 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Text-to-Image Generation from Pre-Trained Vision-Language Models via Distribution-Conditioned Diffusion Decoding
Mar 11, 2026Recent large-scale vision-language models (VLMs) have shown remarkable text-to-image generation capabilities, yet their visual fidelity remains constrained by the discrete image tokenization, which poses a major challenge. Although several studies have explored continuous representation modeling to enhance visual quality, adapting pre-trained VLM models to such representations requires large-scale data and training costs comparable to the original pre-training. To circumvent this limitation, we propose a diffusion-based decoding framework that enhances image fidelity by training only a diffusion decoder on the output image-token logits of pre-trained VLMs, thereby preserving the original model intact. At its core, Logit-to-Code Distributional Mapping converts the VLM's image-token logits into continuous, distribution-weighted code vectors with uncertainty features, providing an effective conditioning signal for diffusion decoding. A lightweight Logit Calibration aligns training-time proxy logits from the VQ-VAE encoder with VLM-generated logits, mitigating the train-inference gap. Conditioned on these representations, the Distribution-Conditioned Diffusion Decoder generates high-fidelity images. Achieved solely through short training on ImageNet-1K, our method consistently improves visual fidelity for both VQ-VAE reconstructions and text-to-image generations from VLM-predicted tokens.
ITA-MDT: Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On
Mar 26, 2025This paper introduces ITA-MDT, the Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On (IVTON), designed to overcome the limitations of previous approaches by leveraging the Masked Diffusion Transformer (MDT) for improved handling of both global garment context and fine-grained details. The IVTON task involves seamlessly superimposing a garment from one image onto a person in another, creating a realistic depiction of the person wearing the specified garment. Unlike conventional diffusion-based virtual try-on models that depend on large pre-trained U-Net architectures, ITA-MDT leverages a lightweight, scalable transformer-based denoising diffusion model with a mask latent modeling scheme, achieving competitive results while reducing computational overhead. A key component of ITA-MDT is the Image-Timestep Adaptive Feature Aggregator (ITAFA), a dynamic feature aggregator that combines all of the features from the image encoder into a unified feature of the same size, guided by diffusion timestep and garment image complexity. This enables adaptive weighting of features, allowing the model to emphasize either global information or fine-grained details based on the requirements of the denoising stage. Additionally, the Salient Region Extractor (SRE) module is presented to identify complex region of the garment to provide high-resolution local information to the denoising model as an additional condition alongside the global information of the full garment image. This targeted conditioning strategy enhances detail preservation of fine details in highly salient garment regions, optimizing computational resources by avoiding unnecessarily processing entire garment image. Comparative evaluations confirms that ITA-MDT improves efficiency while maintaining strong performance, reaching state-of-the-art results in several metrics.
TPC: Test-time Procrustes Calibration for Diffusion-based Human Image Animation
Oct 31, 2024



Human image animation aims to generate a human motion video from the inputs of a reference human image and a target motion video. Current diffusion-based image animation systems exhibit high precision in transferring human identity into targeted motion, yet they still exhibit irregular quality in their outputs. Their optimal precision is achieved only when the physical compositions (i.e., scale and rotation) of the human shapes in the reference image and target pose frame are aligned. In the absence of such alignment, there is a noticeable decline in fidelity and consistency. Especially, in real-world environments, this compositional misalignment commonly occurs, posing significant challenges to the practical usage of current systems. To this end, we propose Test-time Procrustes Calibration (TPC), which enhances the robustness of diffusion-based image animation systems by maintaining optimal performance even when faced with compositional misalignment, effectively addressing real-world scenarios. The TPC provides a calibrated reference image for the diffusion model, enhancing its capability to understand the correspondence between human shapes in the reference and target images. Our method is simple and can be applied to any diffusion-based image animation system in a model-agnostic manner, improving the effectiveness at test time without additional training.
FlexiEdit: Frequency-Aware Latent Refinement for Enhanced Non-Rigid Editing
Jul 25, 2024

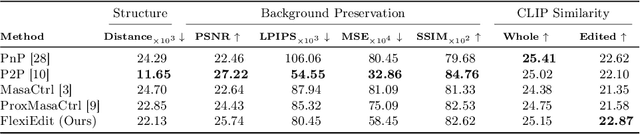

Current image editing methods primarily utilize DDIM Inversion, employing a two-branch diffusion approach to preserve the attributes and layout of the original image. However, these methods encounter challenges with non-rigid edits, which involve altering the image's layout or structure. Our comprehensive analysis reveals that the high-frequency components of DDIM latent, crucial for retaining the original image's key features and layout, significantly contribute to these limitations. Addressing this, we introduce FlexiEdit, which enhances fidelity to input text prompts by refining DDIM latent, by reducing high-frequency components in targeted editing areas. FlexiEdit comprises two key components: (1) Latent Refinement, which modifies DDIM latent to better accommodate layout adjustments, and (2) Edit Fidelity Enhancement via Re-inversion, aimed at ensuring the edits more accurately reflect the input text prompts. Our approach represents notable progress in image editing, particularly in performing complex non-rigid edits, showcasing its enhanced capability through comparative experiments.
FRAG: Frequency Adapting Group for Diffusion Video Editing
Jun 10, 2024
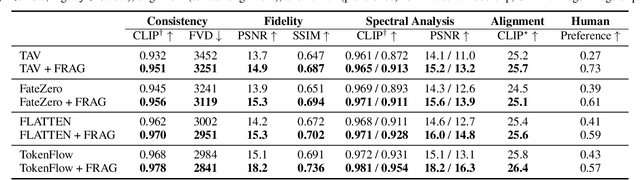
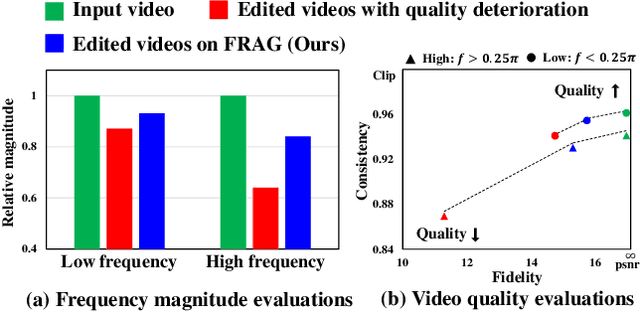
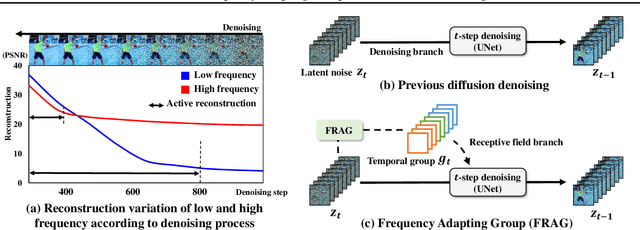
In video editing, the hallmark of a quality edit lies in its consistent and unobtrusive adjustment. Modification, when integrated, must be smooth and subtle, preserving the natural flow and aligning seamlessly with the original vision. Therefore, our primary focus is on overcoming the current challenges in high quality edit to ensure that each edit enhances the final product without disrupting its intended essence. However, quality deterioration such as blurring and flickering is routinely observed in recent diffusion video editing systems. We confirm that this deterioration often stems from high-frequency leak: the diffusion model fails to accurately synthesize high-frequency components during denoising process. To this end, we devise Frequency Adapting Group (FRAG) which enhances the video quality in terms of consistency and fidelity by introducing a novel receptive field branch to preserve high-frequency components during the denoising process. FRAG is performed in a model-agnostic manner without additional training and validates the effectiveness on video editing benchmarks (i.e., TGVE, DAVIS).
Wavelet-Guided Acceleration of Text Inversion in Diffusion-Based Image Editing
Jan 18, 2024



In the field of image editing, Null-text Inversion (NTI) enables fine-grained editing while preserving the structure of the original image by optimizing null embeddings during the DDIM sampling process. However, the NTI process is time-consuming, taking more than two minutes per image. To address this, we introduce an innovative method that maintains the principles of the NTI while accelerating the image editing process. We propose the WaveOpt-Estimator, which determines the text optimization endpoint based on frequency characteristics. Utilizing wavelet transform analysis to identify the image's frequency characteristics, we can limit text optimization to specific timesteps during the DDIM sampling process. By adopting the Negative-Prompt Inversion (NPI) concept, a target prompt representing the original image serves as the initial text value for optimization. This approach maintains performance comparable to NTI while reducing the average editing time by over 80% compared to the NTI method. Our method presents a promising approach for efficient, high-quality image editing based on diffusion models.
Neutral Editing Framework for Diffusion-based Video Editing
Dec 10, 2023


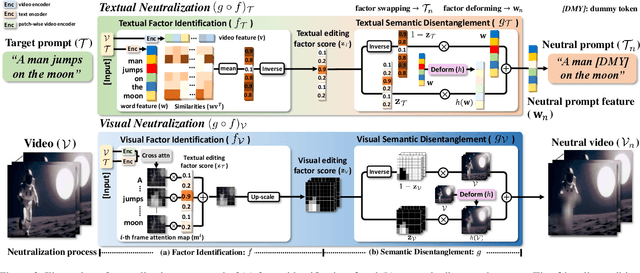
Text-conditioned image editing has succeeded in various types of editing based on a diffusion framework. Unfortunately, this success did not carry over to a video, which continues to be challenging. Existing video editing systems are still limited to rigid-type editing such as style transfer and object overlay. To this end, this paper proposes Neutral Editing (NeuEdit) framework to enable complex non-rigid editing by changing the motion of a person/object in a video, which has never been attempted before. NeuEdit introduces a concept of `neutralization' that enhances a tuning-editing process of diffusion-based editing systems in a model-agnostic manner by leveraging input video and text without any other auxiliary aids (e.g., visual masks, video captions). Extensive experiments on numerous videos demonstrate adaptability and effectiveness of the NeuEdit framework. The website of our work is available here: https://neuedit.github.io
SCANet: Scene Complexity Aware Network for Weakly-Supervised Video Moment Retrieval
Oct 08, 2023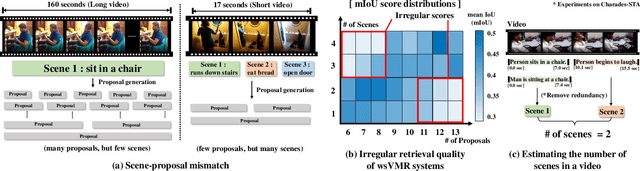
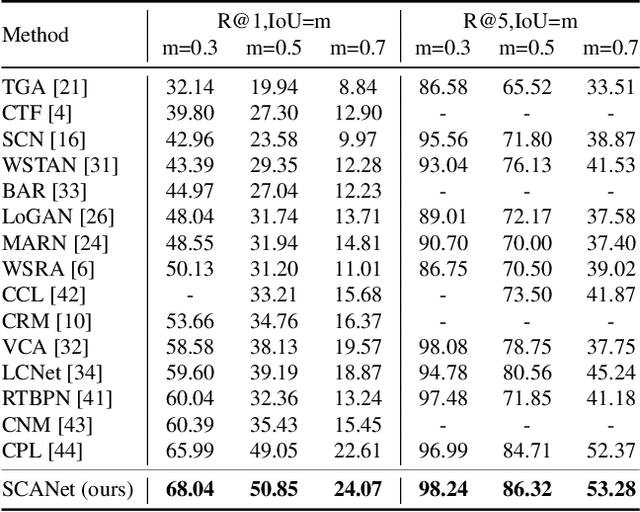
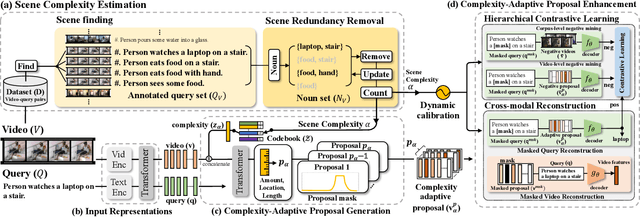

Video moment retrieval aims to localize moments in video corresponding to a given language query. To avoid the expensive cost of annotating the temporal moments, weakly-supervised VMR (wsVMR) systems have been studied. For such systems, generating a number of proposals as moment candidates and then selecting the most appropriate proposal has been a popular approach. These proposals are assumed to contain many distinguishable scenes in a video as candidates. However, existing proposals of wsVMR systems do not respect the varying numbers of scenes in each video, where the proposals are heuristically determined irrespective of the video. We argue that the retrieval system should be able to counter the complexities caused by varying numbers of scenes in each video. To this end, we present a novel concept of a retrieval system referred to as Scene Complexity Aware Network (SCANet), which measures the `scene complexity' of multiple scenes in each video and generates adaptive proposals responding to variable complexities of scenes in each video. Experimental results on three retrieval benchmarks (i.e., Charades-STA, ActivityNet, TVR) achieve state-of-the-art performances and demonstrate the effectiveness of incorporating the scene complexity.