 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARO: Timestep-Adaptive Representation Alignment with Onset-Aware Conditioning for Synchronized Video-to-Audio Synthesis
Apr 08, 2025This paper introduces Timestep-Adaptive Representation Alignment with Onset-Aware Conditioning (TARO), a novel framework for high-fidelity and temporally coherent video-to-audio synthesis. Built upon flow-based transformers, which offer stable training and continuous transformations for enhanced synchronization and audio quality, TARO introduces two key innovations: (1) Timestep-Adaptive Representation Alignment (TRA), which dynamically aligns latent representations by adjusting alignment strength based on the noise schedule, ensuring smooth evolution and improved fidelity, and (2) Onset-Aware Conditioning (OAC), which integrates onset cues that serve as sharp event-driven markers of audio-relevant visual moments to enhance synchronization with dynamic visual events. Extensive experiments on the VGGSound and Landscape datasets demonstrate that TARO outperforms prior methods, achieving relatively 53\% lower Frechet Distance (FD), 29% lower Frechet Audio Distance (FAD), and a 97.19% Alignment Accuracy, highlighting its superior audio quality and synchronization precision.
ITA-MDT: Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On
Mar 26, 2025This paper introduces ITA-MDT, the Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On (IVTON), designed to overcome the limitations of previous approaches by leveraging the Masked Diffusion Transformer (MDT) for improved handling of both global garment context and fine-grained details. The IVTON task involves seamlessly superimposing a garment from one image onto a person in another, creating a realistic depiction of the person wearing the specified garment. Unlike conventional diffusion-based virtual try-on models that depend on large pre-trained U-Net architectures, ITA-MDT leverages a lightweight, scalable transformer-based denoising diffusion model with a mask latent modeling scheme, achieving competitive results while reducing computational overhead. A key component of ITA-MDT is the Image-Timestep Adaptive Feature Aggregator (ITAFA), a dynamic feature aggregator that combines all of the features from the image encoder into a unified feature of the same size, guided by diffusion timestep and garment image complexity. This enables adaptive weighting of features, allowing the model to emphasize either global information or fine-grained details based on the requirements of the denoising stage. Additionally, the Salient Region Extractor (SRE) module is presented to identify complex region of the garment to provide high-resolution local information to the denoising model as an additional condition alongside the global information of the full garment image. This targeted conditioning strategy enhances detail preservation of fine details in highly salient garment regions, optimizing computational resources by avoiding unnecessarily processing entire garment image. Comparative evaluations confirms that ITA-MDT improves efficiency while maintaining strong performance, reaching state-of-the-art results in several metrics.
MDSGen: Fast and Efficient Masked Diffusion Temporal-Aware Transformers for Open-Domain Sound Generation
Oct 03, 2024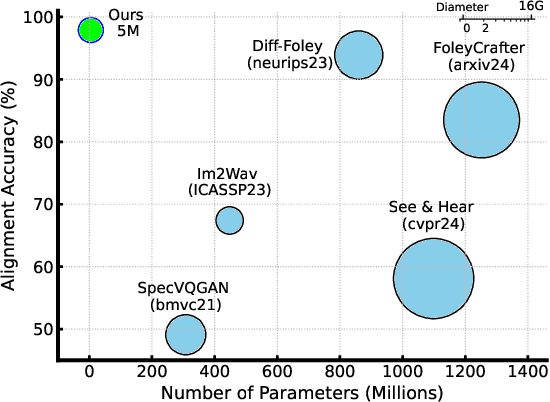
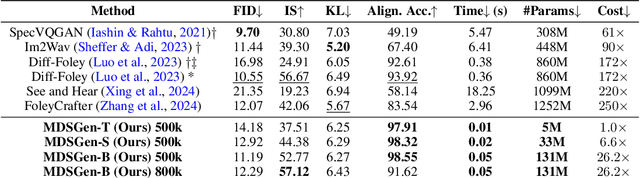
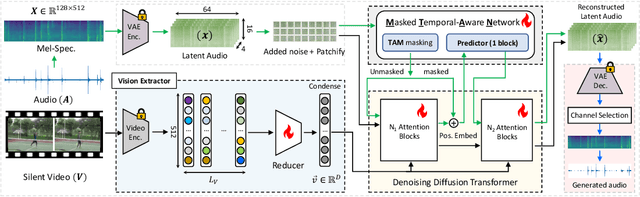
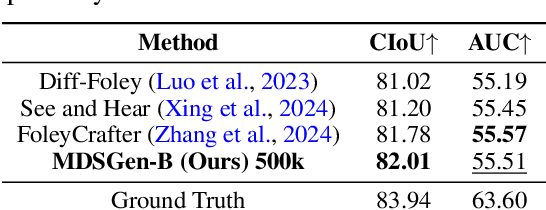
We introduce MDSGen, a novel framework for vision-guided open-domain sound generation optimized for model parameter size, memory consumption, and inference speed. This framework incorporates two key innovations: (1) a redundant video feature removal module that filters out unnecessary visual information, and (2) a temporal-aware masking strategy that leverages temporal context for enhanced audio generation accuracy. In contrast to existing resource-heavy Unet-based models, MDSGen employs denoising masked diffusion transformers, facilitating efficient generation without reliance on pre-trained diffusion models. Evaluated on the benchmark VGGSound dataset, our smallest model (5M parameters) achieves 97.9% alignment accuracy, using 172x fewer parameters, 371% less memory, and offering 36x faster inference than the current 860M-parameter state-of-the-art model (93.9% accuracy). The larger model (131M parameters) reaches nearly 99% accuracy while requiring 6.5x fewer parameters. These results highlight the scalability and effectiveness of our approach.
Zero-Shot Dual-Path Integration Framework for Open-Vocabulary 3D Instance Segmentation
Aug 16, 2024


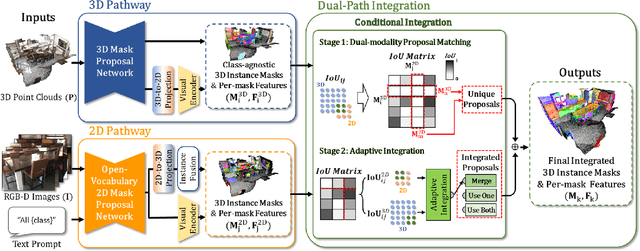
Open-vocabulary 3D instance segmentation transcends traditional closed-vocabulary methods by enabling the identification of both previously seen and unseen objects in real-world scenarios. It leverages a dual-modality approach, utilizing both 3D point clouds and 2D multi-view images to generate class-agnostic object mask proposals. Previous efforts predominantly focused on enhancing 3D mask proposal models; consequently, the information that could come from 2D association to 3D was not fully exploited. This bias towards 3D data, while effective for familiar indoor objects, limits the system's adaptability to new and varied object types, where 2D models offer greater utility. Addressing this gap, we introduce Zero-Shot Dual-Path Integration Framework that equally values the contributions of both 3D and 2D modalities. Our framework comprises three components: 3D pathway, 2D pathway, and Dual-Path Integration. 3D pathway generates spatially accurate class-agnostic mask proposals of common indoor objects from 3D point cloud data using a pre-trained 3D model, while 2D pathway utilizes pre-trained open-vocabulary instance segmentation model to identify a diverse array of object proposals from multi-view RGB-D images. In Dual-Path Integration, our Conditional Integration process, which operates in two stages, filters and merges the proposals from both pathways adaptively. This process harmonizes output proposals to enhance segmentation capabilities. Our framework, utilizing pre-trained models in a zero-shot manner, is model-agnostic and demonstrates superior performance on both seen and unseen data, as evidenced by comprehensive evaluations on the ScanNet200 and qualitative results on ARKitScenes datasets.
On the Perturbed States for Transformed Input-robust Reinforcement Learning
Aug 02, 2024Reinforcement Learning (RL) agents demonstrating proficiency in a training environment exhibit vulnerability to adversarial perturbations in input observations during deployment. This underscores the importance of building a robust agent before its real-world deployment. To alleviate the challenging point, prior works focus on developing robust training-based procedures, encompassing efforts to fortify the deep neural network component's robustness or subject the agent to adversarial training against potent attacks. In this work, we propose a novel method referred to as Transformed Input-robust RL (TIRL), which explores another avenue to mitigate the impact of adversaries by employing input transformation-based defenses. Specifically, we introduce two principles for applying transformation-based defenses in learning robust RL agents: (1) autoencoder-styled denoising to reconstruct the original state and (2) bounded transformations (bit-depth reduction and vector quantization (VQ)) to achieve close transformed inputs. The transformations are applied to the state before feeding it into the policy network. Extensive experiments on multiple MuJoCo environments demonstrate that input transformation-based defenses, i.e., VQ, defend against several adversaries in the state observations. The official code is available at https://github.com/tunglm2203/tirl
Towards Robust Policy: Enhancing Offline Reinforcement Learning with Adversarial Attacks and Defenses
May 18, 2024



Offline reinforcement learning (RL) addresses the challenge of expensive and high-risk data exploration inherent in RL by pre-training policies on vast amounts of offline data, enabling direct deployment or fine-tuning in real-world environments. However, this training paradigm can compromise policy robustness, leading to degraded performance in practical conditions due to observation perturbations or intentional attacks. While adversarial attacks and defenses have been extensively studied in deep learning, their application in offline RL is limited. This paper proposes a framework to enhance the robustness of offline RL models by leveraging advanced adversarial attacks and defenses. The framework attacks the actor and critic components by perturbing observations during training and using adversarial defenses as regularization to enhance the learned policy. Four attacks and two defenses are introduced and evaluated on the D4RL benchmark. The results show the vulnerability of both the actor and critic to attacks and the effectiveness of the defenses in improving policy robustness. This framework holds promise for enhancing the reliability of offline RL models in practical scenarios.