 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergy-CLIP: Extending CLIP with Multi-modal Integration for Robust Representation Learning
Apr 30, 2025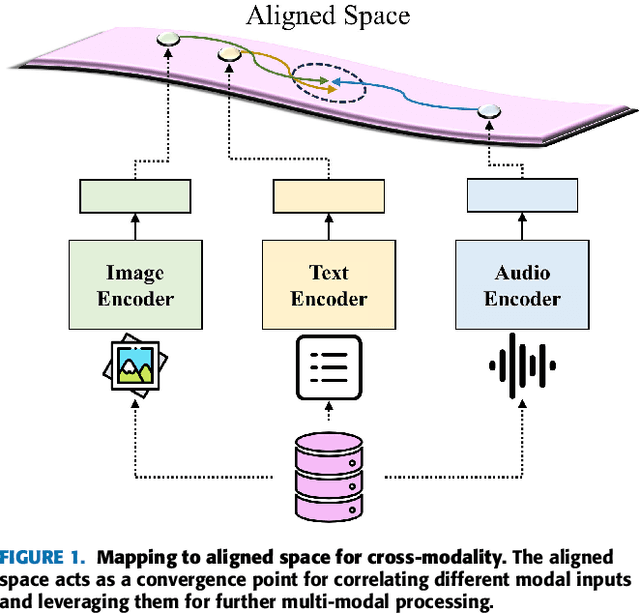
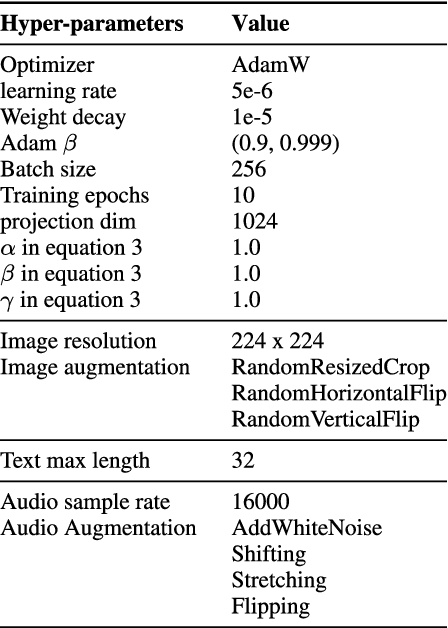

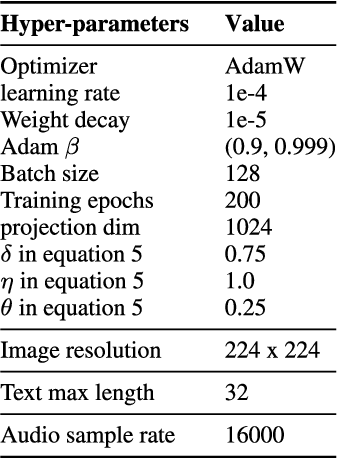
Multi-modal representation learning has become a pivotal area in artificial intelligence, enabling the integration of diverse modalities such as vision, text, and audio to solve complex problems. However, existing approaches predominantly focus on bimodal interactions, such as image-text pairs, which limits their ability to fully exploit the richness of multi-modal data. Furthermore, the integration of modalities in equal-scale environments remains underexplored due to the challenges of constructing large-scale, balanced datasets. In this study, we propose Synergy-CLIP, a novel framework that extends the contrastive language-image pre-training (CLIP) architecture to enhance multi-modal representation learning by integrating visual, textual, and audio modalities. Unlike existing methods that focus on adapting individual modalities to vanilla-CLIP, Synergy-CLIP aligns and captures latent information across three modalities equally. To address the high cost of constructing large-scale multi-modal datasets, we introduce VGG-sound+, a triple-modal dataset designed to provide equal-scale representation of visual, textual, and audio data. Synergy-CLIP is validated on various downstream tasks, including zero-shot classification, where it outperforms existing baselines. Additionally, we introduce a missing modality reconstruction task, demonstrating Synergy-CLIP's ability to extract synergy among modalities in realistic application scenarios. These contributions provide a robust foundation for advancing multi-modal representation learning and exploring new research directions.
KoCoSa: Korean Context-aware Sarcasm Detection Dataset
Feb 22, 2024Sarcasm is a way of verbal irony where someone says the opposite of what they mean, often to ridicule a person, situation, or idea. It is often difficult to detect sarcasm in the dialogue since detecting sarcasm should reflect the context (i.e., dialogue history). In this paper, we introduce a new dataset for the Korean dialogue sarcasm detection task, KoCoSa (Korean Context-aware Sarcasm Detection Dataset), which consists of 12.8K daily Korean dialogues and the labels for this task on the last response. To build the dataset, we propose an efficient sarcasm detection dataset generation pipeline: 1) generating new sarcastic dialogues from source dialogues with large language models, 2) automatic and manual filtering of abnormal and toxic dialogues, and 3) human annotation for the sarcasm detection task. We also provide a simple but effective baseline for the Korean sarcasm detection task trained on our dataset. Experimental results on the dataset show that our baseline system outperforms strong baselines like large language models, such as GPT-3.5, in the Korean sarcasm detection task. We show that the sarcasm detection task relies deeply on the existence of sufficient context. We will release the dataset at https://anonymous.4open.science/r/KoCoSa-2372.