 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Stabilization for AI Training Datacenters
Aug 21, 2025Large Artificial Intelligence (AI) training workloads spanning several tens of thousands of GPUs present unique power management challenges. These arise due to the high variability in power consumption during the training. Given the synchronous nature of these jobs, during every iteration there is a computation-heavy phase, where each GPU works on the local data, and a communication-heavy phase where all the GPUs synchronize on the data. Because compute-heavy phases require much more power than communication phases, large power swings occur. The amplitude of these power swings is ever increasing with the increase in the size of training jobs. An even bigger challenge arises from the frequency spectrum of these power swings which, if harmonized with critical frequencies of utilities, can cause physical damage to the power grid infrastructure. Therefore, to continue scaling AI training workloads safely, we need to stabilize the power of such workloads. This paper introduces the challenge with production data and explores innovative solutions across the stack: software, GPU hardware, and datacenter infrastructure. We present the pros and cons of each of these approaches and finally present a multi-pronged approach to solving the challenge. The proposed solutions are rigorously tested using a combination of real hardware and Microsoft's in-house cloud power simulator, providing critical insights into the efficacy of these interventions under real-world conditions.
Training Multiscale-CNN for Large Microscopy Image Classification in One Hour
Oct 03, 2019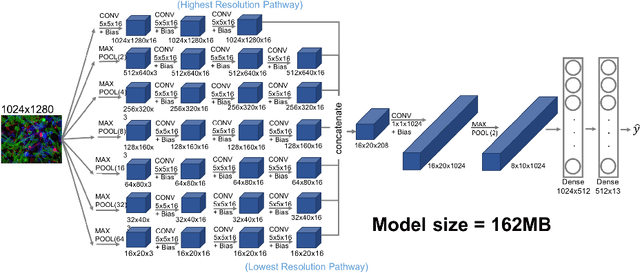

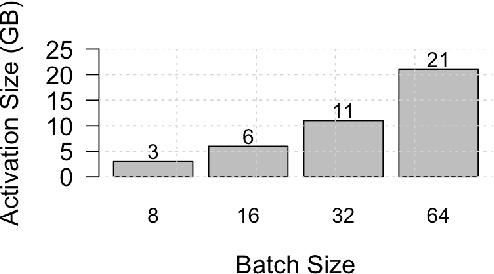
Existing approaches to train neural networks that use large images require to either crop or down-sample data during pre-processing, use small batch sizes, or split the model across devices mainly due to the prohibitively limited memory capacity available on GPUs and emerging accelerators. These techniques often lead to longer time to convergence or time to train (TTT), and in some cases, lower model accuracy. CPUs, on the other hand, can leverage significant amounts of memory. While much work has been done on parallelizing neural network training on multiple CPUs, little attention has been given to tune neural network training with large images on CPUs. In this work, we train a multi-scale convolutional neural network (M-CNN) to classify large biomedical images for high content screening in one hour. The ability to leverage large memory capacity on CPUs enables us to scale to larger batch sizes without having to crop or down-sample the input images. In conjunction with large batch sizes, we find a generalized methodology of linearly scaling of learning rate and train M-CNN to state-of-the-art (SOTA) accuracy of 99% within one hour. We achieve fast time to convergence using 128 two socket Intel Xeon 6148 processor nodes with 192GB DDR4 memory connected with 100Gbps Intel Omnipath architecture.
* 15 pages, 10 figures
Efficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model
Jun 07, 2019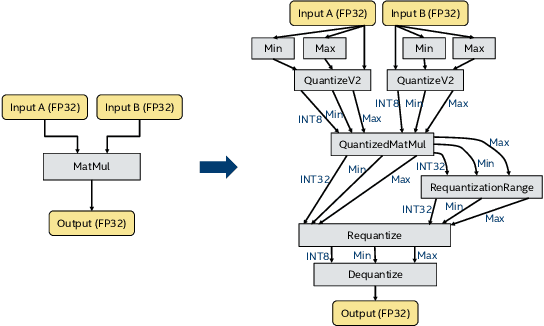
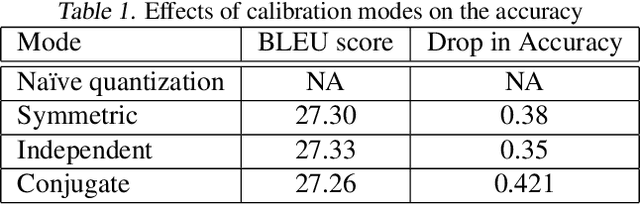
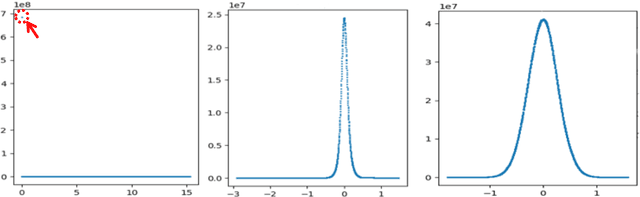
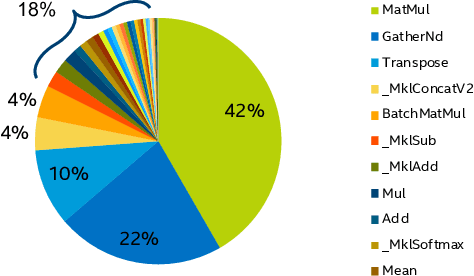
In this work, we quantize a trained Transformer machine language translation model leveraging INT8/VNNI instructions in the latest Intel$^\circledR$ Xeon$^\circledR$ Cascade Lake processors to improve inference performance while maintaining less than 0.5$\%$ drop in accuracy. To the best of our knowledge, this is the first attempt in the industry to quantize the Transformer model. This has high impact as it clearly demonstrates the various complexities of quantizing the language translation model. We present novel quantization techniques directly in TensorFlow to opportunistically replace 32-bit floating point (FP32) computations with 8-bit integers (INT8) and transform the FP32 computational graph. We also present a bin-packing parallel batching technique to maximize CPU utilization. Overall, our optimizations with INT8/VNNI deliver 1.5X improvement over the best FP32 performance. Furthermore, it reveals the opportunities and challenges to boost performance of quantized deep learning inference and establishes best practices to run inference with high efficiency on Intel CPUs.