCo
Mar 30, 2022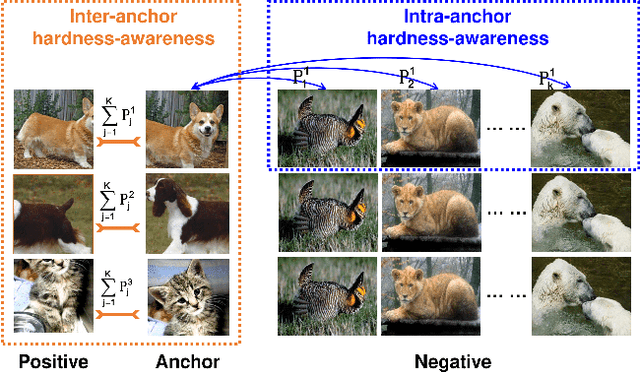

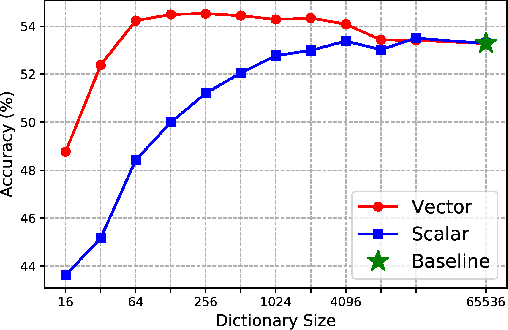
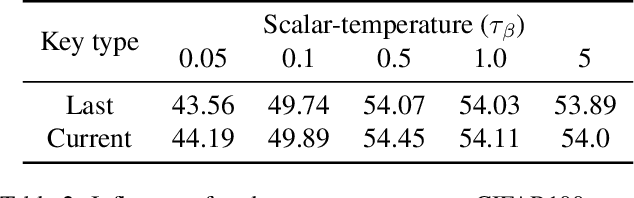
Contrastive learning (CL) is widely known to require many negative samples, 65536 in MoCo for instance, for which the performance of a dictionary-free framework is often inferior because the negative sample size (NSS) is limited by its mini-batch size (MBS). To decouple the NSS from the MBS, a dynamic dictionary has been adopted in a large volume of CL frameworks, among which arguably the most popular one is MoCo family. In essence, MoCo adopts a momentum-based queue dictionary, for which we perform a fine-grained analysis of its size and consistency. We point out that InfoNCE loss used in MoCo implicitly attract anchors to their corresponding positive sample with various strength of penalties and identify such inter-anchor hardness-awareness property as a major reason for the necessity of a large dictionary. Our findings motivate us to simplify MoCo v2 via the removal of its dictionary as well as momentum. Based on an InfoNCE with the proposed dual temperature, our simplified frameworks, SimMoCo and SimCo, outperform MoCo v2 by a visible margin. Moreover, our work bridges the gap between CL and non-CL frameworks, contributing to a more unified understanding of these two mainstream frameworks in SSL. Code is available at: https://bit.ly/3LkQbaT.
Urban land-use analysis using proximate sensing imagery: a survey
Jan 13, 2021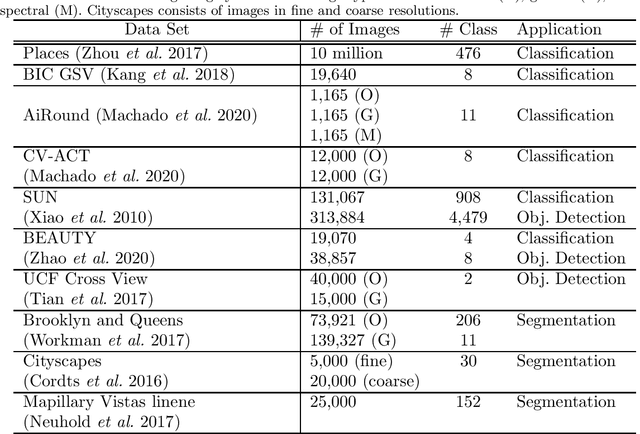

Urban regions are complicated functional systems that are closely associated with and reshaped by human activities. The propagation of online geographic information-sharing platforms and mobile devices equipped with Global Positioning System (GPS) greatly proliferates proximate sensing images taken near or on the ground at a close distance to urban targets. Studies leveraging proximate sensing imagery have demonstrated great potential to address the need for local data in urban land-use analysis. This paper reviews and summarizes the state-of-the-art methods and publicly available datasets from proximate sensing to support land-use analysis. We identify several research problems in the perspective of examples to support training of models and means of integrating diverse data sets. Our discussions highlight the challenges, strategies, and opportunities faced by the existing methods using proximate sensing imagery in urban land-use studies.
DCANet: Learning Connected Attentions for Convolutional Neural Networks
Jul 09, 2020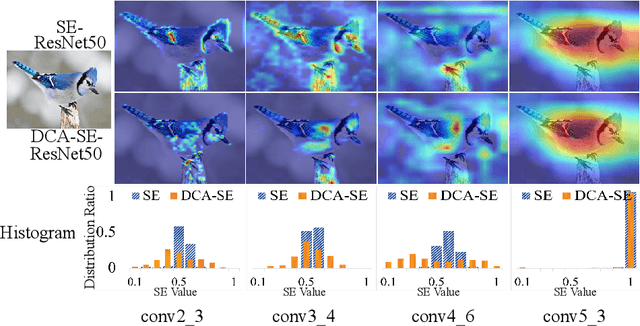

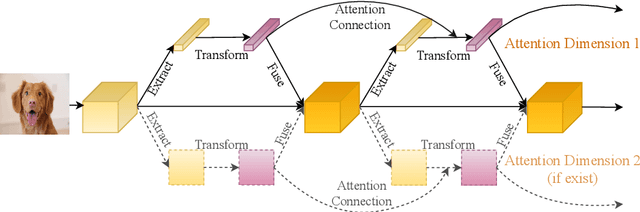

While self-attention mechanism has shown promising results for many vision tasks, it only considers the current features at a time. We show that such a manner cannot take full advantage of the attention mechanism. In this paper, we present Deep Connected Attention Network (DCANet), a novel design that boosts attention modules in a CNN model without any modification of the internal structure. To achieve this, we interconnect adjacent attention blocks, making information flow among attention blocks possible. With DCANet, all attention blocks in a CNN model are trained jointly, which improves the ability of attention learning. Our DCANet is generic. It is not limited to a specific attention module or base network architecture. Experimental results on ImageNet and MS COCO benchmarks show that DCANet consistently outperforms the state-of-the-art attention modules with a minimal additional computational overhead in all test cases. All code and models are made publicly available.