 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hidden Semantic Bottleneck in Conditional Embeddings of Diffusion Transformers
Feb 25, 2026Diffusion Transformers have achieved state-of-the-art performance in class-conditional and multimodal generation, yet the structure of their learned conditional embeddings remains poorly understood. In this work, we present the first systematic study of these embeddings and uncover a notable redundancy: class-conditioned embeddings exhibit extreme angular similarity, exceeding 99\% on ImageNet-1K, while continuous-condition tasks such as pose-guided image generation and video-to-audio generation reach over 99.9\%. We further find that semantic information is concentrated in a small subset of dimensions, with head dimensions carrying the dominant signal and tail dimensions contributing minimally. By pruning low-magnitude dimensions--removing up to two-thirds of the embedding space--we show that generation quality and fidelity remain largely unaffected, and in some cases improve. These results reveal a semantic bottleneck in Transformer-based diffusion models, providing new insights into how semantics are encoded and suggesting opportunities for more efficient conditioning mechanisms.
ITA-MDT: Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On
Mar 26, 2025This paper introduces ITA-MDT, the Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On (IVTON), designed to overcome the limitations of previous approaches by leveraging the Masked Diffusion Transformer (MDT) for improved handling of both global garment context and fine-grained details. The IVTON task involves seamlessly superimposing a garment from one image onto a person in another, creating a realistic depiction of the person wearing the specified garment. Unlike conventional diffusion-based virtual try-on models that depend on large pre-trained U-Net architectures, ITA-MDT leverages a lightweight, scalable transformer-based denoising diffusion model with a mask latent modeling scheme, achieving competitive results while reducing computational overhead. A key component of ITA-MDT is the Image-Timestep Adaptive Feature Aggregator (ITAFA), a dynamic feature aggregator that combines all of the features from the image encoder into a unified feature of the same size, guided by diffusion timestep and garment image complexity. This enables adaptive weighting of features, allowing the model to emphasize either global information or fine-grained details based on the requirements of the denoising stage. Additionally, the Salient Region Extractor (SRE) module is presented to identify complex region of the garment to provide high-resolution local information to the denoising model as an additional condition alongside the global information of the full garment image. This targeted conditioning strategy enhances detail preservation of fine details in highly salient garment regions, optimizing computational resources by avoiding unnecessarily processing entire garment image. Comparative evaluations confirms that ITA-MDT improves efficiency while maintaining strong performance, reaching state-of-the-art results in several metrics.
E-MD3C: Taming Masked Diffusion Transformers for Efficient Zero-Shot Object Customization
Feb 13, 2025We propose E-MD3C ($\underline{E}$fficient $\underline{M}$asked $\underline{D}$iffusion Transformer with Disentangled $\underline{C}$onditions and $\underline{C}$ompact $\underline{C}$ollector), a highly efficient framework for zero-shot object image customization. Unlike prior works reliant on resource-intensive Unet architectures, our approach employs lightweight masked diffusion transformers operating on latent patches, offering significantly improved computational efficiency. The framework integrates three core components: (1) an efficient masked diffusion transformer for processing autoencoder latents, (2) a disentangled condition design that ensures compactness while preserving background alignment and fine details, and (3) a learnable Conditions Collector that consolidates multiple inputs into a compact representation for efficient denoising and learning. E-MD3C outperforms the existing approach on the VITON-HD dataset across metrics such as PSNR, FID, SSIM, and LPIPS, demonstrating clear advantages in parameters, memory efficiency, and inference speed. With only $\frac{1}{4}$ of the parameters, our Transformer-based 468M model delivers $2.5\times$ faster inference and uses $\frac{2}{3}$ of the GPU memory compared to an 1720M Unet-based latent diffusion model.
MDSGen: Fast and Efficient Masked Diffusion Temporal-Aware Transformers for Open-Domain Sound Generation
Oct 03, 2024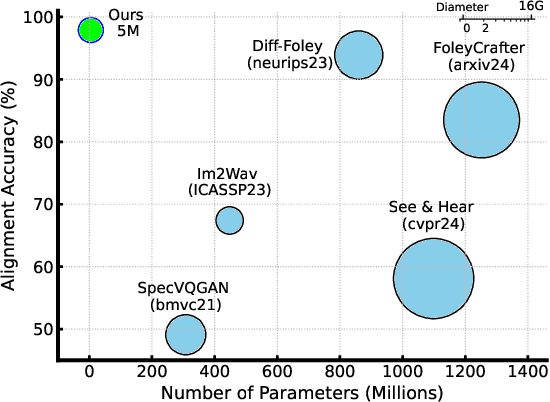
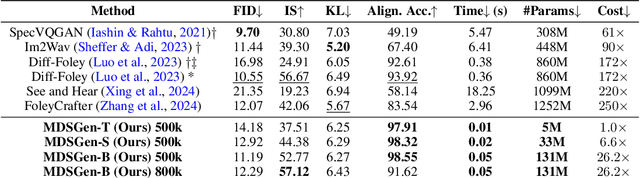
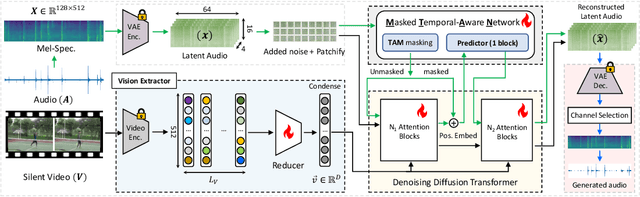
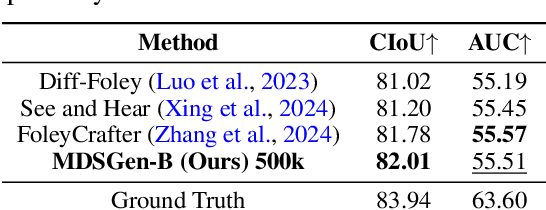
We introduce MDSGen, a novel framework for vision-guided open-domain sound generation optimized for model parameter size, memory consumption, and inference speed. This framework incorporates two key innovations: (1) a redundant video feature removal module that filters out unnecessary visual information, and (2) a temporal-aware masking strategy that leverages temporal context for enhanced audio generation accuracy. In contrast to existing resource-heavy Unet-based models, MDSGen employs denoising masked diffusion transformers, facilitating efficient generation without reliance on pre-trained diffusion models. Evaluated on the benchmark VGGSound dataset, our smallest model (5M parameters) achieves 97.9% alignment accuracy, using 172x fewer parameters, 371% less memory, and offering 36x faster inference than the current 860M-parameter state-of-the-art model (93.9% accuracy). The larger model (131M parameters) reaches nearly 99% accuracy while requiring 6.5x fewer parameters. These results highlight the scalability and effectiveness of our approach.
Cross-view Masked Diffusion Transformers for Person Image Synthesis
Feb 02, 2024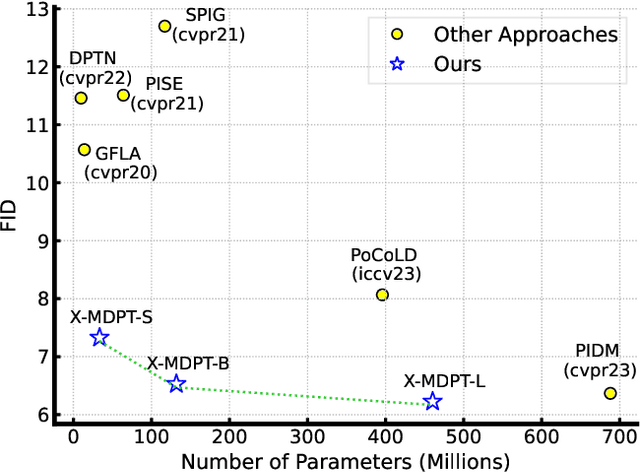


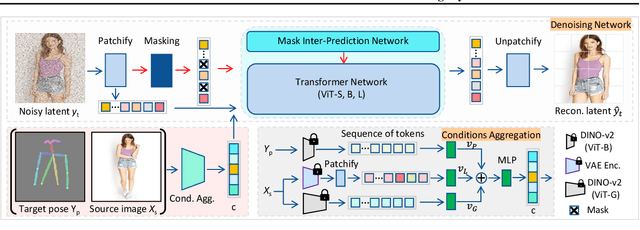
We present X-MDPT (Cross-view Masked Diffusion Prediction Transformers), a novel diffusion model designed for pose-guided human image generation. X-MDPT distinguishes itself by employing masked diffusion transformers that operate on latent patches, a departure from the commonly-used Unet structures in existing works. The model comprises three key modules: 1) a denoising diffusion Transformer, 2) an aggregation network that consolidates conditions into a single vector for the diffusion process, and 3) a mask cross-prediction module that enhances representation learning with semantic information from the reference image. X-MDPT demonstrates scalability, improving FID, SSIM, and LPIPS with larger models. Despite its simple design, our model outperforms state-of-the-art approaches on the DeepFashion dataset while exhibiting efficiency in terms of training parameters, training time, and inference speed. Our compact 33MB model achieves an FID of 7.42, surpassing a prior Unet latent diffusion approach (FID 8.07) using only $11\times$ fewer parameters. Our best model surpasses the pixel-based diffusion with $\frac{2}{3}$ of the parameters and achieves $5.43 \times$ faster inference.
DifAugGAN: A Practical Diffusion-style Data Augmentation for GAN-based Single Image Super-resolution
Nov 30, 2023



It is well known the adversarial optimization of GAN-based image super-resolution (SR) methods makes the preceding SR model generate unpleasant and undesirable artifacts, leading to large distortion. We attribute the cause of such distortions to the poor calibration of the discriminator, which hampers its ability to provide meaningful feedback to the generator for learning high-quality images. To address this problem, we propose a simple but non-travel diffusion-style data augmentation scheme for current GAN-based SR methods, known as DifAugGAN. It involves adapting the diffusion process in generative diffusion models for improving the calibration of the discriminator during training motivated by the successes of data augmentation schemes in the field to achieve good calibration. Our DifAugGAN can be a Plug-and-Play strategy for current GAN-based SISR methods to improve the calibration of the discriminator and thus improve SR performance. Extensive experimental evaluations demonstrate the superiority of DifAugGAN over state-of-the-art GAN-based SISR methods across both synthetic and real-world datasets, showcasing notable advancements in both qualitative and quantitative results.
Learning from Multi-Perception Features for Real-Word Image Super-resolution
May 26, 2023Currently, there are two popular approaches for addressing real-world image super-resolution problems: degradation-estimation-based and blind-based methods. However, degradation-estimation-based methods may be inaccurate in estimating the degradation, making them less applicable to real-world LR images. On the other hand, blind-based methods are often limited by their fixed single perception information, which hinders their ability to handle diverse perceptual characteristics. To overcome this limitation, we propose a novel SR method called MPF-Net that leverages multiple perceptual features of input images. Our method incorporates a Multi-Perception Feature Extraction (MPFE) module to extract diverse perceptual information and a series of newly-designed Cross-Perception Blocks (CPB) to combine this information for effective super-resolution reconstruction. Additionally, we introduce a contrastive regularization term (CR) that improves the model's learning capability by using newly generated HR and LR images as positive and negative samples for ground truth HR. Experimental results on challenging real-world SR datasets demonstrate that our approach significantly outperforms existing state-of-the-art methods in both qualitative and quantitative measures.
CDPMSR: Conditional Diffusion Probabilistic Models for Single Image Super-Resolution
Feb 14, 2023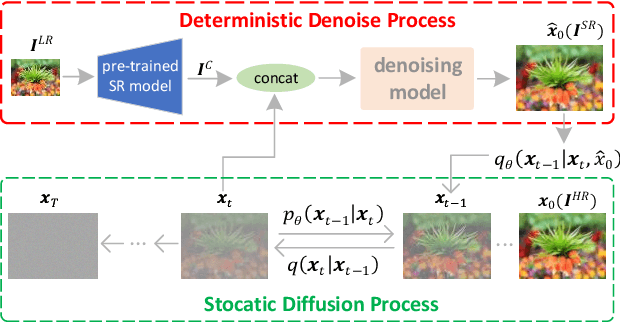
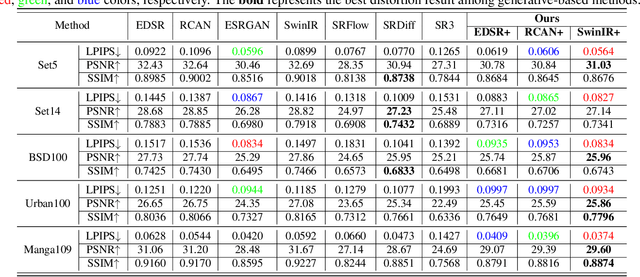

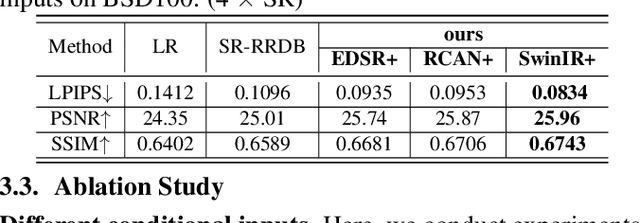
Diffusion probabilistic models (DPM) have been widely adopted in image-to-image translation to generate high-quality images. Prior attempts at applying the DPM to image super-resolution (SR) have shown that iteratively refining a pure Gaussian noise with a conditional image using a U-Net trained on denoising at various-level noises can help obtain a satisfied high-resolution image for the low-resolution one. To further improve the performance and simplify current DPM-based super-resolution methods, we propose a simple but non-trivial DPM-based super-resolution post-process framework,i.e., cDPMSR. After applying a pre-trained SR model on the to-be-test LR image to provide the conditional input, we adapt the standard DPM to conduct conditional image generation and perform super-resolution through a deterministic iterative denoising process. Our method surpasses prior attempts on both qualitative and quantitative results and can generate more photo-realistic counterparts for the low-resolution images with various benchmark datasets including Set5, Set14, Urban100, BSD100, and Manga109. Code will be published after accepted.
Self-Supervised Visual Representation Learning via Residual Momentum
Nov 21, 2022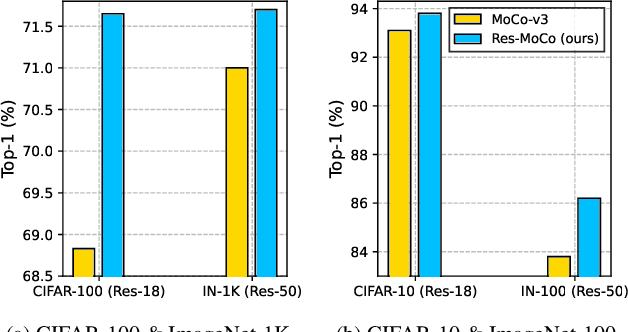
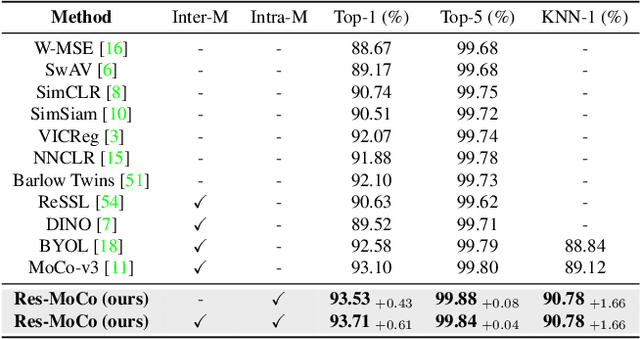
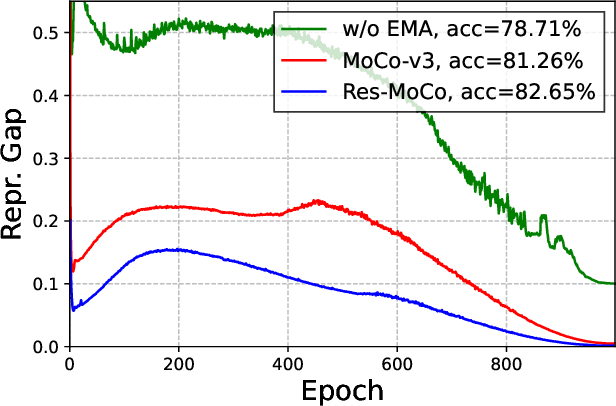
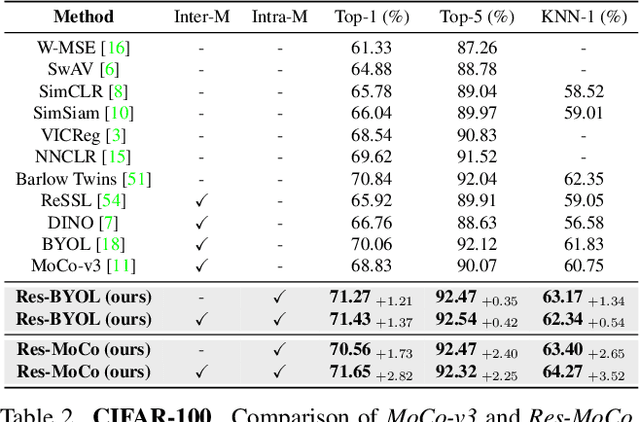
Self-supervised learning (SSL) approaches have shown promising capabilities in learning the representation from unlabeled data. Amongst them, momentum-based frameworks have attracted significant attention. Despite being a great success, these momentum-based SSL frameworks suffer from a large gap in representation between the online encoder (student) and the momentum encoder (teacher), which hinders performance on downstream tasks. This paper is the first to investigate and identify this invisible gap as a bottleneck that has been overlooked in the existing SSL frameworks, potentially preventing the models from learning good representation. To solve this problem, we propose "residual momentum" to directly reduce this gap to encourage the student to learn the representation as close to that of the teacher as possible, narrow the performance gap with the teacher, and significantly improve the existing SSL. Our method is straightforward, easy to implement, and can be easily plugged into other SSL frameworks. Extensive experimental results on numerous benchmark datasets and diverse network architectures have demonstrated the effectiveness of our method over the state-of-the-art contrastive learning baselines.
Dual Temperature Helps Contrastive Learning Without Many Negative Samples: Towards Understanding and Simplifying MoCo
Mar 30, 2022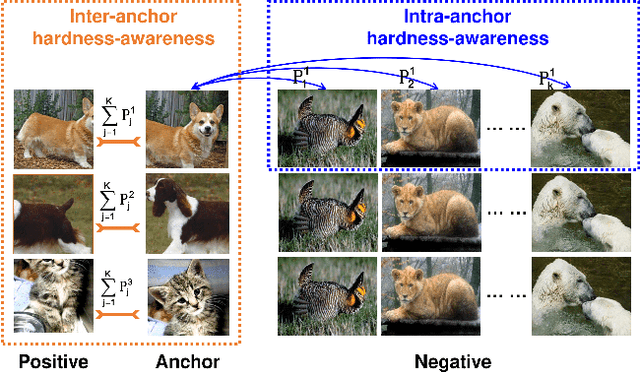

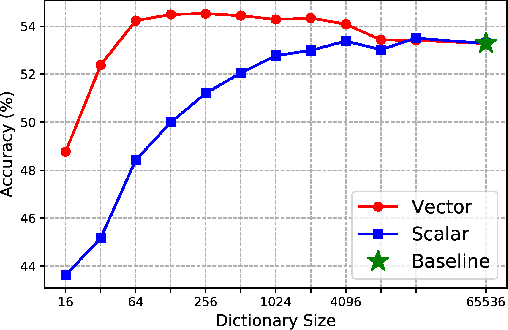
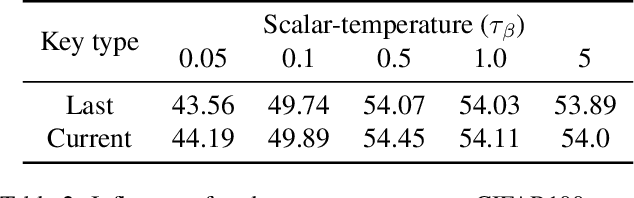
Contrastive learning (CL) is widely known to require many negative samples, 65536 in MoCo for instance, for which the performance of a dictionary-free framework is often inferior because the negative sample size (NSS) is limited by its mini-batch size (MBS). To decouple the NSS from the MBS, a dynamic dictionary has been adopted in a large volume of CL frameworks, among which arguably the most popular one is MoCo family. In essence, MoCo adopts a momentum-based queue dictionary, for which we perform a fine-grained analysis of its size and consistency. We point out that InfoNCE loss used in MoCo implicitly attract anchors to their corresponding positive sample with various strength of penalties and identify such inter-anchor hardness-awareness property as a major reason for the necessity of a large dictionary. Our findings motivate us to simplify MoCo v2 via the removal of its dictionary as well as momentum. Based on an InfoNCE with the proposed dual temperature, our simplified frameworks, SimMoCo and SimCo, outperform MoCo v2 by a visible margin. Moreover, our work bridges the gap between CL and non-CL frameworks, contributing to a more unified understanding of these two mainstream frameworks in SSL. Code is available at: https://bit.ly/3LkQbaT.