 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed On-Policy Distillation for Vision-Language Reasoning: Steering Gradients for Visual Grounding
May 30, 2026While on-policy distillation offers dense supervision for training small reasoning models, its optimization dynamics in the multimodal domain remain under-explored. In this work, we challenge the standard monolithic view of Vision-Language Model (VLM) distillation by mathematically decomposing the loss into two distinct components: the language prior and visual grounding. Our analysis uncovers that gradient vectors for these components are nearly orthogonal, indicating that the objective of aligning with the teacher's language distribution is geometrically independent from the objective of matching its visual perception. Consequently, standard optimization passively follows a suboptimal compromise trajectory that implicitly balances the two objectives. Hypothesizing that visual grounding constitutes the primary bottleneck for vision-language reasoning, we introduce Visual Gradient Steering (VGS), a method that dynamically reorients the update vector to prioritize the visual subspace. Experimental results on multiple distillation settings and complex multimodal benchmarks demonstrate that VGS significantly outperforms the standard monolithic formulation of on-policy distillation, achieving superior grounding with minimal training overhead.
PDCR: Perception-Decomposed Confidence Reward for Vision-Language Reasoning
May 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) traditionally relies on a sparse, outcome-based signal. Recent work shows that providing a fine-grained, model-intrinsic signal (rewarding the confidence growth in the ground-truth answer) effectively improves language reasoning training by providing step-level guidance without costly external models. While effective for unimodal text, we find that naively applying this global reward to vision-language (V-L) reasoning is a suboptimal strategy, as the task is a heterogeneous mix of sparse visual perception and dense textual reasoning. This global normalization creates mixture-induced signal degradation, where the training signal for visual steps is statistically distorted by the predominant textual steps. We propose Perception-Decomposed Confidence Reward (PDCR), a framework that solves this by aligning the reward structure with the task's heterogeneous nature. PDCR first performs an unsupervised skill decomposition, introducing a model-internal Visual Dependence Score to quantify visual reliance and applying a clustering algorithm to separate perception and reasoning steps. Based on this, PDCR computes a decomposed advantage by normalizing confidence gains within each skill cluster. This intra-cluster normalization provides a stable, correctly-scaled signal for both perception and reasoning. We demonstrate that PDCR outperforms the naive, global-reward formulation and sparse-reward baselines on key V-L reasoning benchmarks.
High-Fidelity Text-to-Image Generation from Pre-Trained Vision-Language Models via Distribution-Conditioned Diffusion Decoding
Mar 11, 2026Recent large-scale vision-language models (VLMs) have shown remarkable text-to-image generation capabilities, yet their visual fidelity remains constrained by the discrete image tokenization, which poses a major challenge. Although several studies have explored continuous representation modeling to enhance visual quality, adapting pre-trained VLM models to such representations requires large-scale data and training costs comparable to the original pre-training. To circumvent this limitation, we propose a diffusion-based decoding framework that enhances image fidelity by training only a diffusion decoder on the output image-token logits of pre-trained VLMs, thereby preserving the original model intact. At its core, Logit-to-Code Distributional Mapping converts the VLM's image-token logits into continuous, distribution-weighted code vectors with uncertainty features, providing an effective conditioning signal for diffusion decoding. A lightweight Logit Calibration aligns training-time proxy logits from the VQ-VAE encoder with VLM-generated logits, mitigating the train-inference gap. Conditioned on these representations, the Distribution-Conditioned Diffusion Decoder generates high-fidelity images. Achieved solely through short training on ImageNet-1K, our method consistently improves visual fidelity for both VQ-VAE reconstructions and text-to-image generations from VLM-predicted tokens.
A Hidden Semantic Bottleneck in Conditional Embeddings of Diffusion Transformers
Feb 25, 2026Diffusion Transformers have achieved state-of-the-art performance in class-conditional and multimodal generation, yet the structure of their learned conditional embeddings remains poorly understood. In this work, we present the first systematic study of these embeddings and uncover a notable redundancy: class-conditioned embeddings exhibit extreme angular similarity, exceeding 99\% on ImageNet-1K, while continuous-condition tasks such as pose-guided image generation and video-to-audio generation reach over 99.9\%. We further find that semantic information is concentrated in a small subset of dimensions, with head dimensions carrying the dominant signal and tail dimensions contributing minimally. By pruning low-magnitude dimensions--removing up to two-thirds of the embedding space--we show that generation quality and fidelity remain largely unaffected, and in some cases improve. These results reveal a semantic bottleneck in Transformer-based diffusion models, providing new insights into how semantics are encoded and suggesting opportunities for more efficient conditioning mechanisms.
TARO: Timestep-Adaptive Representation Alignment with Onset-Aware Conditioning for Synchronized Video-to-Audio Synthesis
Apr 08, 2025This paper introduces Timestep-Adaptive Representation Alignment with Onset-Aware Conditioning (TARO), a novel framework for high-fidelity and temporally coherent video-to-audio synthesis. Built upon flow-based transformers, which offer stable training and continuous transformations for enhanced synchronization and audio quality, TARO introduces two key innovations: (1) Timestep-Adaptive Representation Alignment (TRA), which dynamically aligns latent representations by adjusting alignment strength based on the noise schedule, ensuring smooth evolution and improved fidelity, and (2) Onset-Aware Conditioning (OAC), which integrates onset cues that serve as sharp event-driven markers of audio-relevant visual moments to enhance synchronization with dynamic visual events. Extensive experiments on the VGGSound and Landscape datasets demonstrate that TARO outperforms prior methods, achieving relatively 53\% lower Frechet Distance (FD), 29% lower Frechet Audio Distance (FAD), and a 97.19% Alignment Accuracy, highlighting its superior audio quality and synchronization precision.
ITA-MDT: Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On
Mar 26, 2025This paper introduces ITA-MDT, the Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On (IVTON), designed to overcome the limitations of previous approaches by leveraging the Masked Diffusion Transformer (MDT) for improved handling of both global garment context and fine-grained details. The IVTON task involves seamlessly superimposing a garment from one image onto a person in another, creating a realistic depiction of the person wearing the specified garment. Unlike conventional diffusion-based virtual try-on models that depend on large pre-trained U-Net architectures, ITA-MDT leverages a lightweight, scalable transformer-based denoising diffusion model with a mask latent modeling scheme, achieving competitive results while reducing computational overhead. A key component of ITA-MDT is the Image-Timestep Adaptive Feature Aggregator (ITAFA), a dynamic feature aggregator that combines all of the features from the image encoder into a unified feature of the same size, guided by diffusion timestep and garment image complexity. This enables adaptive weighting of features, allowing the model to emphasize either global information or fine-grained details based on the requirements of the denoising stage. Additionally, the Salient Region Extractor (SRE) module is presented to identify complex region of the garment to provide high-resolution local information to the denoising model as an additional condition alongside the global information of the full garment image. This targeted conditioning strategy enhances detail preservation of fine details in highly salient garment regions, optimizing computational resources by avoiding unnecessarily processing entire garment image. Comparative evaluations confirms that ITA-MDT improves efficiency while maintaining strong performance, reaching state-of-the-art results in several metrics.
E-MD3C: Taming Masked Diffusion Transformers for Efficient Zero-Shot Object Customization
Feb 13, 2025We propose E-MD3C ($\underline{E}$fficient $\underline{M}$asked $\underline{D}$iffusion Transformer with Disentangled $\underline{C}$onditions and $\underline{C}$ompact $\underline{C}$ollector), a highly efficient framework for zero-shot object image customization. Unlike prior works reliant on resource-intensive Unet architectures, our approach employs lightweight masked diffusion transformers operating on latent patches, offering significantly improved computational efficiency. The framework integrates three core components: (1) an efficient masked diffusion transformer for processing autoencoder latents, (2) a disentangled condition design that ensures compactness while preserving background alignment and fine details, and (3) a learnable Conditions Collector that consolidates multiple inputs into a compact representation for efficient denoising and learning. E-MD3C outperforms the existing approach on the VITON-HD dataset across metrics such as PSNR, FID, SSIM, and LPIPS, demonstrating clear advantages in parameters, memory efficiency, and inference speed. With only $\frac{1}{4}$ of the parameters, our Transformer-based 468M model delivers $2.5\times$ faster inference and uses $\frac{2}{3}$ of the GPU memory compared to an 1720M Unet-based latent diffusion model.
Zero-Shot Dual-Path Integration Framework for Open-Vocabulary 3D Instance Segmentation
Aug 16, 2024


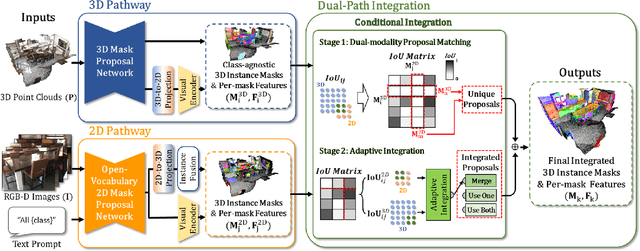
Open-vocabulary 3D instance segmentation transcends traditional closed-vocabulary methods by enabling the identification of both previously seen and unseen objects in real-world scenarios. It leverages a dual-modality approach, utilizing both 3D point clouds and 2D multi-view images to generate class-agnostic object mask proposals. Previous efforts predominantly focused on enhancing 3D mask proposal models; consequently, the information that could come from 2D association to 3D was not fully exploited. This bias towards 3D data, while effective for familiar indoor objects, limits the system's adaptability to new and varied object types, where 2D models offer greater utility. Addressing this gap, we introduce Zero-Shot Dual-Path Integration Framework that equally values the contributions of both 3D and 2D modalities. Our framework comprises three components: 3D pathway, 2D pathway, and Dual-Path Integration. 3D pathway generates spatially accurate class-agnostic mask proposals of common indoor objects from 3D point cloud data using a pre-trained 3D model, while 2D pathway utilizes pre-trained open-vocabulary instance segmentation model to identify a diverse array of object proposals from multi-view RGB-D images. In Dual-Path Integration, our Conditional Integration process, which operates in two stages, filters and merges the proposals from both pathways adaptively. This process harmonizes output proposals to enhance segmentation capabilities. Our framework, utilizing pre-trained models in a zero-shot manner, is model-agnostic and demonstrates superior performance on both seen and unseen data, as evidenced by comprehensive evaluations on the ScanNet200 and qualitative results on ARKitScenes datasets.
FlexiEdit: Frequency-Aware Latent Refinement for Enhanced Non-Rigid Editing
Jul 25, 2024

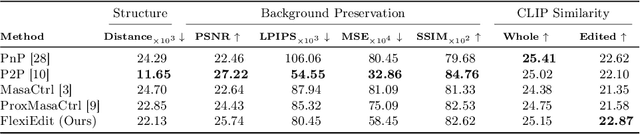

Current image editing methods primarily utilize DDIM Inversion, employing a two-branch diffusion approach to preserve the attributes and layout of the original image. However, these methods encounter challenges with non-rigid edits, which involve altering the image's layout or structure. Our comprehensive analysis reveals that the high-frequency components of DDIM latent, crucial for retaining the original image's key features and layout, significantly contribute to these limitations. Addressing this, we introduce FlexiEdit, which enhances fidelity to input text prompts by refining DDIM latent, by reducing high-frequency components in targeted editing areas. FlexiEdit comprises two key components: (1) Latent Refinement, which modifies DDIM latent to better accommodate layout adjustments, and (2) Edit Fidelity Enhancement via Re-inversion, aimed at ensuring the edits more accurately reflect the input text prompts. Our approach represents notable progress in image editing, particularly in performing complex non-rigid edits, showcasing its enhanced capability through comparative experiments.
Neutral Editing Framework for Diffusion-based Video Editing
Dec 10, 2023


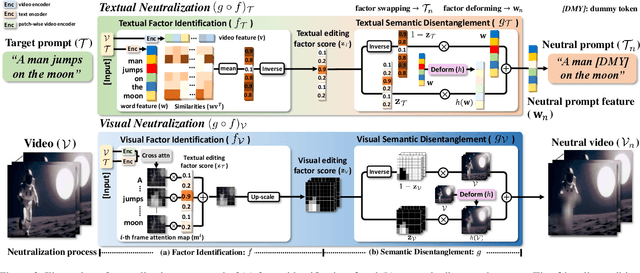
Text-conditioned image editing has succeeded in various types of editing based on a diffusion framework. Unfortunately, this success did not carry over to a video, which continues to be challenging. Existing video editing systems are still limited to rigid-type editing such as style transfer and object overlay. To this end, this paper proposes Neutral Editing (NeuEdit) framework to enable complex non-rigid editing by changing the motion of a person/object in a video, which has never been attempted before. NeuEdit introduces a concept of `neutralization' that enhances a tuning-editing process of diffusion-based editing systems in a model-agnostic manner by leveraging input video and text without any other auxiliary aids (e.g., visual masks, video captions). Extensive experiments on numerous videos demonstrate adaptability and effectiveness of the NeuEdit framework. The website of our work is available here: https://neuedit.github.io