 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model
Paper and Code
Jun 07, 2019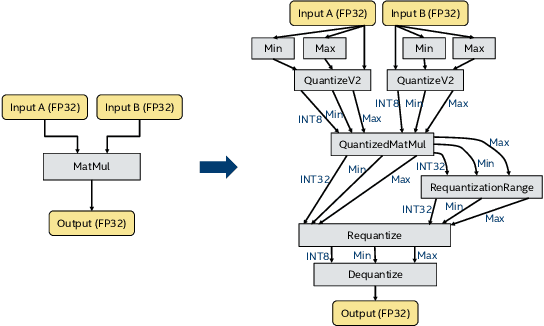
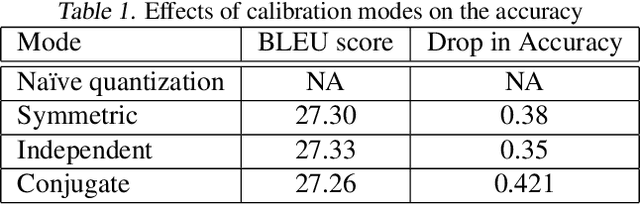
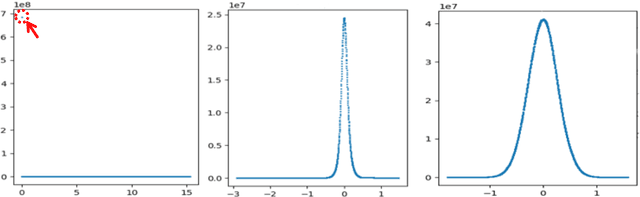
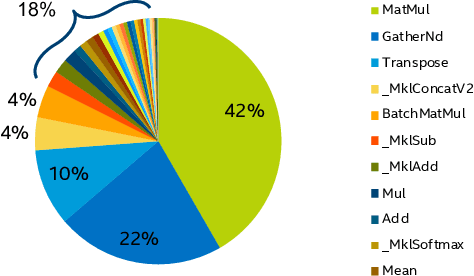
In this work, we quantize a trained Transformer machine language translation model leveraging INT8/VNNI instructions in the latest Intel$^\circledR$ Xeon$^\circledR$ Cascade Lake processors to improve inference performance while maintaining less than 0.5$\%$ drop in accuracy. To the best of our knowledge, this is the first attempt in the industry to quantize the Transformer model. This has high impact as it clearly demonstrates the various complexities of quantizing the language translation model. We present novel quantization techniques directly in TensorFlow to opportunistically replace 32-bit floating point (FP32) computations with 8-bit integers (INT8) and transform the FP32 computational graph. We also present a bin-packing parallel batching technique to maximize CPU utilization. Overall, our optimizations with INT8/VNNI deliver 1.5X improvement over the best FP32 performance. Furthermore, it reveals the opportunities and challenges to boost performance of quantized deep learning inference and establishes best practices to run inference with high efficiency on Intel CPUs.