 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pragmatic Persona: Discovering LLM Persona through Bridging Inference
Apr 27, 2026Large Language Models (LLMs) reveal inherent and distinctive personas through dialogue. However, most existing persona discovery approaches rely on surface-level lexical or stylistic cues, treating dialogue as a flat sequence of tokens and failing to capture the deeper discourse-level structures that sustain persona consistency. To address this limitation, we propose a novel analytical framework that interprets LLM dialogue through bridging inference -- implicit conceptual relations that connect utterances via shared world knowledge and discourse coherence. By modeling these relations as structured knowledge graphs, our approach captures latent semantic links that govern how LLMs organize meaning across turns, enabling persona discovery at the level of discourse coherence rather than surface realizations. Experimental results across multiple reasoning backbones and target LLMs, ranging from small-scale models to 80B-parameter systems, demonstrate that bridging-inference graphs yield significantly stronger semantic coherence and more stable persona identification than frequency or style-based baselines. These results show that persona traits are consistently encoded in the structural organization of discourse rather than isolated lexical patterns. This work presents a systematic framework for probing, extracting, and visualizing latent LLM personas through the lens of Cognitive Discourse Theory, bridging computational linguistics, cognitive semantics, and persona reasoning in large language models. Codes are available at https://github.com/JiSoo-Yang/Persona_Bridging.git
QEVA: A Reference-Free Evaluation Metric for Narrative Video Summarization with Multimodal Question Answering
Apr 27, 2026Video-to-text summarization remains underexplored in terms of comprehensive evaluation methods. Traditional n-gram overlap-based metrics and recent large language model (LLM)-based approaches depend heavily on human-written reference summaries, limiting their practicality and sensitivity to nuanced semantic aspects. In this paper, we propose QEVA, a reference-free metric evaluating candidate summaries directly against source videos through multimodal question answering. QEVA assesses summaries along three clear dimensions: Coverage, Factuality, and Chronology. We also introduce MLVU(VS)-Eval, a new annotated benchmark derived from the MLVU dataset, comprising 800 summaries generated from 200 videos using state-of-the-art video-language multimodal models. This dataset establishes a transparent and consistent framework for evaluation. Experimental results demonstrate that QEVA shows higher correlation with human judgments compared to existing approaches, as measured by Kendall's $τ_b$, $τ_c$, and Spearman's $ρ$. We hope that our benchmark and metric will facilitate meaningful progress in video-to-text summarization research and provide valuable insights for the development of future evaluation methods.
See More, Store Less: Memory-Efficient Resolution for Video Moment Retrieval
Jan 14, 2026Recent advances in Multimodal Large Language Models (MLLMs) have improved image recognition and reasoning, but video-related tasks remain challenging due to memory constraints from dense frame processing. Existing Video Moment Retrieval (VMR) methodologies rely on sparse frame sampling, risking potential information loss, especially in lengthy videos. We propose SMORE (See MORE, store less), a framework that enhances memory efficiency while maintaining high information resolution. SMORE (1) uses query-guided captions to encode semantics aligned with user intent, (2) applies query-aware importance modulation to highlight relevant segments, and (3) adaptively compresses frames to preserve key content while reducing redundancy. This enables efficient video understanding without exceeding memory budgets. Experimental validation reveals that SMORE achieves state-of-the-art performance on QVHighlights, Charades-STA, and ActivityNet-Captions benchmarks.
Language-Grounded Multi-Domain Image Translation via Semantic Difference Guidance
Jan 12, 2026Multi-domain image-to-image translation re quires grounding semantic differences ex pressed in natural language prompts into corresponding visual transformations, while preserving unrelated structural and seman tic content. Existing methods struggle to maintain structural integrity and provide fine grained, attribute-specific control, especially when multiple domains are involved. We propose LACE (Language-grounded Attribute Controllable Translation), built on two compo nents: (1) a GLIP-Adapter that fuses global semantics with local structural features to pre serve consistency, and (2) a Multi-Domain Control Guidance mechanism that explicitly grounds the semantic delta between source and target prompts into per-attribute translation vec tors, aligning linguistic semantics with domain level visual changes. Together, these modules enable compositional multi-domain control with independent strength modulation for each attribute. Experiments on CelebA(Dialog) and BDD100K demonstrate that LACE achieves high visual fidelity, structural preservation, and interpretable domain-specific control, surpass ing prior baselines. This positions LACE as a cross-modal content generation framework bridging language semantics and controllable visual translation.
Visual Funnel: Resolving Contextual Blindness in Multimodal Large Language Models
Dec 11, 2025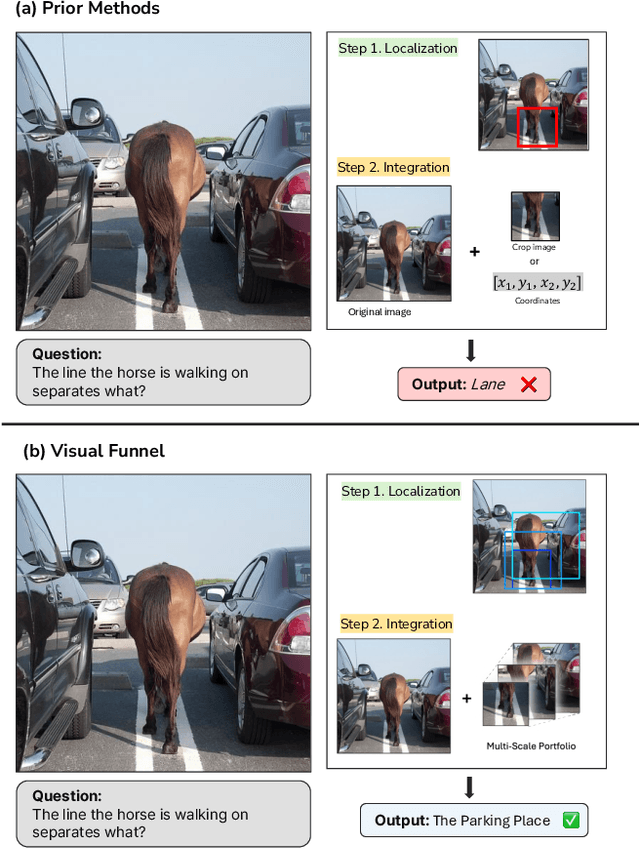
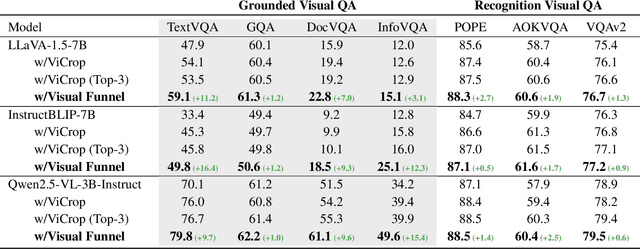
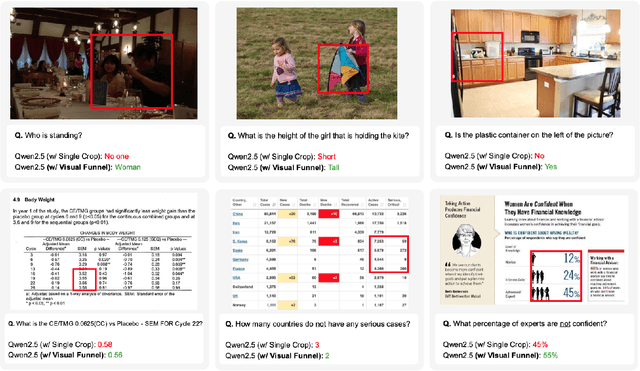
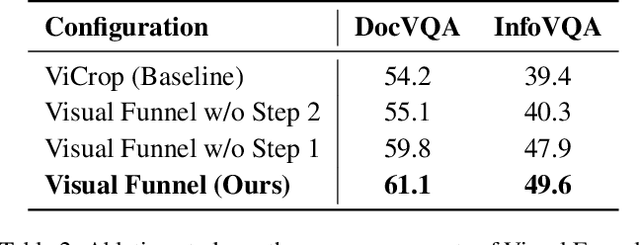
Multimodal Large Language Models (MLLMs) demonstrate impressive reasoning capabilities, but often fail to perceive fine-grained visual details, limiting their applicability in precision-demanding tasks. While methods that crop salient regions of an image offer a partial solution, we identify a critical limitation they introduce: "Contextual Blindness". This failure occurs due to structural disconnect between high-fidelity details (from the crop) and the broader global context (from the original image), even when all necessary visual information is present. We argue that this limitation stems not from a lack of information 'Quantity', but from a lack of 'Structural Diversity' in the model's input. To resolve this, we propose Visual Funnel, a training-free, two-step approach. Visual Funnel first performs Contextual Anchoring to identify the region of interest in a single forward pass. It then constructs an Entropy-Scaled Portfolio that preserves the hierarchical context - ranging from focal detail to broader surroundings - by dynamically determining crop sizes based on attention entropy and refining crop centers. Through extensive experiments, we demonstrate that Visual Funnel significantly outperforms naive single-crop and unstructured multi-crop baselines. Our results further validate that simply adding more unstructured crops provides limited or even detrimental benefits, confirming that the hierarchical structure of our portfolio is key to resolving Contextual Blindness.
Synergy-CLIP: Extending CLIP with Multi-modal Integration for Robust Representation Learning
Apr 30, 2025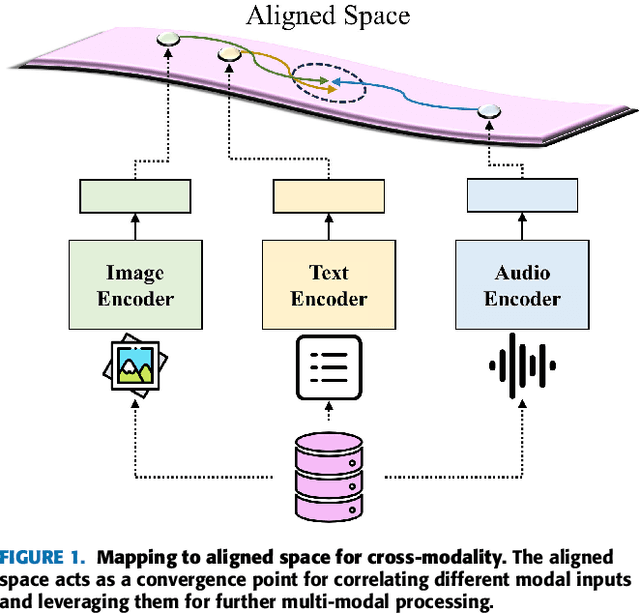
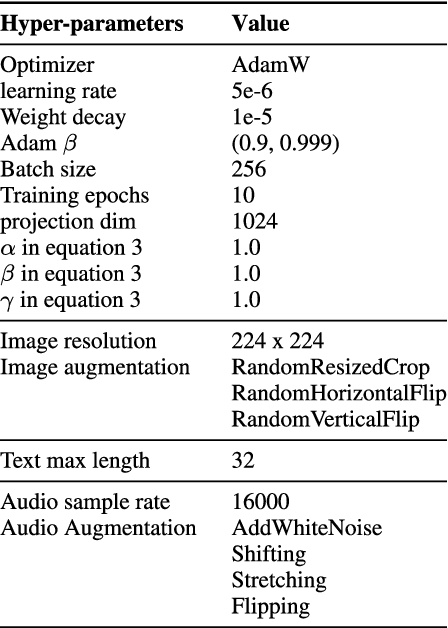

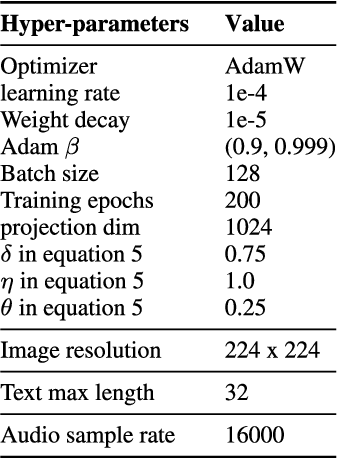
Multi-modal representation learning has become a pivotal area in artificial intelligence, enabling the integration of diverse modalities such as vision, text, and audio to solve complex problems. However, existing approaches predominantly focus on bimodal interactions, such as image-text pairs, which limits their ability to fully exploit the richness of multi-modal data. Furthermore, the integration of modalities in equal-scale environments remains underexplored due to the challenges of constructing large-scale, balanced datasets. In this study, we propose Synergy-CLIP, a novel framework that extends the contrastive language-image pre-training (CLIP) architecture to enhance multi-modal representation learning by integrating visual, textual, and audio modalities. Unlike existing methods that focus on adapting individual modalities to vanilla-CLIP, Synergy-CLIP aligns and captures latent information across three modalities equally. To address the high cost of constructing large-scale multi-modal datasets, we introduce VGG-sound+, a triple-modal dataset designed to provide equal-scale representation of visual, textual, and audio data. Synergy-CLIP is validated on various downstream tasks, including zero-shot classification, where it outperforms existing baselines. Additionally, we introduce a missing modality reconstruction task, demonstrating Synergy-CLIP's ability to extract synergy among modalities in realistic application scenarios. These contributions provide a robust foundation for advancing multi-modal representation learning and exploring new research directions.
BioBridge: Unified Bio-Embedding with Bridging Modality in Code-Switched EMR
Dec 16, 2024

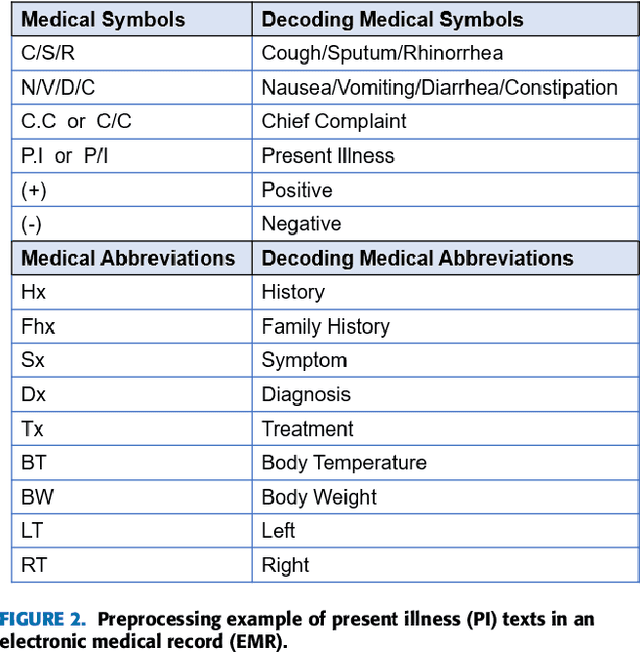
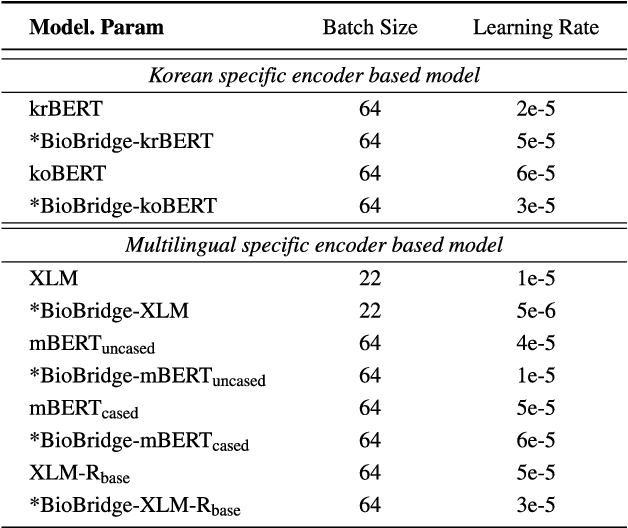
Pediatric Emergency Department (PED) overcrowding presents a significant global challenge, prompting the need for efficient solutions. This paper introduces the BioBridge framework, a novel approach that applies Natural Language Processing (NLP) to Electronic Medical Records (EMRs) in written free-text form to enhance decision-making in PED. In non-English speaking countries, such as South Korea, EMR data is often written in a Code-Switching (CS) format that mixes the native language with English, with most code-switched English words having clinical significance. The BioBridge framework consists of two core modules: "bridging modality in context" and "unified bio-embedding." The "bridging modality in context" module improves the contextual understanding of bilingual and code-switched EMRs. In the "unified bio-embedding" module, the knowledge of the model trained in the medical domain is injected into the encoder-based model to bridge the gap between the medical and general domains. Experimental results demonstrate that the proposed BioBridge significantly performance traditional machine learning and pre-trained encoder-based models on several metrics, including F1 score, area under the receiver operating characteristic curve (AUROC), area under the precision-recall curve (AUPRC), and Brier score. Specifically, BioBridge-XLM achieved enhancements of 0.85% in F1 score, 0.75% in AUROC, and 0.76% in AUPRC, along with a notable 3.04% decrease in the Brier score, demonstrating marked improvements in accuracy, reliability, and prediction calibration over the baseline XLM model. The source code will be made publicly available.
* Accepted at IEEE Access 2024
Zero-Shot Dual-Path Integration Framework for Open-Vocabulary 3D Instance Segmentation
Aug 16, 2024


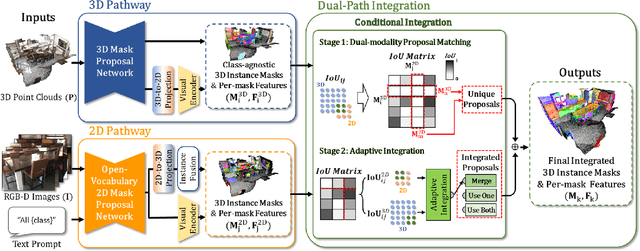
Open-vocabulary 3D instance segmentation transcends traditional closed-vocabulary methods by enabling the identification of both previously seen and unseen objects in real-world scenarios. It leverages a dual-modality approach, utilizing both 3D point clouds and 2D multi-view images to generate class-agnostic object mask proposals. Previous efforts predominantly focused on enhancing 3D mask proposal models; consequently, the information that could come from 2D association to 3D was not fully exploited. This bias towards 3D data, while effective for familiar indoor objects, limits the system's adaptability to new and varied object types, where 2D models offer greater utility. Addressing this gap, we introduce Zero-Shot Dual-Path Integration Framework that equally values the contributions of both 3D and 2D modalities. Our framework comprises three components: 3D pathway, 2D pathway, and Dual-Path Integration. 3D pathway generates spatially accurate class-agnostic mask proposals of common indoor objects from 3D point cloud data using a pre-trained 3D model, while 2D pathway utilizes pre-trained open-vocabulary instance segmentation model to identify a diverse array of object proposals from multi-view RGB-D images. In Dual-Path Integration, our Conditional Integration process, which operates in two stages, filters and merges the proposals from both pathways adaptively. This process harmonizes output proposals to enhance segmentation capabilities. Our framework, utilizing pre-trained models in a zero-shot manner, is model-agnostic and demonstrates superior performance on both seen and unseen data, as evidenced by comprehensive evaluations on the ScanNet200 and qualitative results on ARKitScenes datasets.
HEAR: Hearing Enhanced Audio Response for Video-grounded Dialogue
Dec 15, 2023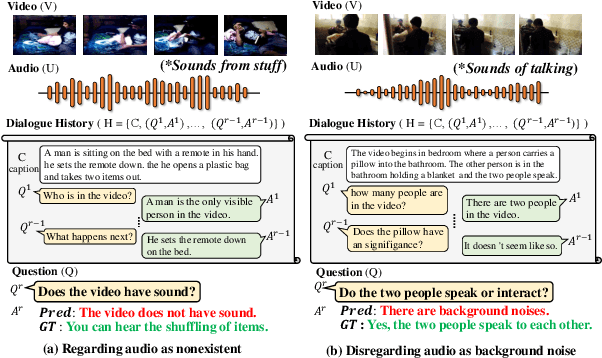
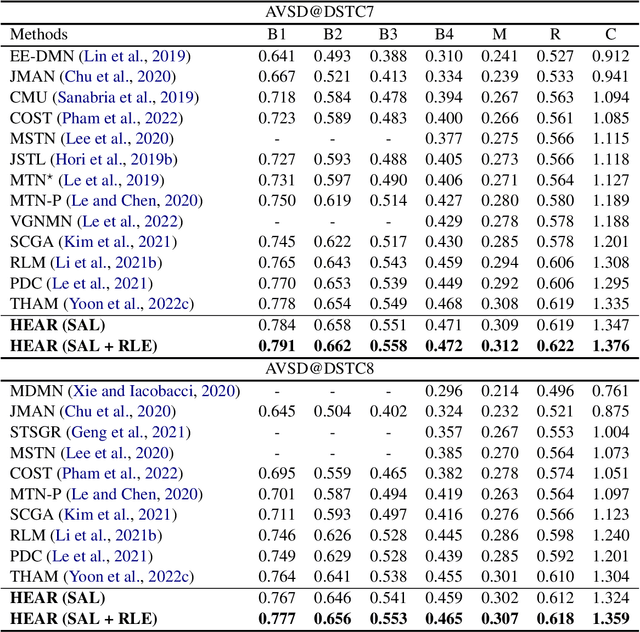
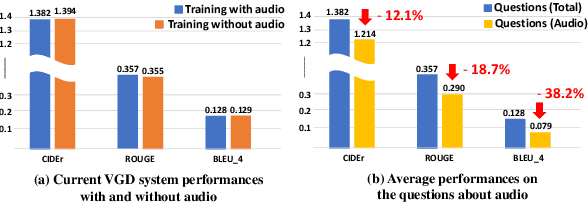

Video-grounded Dialogue (VGD) aims to answer questions regarding a given multi-modal input comprising video, audio, and dialogue history. Although there have been numerous efforts in developing VGD systems to improve the quality of their responses, existing systems are competent only to incorporate the information in the video and text and tend to struggle in extracting the necessary information from the audio when generating appropriate responses to the question. The VGD system seems to be deaf, and thus, we coin this symptom of current systems' ignoring audio data as a deaf response. To overcome the deaf response problem, Hearing Enhanced Audio Response (HEAR) framework is proposed to perform sensible listening by selectively attending to audio whenever the question requires it. The HEAR framework enhances the accuracy and audibility of VGD systems in a model-agnostic manner. HEAR is validated on VGD datasets (i.e., AVSD@DSTC7 and AVSD@DSTC8) and shows effectiveness with various VGD systems.
Information-Theoretic Text Hallucination Reduction for Video-grounded Dialogue
Dec 12, 2022
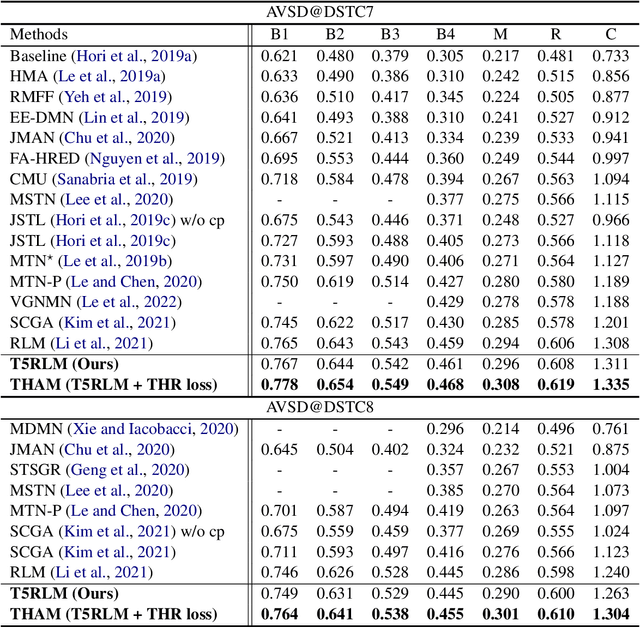


Video-grounded Dialogue (VGD) aims to decode an answer sentence to a question regarding a given video and dialogue context. Despite the recent success of multi-modal reasoning to generate answer sentences, existing dialogue systems still suffer from a text hallucination problem, which denotes indiscriminate text-copying from input texts without an understanding of the question. This is due to learning spurious correlations from the fact that answer sentences in the dataset usually include the words of input texts, thus the VGD system excessively relies on copying words from input texts by hoping those words to overlap with ground-truth texts. Hence, we design Text Hallucination Mitigating (THAM) framework, which incorporates Text Hallucination Regularization (THR) loss derived from the proposed information-theoretic text hallucination measurement approach. Applying THAM with current dialogue systems validates the effectiveness on VGD benchmarks (i.e., AVSD@DSTC7 and AVSD@DSTC8) and shows enhanced interpretability.