 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit the Stability of Vanilla Federated Learning Under Diverse Conditions
Feb 27, 2025Federated Learning (FL) is a distributed machine learning paradigm enabling collaborative model training across decentralized clients while preserving data privacy. In this paper, we revisit the stability of the vanilla FedAvg algorithm under diverse conditions. Despite its conceptual simplicity, FedAvg exhibits remarkably stable performance compared to more advanced FL techniques. Our experiments assess the performance of various FL methods on blood cell and skin lesion classification tasks using Vision Transformer (ViT). Additionally, we evaluate the impact of different representative classification models and analyze sensitivity to hyperparameter variations. The results consistently demonstrate that, regardless of dataset, classification model employed, or hyperparameter settings, FedAvg maintains robust performance. Given its stability, robust performance without the need for extensive hyperparameter tuning, FedAvg is a safe and efficient choice for FL deployments in resource-constrained hospitals handling medical data. These findings underscore the enduring value of the vanilla FedAvg approach as a trusted baseline for clinical practice.
Training Multiscale-CNN for Large Microscopy Image Classification in One Hour
Oct 03, 2019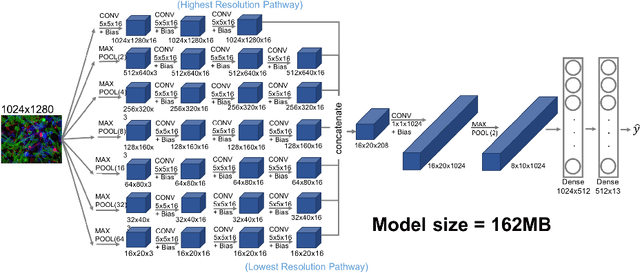

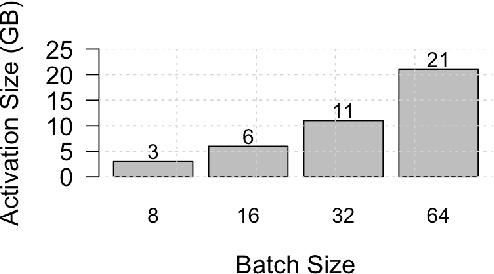
Existing approaches to train neural networks that use large images require to either crop or down-sample data during pre-processing, use small batch sizes, or split the model across devices mainly due to the prohibitively limited memory capacity available on GPUs and emerging accelerators. These techniques often lead to longer time to convergence or time to train (TTT), and in some cases, lower model accuracy. CPUs, on the other hand, can leverage significant amounts of memory. While much work has been done on parallelizing neural network training on multiple CPUs, little attention has been given to tune neural network training with large images on CPUs. In this work, we train a multi-scale convolutional neural network (M-CNN) to classify large biomedical images for high content screening in one hour. The ability to leverage large memory capacity on CPUs enables us to scale to larger batch sizes without having to crop or down-sample the input images. In conjunction with large batch sizes, we find a generalized methodology of linearly scaling of learning rate and train M-CNN to state-of-the-art (SOTA) accuracy of 99% within one hour. We achieve fast time to convergence using 128 two socket Intel Xeon 6148 processor nodes with 192GB DDR4 memory connected with 100Gbps Intel Omnipath architecture.
* 15 pages, 10 figures
Efficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model
Jun 07, 2019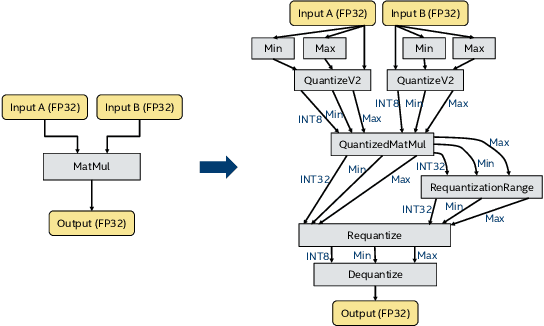
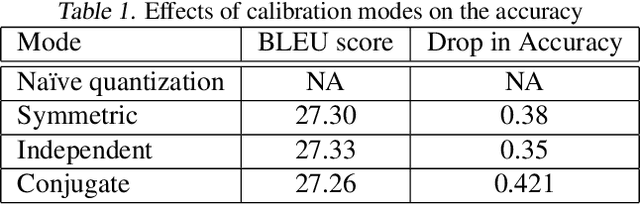
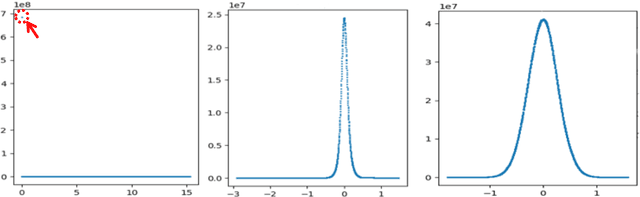
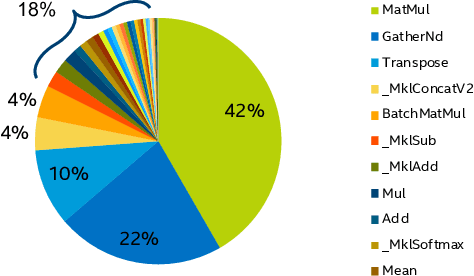
In this work, we quantize a trained Transformer machine language translation model leveraging INT8/VNNI instructions in the latest Intel$^\circledR$ Xeon$^\circledR$ Cascade Lake processors to improve inference performance while maintaining less than 0.5$\%$ drop in accuracy. To the best of our knowledge, this is the first attempt in the industry to quantize the Transformer model. This has high impact as it clearly demonstrates the various complexities of quantizing the language translation model. We present novel quantization techniques directly in TensorFlow to opportunistically replace 32-bit floating point (FP32) computations with 8-bit integers (INT8) and transform the FP32 computational graph. We also present a bin-packing parallel batching technique to maximize CPU utilization. Overall, our optimizations with INT8/VNNI deliver 1.5X improvement over the best FP32 performance. Furthermore, it reveals the opportunities and challenges to boost performance of quantized deep learning inference and establishes best practices to run inference with high efficiency on Intel CPUs.