 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fixed Rounds: Data-Free Early Stopping for Practical Federated Learning
Jan 30, 2026Federated Learning (FL) facilitates decentralized collaborative learning without transmitting raw data. However, reliance on fixed global rounds or validation data for hyperparameter tuning hinders practical deployment by incurring high computational costs and privacy risks. To address this, we propose a data-free early stopping framework that determines the optimal stopping point by monitoring the task vector's growth rate using solely server-side parameters. The numerical results on skin lesion/blood cell classification demonstrate that our approach is comparable to validation-based early stopping across various state-of-the-art FL methods. In particular, the proposed framework spends an average of 47/20 (skin lesion/blood cell) rounds to achieve over 12.5%/10.3% higher performance than early stopping based on validation data. To the best of our knowledge, this is the first work to propose an early stopping framework for FL methods without using any validation data.
When to Stop Federated Learning: Zero-Shot Generation of Synthetic Validation Data with Generative AI for Early Stopping
Nov 14, 2025Federated Learning (FL) enables collaborative model training across decentralized devices while preserving data privacy. However, FL methods typically run for a predefined number of global rounds, often leading to unnecessary computation when optimal performance is reached earlier. In addition, training may continue even when the model fails to achieve meaningful performance. To address this inefficiency, we introduce a zero-shot synthetic validation framework that leverages generative AI to monitor model performance and determine early stopping points. Our approach adaptively stops training near the optimal round, thereby conserving computational resources and enabling rapid hyperparameter adjustments. Numerical results on multi-label chest X-ray classification demonstrate that our method reduces training rounds by up to 74% while maintaining accuracy within 1% of the optimal.
Forecasting-Based Biomedical Time-series Data Synthesis for Open Data and Robust AI
Oct 06, 2025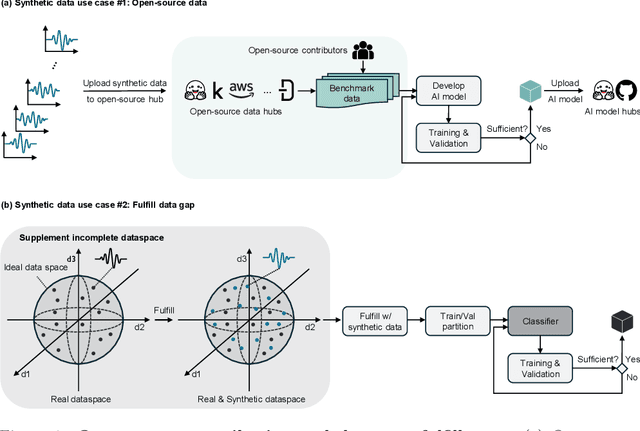
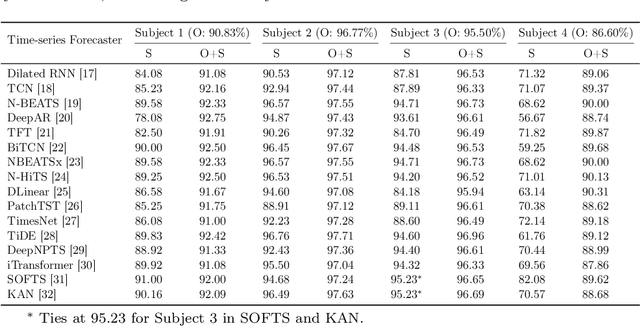
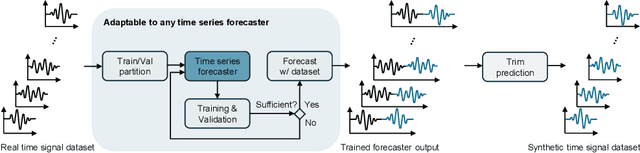
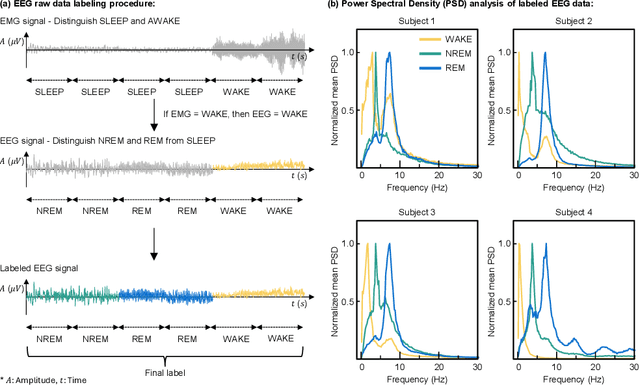
The limited data availability due to strict privacy regulations and significant resource demands severely constrains biomedical time-series AI development, which creates a critical gap between data requirements and accessibility. Synthetic data generation presents a promising solution by producing artificial datasets that maintain the statistical properties of real biomedical time-series data without compromising patient confidentiality. We propose a framework for synthetic biomedical time-series data generation based on advanced forecasting models that accurately replicates complex electrophysiological signals such as EEG and EMG with high fidelity. These synthetic datasets preserve essential temporal and spectral properties of real data, which enables robust analysis while effectively addressing data scarcity and privacy challenges. Our evaluations across multiple subjects demonstrate that the generated synthetic data can serve as an effective substitute for real data and also significantly boost AI model performance. The approach maintains critical biomedical features while provides high scalability for various applications and integrates seamlessly into open-source repositories, substantially expanding resources for AI-driven biomedical research.
Improving Generalizability of Kolmogorov-Arnold Networks via Error-Correcting Output Codes
May 09, 2025



Kolmogorov-Arnold Networks (KAN) offer universal function approximation using univariate spline compositions without nonlinear activations. In this work, we integrate Error-Correcting Output Codes (ECOC) into the KAN framework to transform multi-class classification into multiple binary tasks, improving robustness via Hamming-distance decoding. Our proposed KAN with ECOC method outperforms vanilla KAN on a challenging blood cell classification dataset, achieving higher accuracy under diverse hyperparameter settings. Ablation studies further confirm that ECOC consistently enhances performance across FastKAN and FasterKAN variants. These results demonstrate that ECOC integration significantly boosts KAN generalizability in critical healthcare AI applications. To the best of our knowledge, this is the first integration of ECOC with KAN for enhancing multi-class medical image classification performance.
A Unified Benchmark of Federated Learning with Kolmogorov-Arnold Networks for Medical Imaging
Apr 28, 2025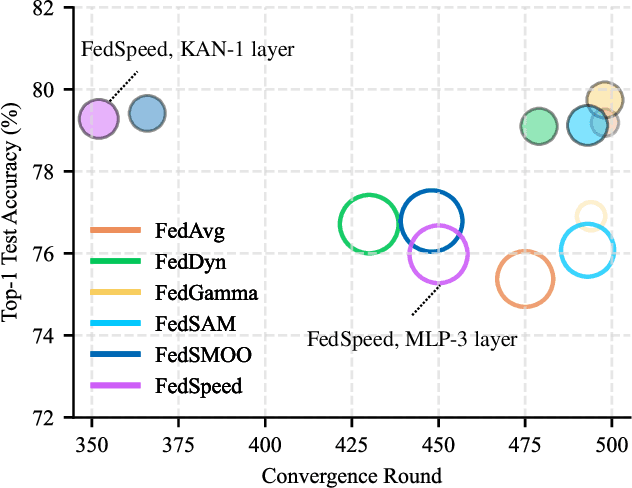
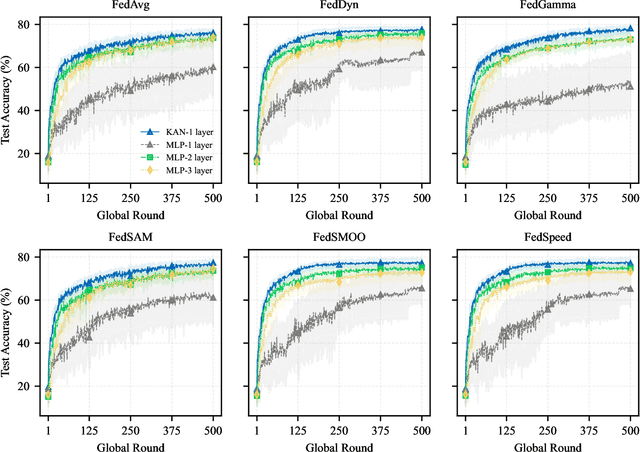
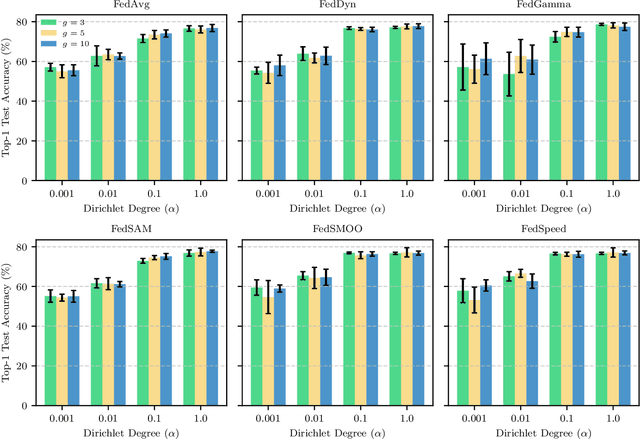
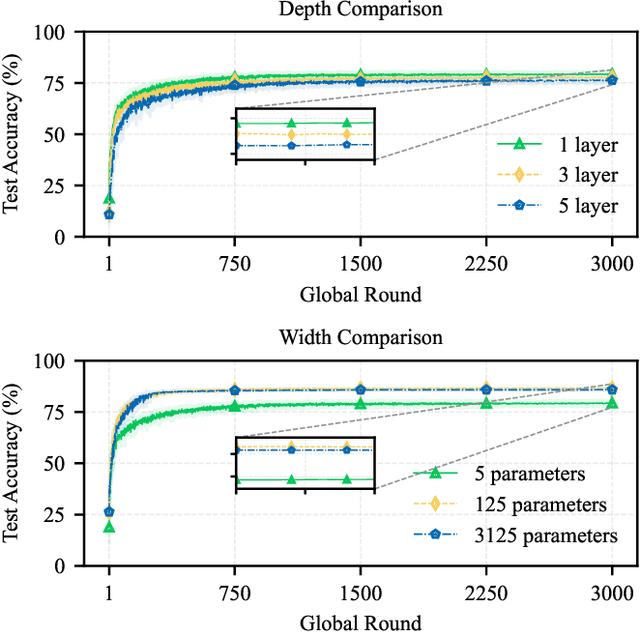
Federated Learning (FL) enables model training across decentralized devices without sharing raw data, thereby preserving privacy in sensitive domains like healthcare. In this paper, we evaluate Kolmogorov-Arnold Networks (KAN) architectures against traditional MLP across six state-of-the-art FL algorithms on a blood cell classification dataset. Notably, our experiments demonstrate that KAN can effectively replace MLP in federated environments, achieving superior performance with simpler architectures. Furthermore, we analyze the impact of key hyperparameters-grid size and network architecture-on KAN performance under varying degrees of Non-IID data distribution. Additionally, our ablation studies reveal that optimizing KAN width while maintaining minimal depth yields the best performance in federated settings. As a result, these findings establish KAN as a promising alternative for privacy-preserving medical imaging applications in distributed healthcare. To the best of our knowledge, this is the first comprehensive benchmark of KAN in FL settings for medical imaging task.
Revisit the Stability of Vanilla Federated Learning Under Diverse Conditions
Feb 27, 2025Federated Learning (FL) is a distributed machine learning paradigm enabling collaborative model training across decentralized clients while preserving data privacy. In this paper, we revisit the stability of the vanilla FedAvg algorithm under diverse conditions. Despite its conceptual simplicity, FedAvg exhibits remarkably stable performance compared to more advanced FL techniques. Our experiments assess the performance of various FL methods on blood cell and skin lesion classification tasks using Vision Transformer (ViT). Additionally, we evaluate the impact of different representative classification models and analyze sensitivity to hyperparameter variations. The results consistently demonstrate that, regardless of dataset, classification model employed, or hyperparameter settings, FedAvg maintains robust performance. Given its stability, robust performance without the need for extensive hyperparameter tuning, FedAvg is a safe and efficient choice for FL deployments in resource-constrained hospitals handling medical data. These findings underscore the enduring value of the vanilla FedAvg approach as a trusted baseline for clinical practice.
Exploring Potential Prompt Injection Attacks in Federated Military LLMs and Their Mitigation
Jan 30, 2025Federated Learning (FL) is increasingly being adopted in military collaborations to develop Large Language Models (LLMs) while preserving data sovereignty. However, prompt injection attacks-malicious manipulations of input prompts-pose new threats that may undermine operational security, disrupt decision-making, and erode trust among allies. This perspective paper highlights four potential vulnerabilities in federated military LLMs: secret data leakage, free-rider exploitation, system disruption, and misinformation spread. To address these potential risks, we propose a human-AI collaborative framework that introduces both technical and policy countermeasures. On the technical side, our framework uses red/blue team wargaming and quality assurance to detect and mitigate adversarial behaviors of shared LLM weights. On the policy side, it promotes joint AI-human policy development and verification of security protocols. Our findings will guide future research and emphasize proactive strategies for emerging military contexts.
Embedding Byzantine Fault Tolerance into Federated Learning via Virtual Data-Driven Consistency Scoring Plugin
Nov 15, 2024Given sufficient data from multiple edge devices, federated learning (FL) enables training a shared model without transmitting private data to a central server. However, FL is generally vulnerable to Byzantine attacks from compromised edge devices, which can significantly degrade the model performance. In this paper, we propose a intuitive plugin that can be integrated into existing FL techniques to achieve Byzantine-Resilience. Key idea is to generate virtual data samples and evaluate model consistency scores across local updates to effectively filter out compromised edge devices. By utilizing this scoring mechanism before the aggregation phase, the proposed plugin enables existing FL techniques to become robust against Byzantine attacks while maintaining their original benefits. Numerical results on medical image classification task validate that plugging the proposed approach into representative FL algorithms, effectively achieves Byzantine resilience. Furthermore, the proposed plugin maintains the original convergence properties of the base FL algorithms when no Byzantine attacks are present.
Generative AI-Powered Plugin for Robust Federated Learning in Heterogeneous IoT Networks
Oct 31, 2024



Federated learning enables edge devices to collaboratively train a global model while maintaining data privacy by keeping data localized. However, the Non-IID nature of data distribution across devices often hinders model convergence and reduces performance. In this paper, we propose a novel plugin for federated optimization techniques that approximates Non-IID data distributions to IID through generative AI-enhanced data augmentation and balanced sampling strategy. Key idea is to synthesize additional data for underrepresented classes on each edge device, leveraging generative AI to create a more balanced dataset across the FL network. Additionally, a balanced sampling approach at the central server selectively includes only the most IID-like devices, accelerating convergence while maximizing the global model's performance. Experimental results validate that our approach significantly improves convergence speed and robustness against data imbalance, establishing a flexible, privacy-preserving FL plugin that is applicable even in data-scarce environments.
ROK Defense M&S in the Age of Hyperscale AI: Concepts, Challenges, and Future Directions
Oct 01, 2024



Integrating hyperscale AI into national defense modeling and simulation (M&S) is crucial for enhancing strategic and operational capabilities. We explore how hyperscale AI can revolutionize defense M\&S by providing unprecedented accuracy, speed, and the ability to simulate complex scenarios. Countries such as the United States and China are at the forefront of adopting these technologies and are experiencing varying degrees of success. Maximizing the potential of hyperscale AI necessitates addressing critical challenges, such as closed networks, long-tail data, complex decision-making, and a shortage of experts. Future directions emphasize the adoption of domestic foundation models, the investment in various GPUs / NPUs, the utilization of big tech services, and the use of open source software. These initiatives will enhance national security, maintain competitive advantages, and promote broader technological and economic progress. With this blueprint, the Republic of Korea can strengthen its defense capabilities and stay ahead of the emerging threats of modern warfare.