 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Adversarial Perturbations for Deep Reinforcement Learning via Vector Quantization
Oct 04, 2024



Recent studies reveal that well-performing reinforcement learning (RL) agents in training often lack resilience against adversarial perturbations during deployment. This highlights the importance of building a robust agent before deploying it in the real world. Most prior works focus on developing robust training-based procedures to tackle this problem, including enhancing the robustness of the deep neural network component itself or adversarially training the agent on strong attacks. In this work, we instead study an input transformation-based defense for RL. Specifically, we propose using a variant of vector quantization (VQ) as a transformation for input observations, which is then used to reduce the space of adversarial attacks during testing, resulting in the transformed observations being less affected by attacks. Our method is computationally efficient and seamlessly integrates with adversarial training, further enhancing the robustness of RL agents against adversarial attacks. Through extensive experiments in multiple environments, we demonstrate that using VQ as the input transformation effectively defends against adversarial attacks on the agent's observations.
Predictive Coding for Decision Transformer
Oct 04, 2024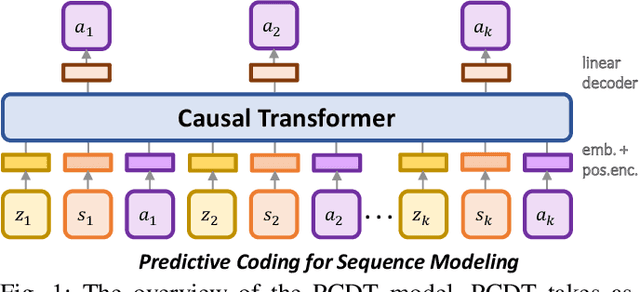
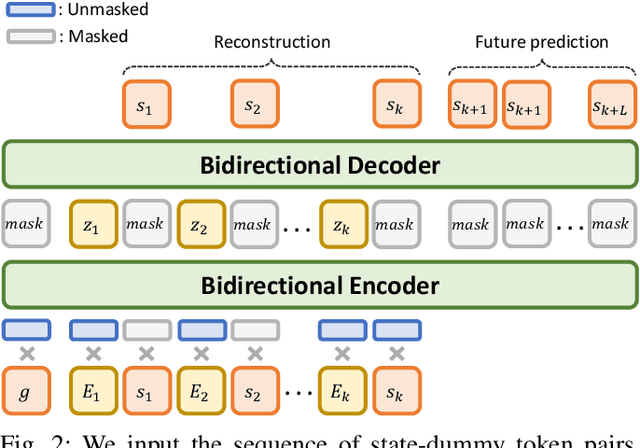
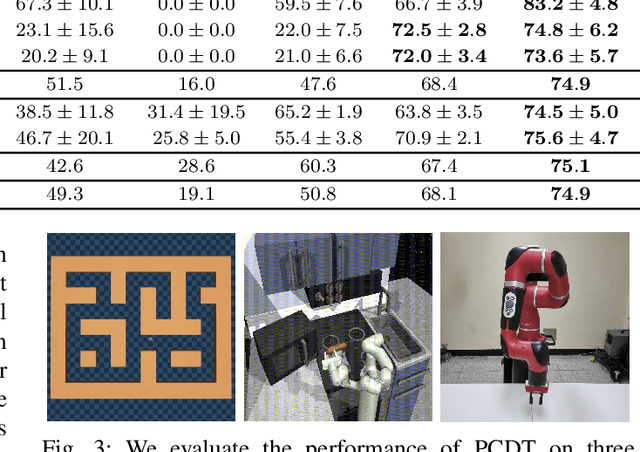
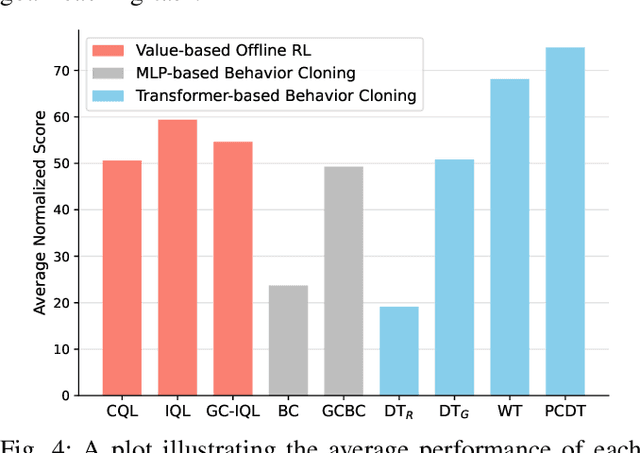
Recent work in offline reinforcement learning (RL) has demonstrated the effectiveness of formulating decision-making as return-conditioned supervised learning. Notably, the decision transformer (DT) architecture has shown promise across various domains. However, despite its initial success, DTs have underperformed on several challenging datasets in goal-conditioned RL. This limitation stems from the inefficiency of return conditioning for guiding policy learning, particularly in unstructured and suboptimal datasets, resulting in DTs failing to effectively learn temporal compositionality. Moreover, this problem might be further exacerbated in long-horizon sparse-reward tasks. To address this challenge, we propose the Predictive Coding for Decision Transformer (PCDT) framework, which leverages generalized future conditioning to enhance DT methods. PCDT utilizes an architecture that extends the DT framework, conditioned on predictive codings, enabling decision-making based on both past and future factors, thereby improving generalization. Through extensive experiments on eight datasets from the AntMaze and FrankaKitchen environments, our proposed method achieves performance on par with or surpassing existing popular value-based and transformer-based methods in offline goal-conditioned RL. Furthermore, we also evaluate our method on a goal-reaching task with a physical robot.
On the Perturbed States for Transformed Input-robust Reinforcement Learning
Aug 02, 2024Reinforcement Learning (RL) agents demonstrating proficiency in a training environment exhibit vulnerability to adversarial perturbations in input observations during deployment. This underscores the importance of building a robust agent before its real-world deployment. To alleviate the challenging point, prior works focus on developing robust training-based procedures, encompassing efforts to fortify the deep neural network component's robustness or subject the agent to adversarial training against potent attacks. In this work, we propose a novel method referred to as Transformed Input-robust RL (TIRL), which explores another avenue to mitigate the impact of adversaries by employing input transformation-based defenses. Specifically, we introduce two principles for applying transformation-based defenses in learning robust RL agents: (1) autoencoder-styled denoising to reconstruct the original state and (2) bounded transformations (bit-depth reduction and vector quantization (VQ)) to achieve close transformed inputs. The transformations are applied to the state before feeding it into the policy network. Extensive experiments on multiple MuJoCo environments demonstrate that input transformation-based defenses, i.e., VQ, defend against several adversaries in the state observations. The official code is available at https://github.com/tunglm2203/tirl
Towards Robust Policy: Enhancing Offline Reinforcement Learning with Adversarial Attacks and Defenses
May 18, 2024



Offline reinforcement learning (RL) addresses the challenge of expensive and high-risk data exploration inherent in RL by pre-training policies on vast amounts of offline data, enabling direct deployment or fine-tuning in real-world environments. However, this training paradigm can compromise policy robustness, leading to degraded performance in practical conditions due to observation perturbations or intentional attacks. While adversarial attacks and defenses have been extensively studied in deep learning, their application in offline RL is limited. This paper proposes a framework to enhance the robustness of offline RL models by leveraging advanced adversarial attacks and defenses. The framework attacks the actor and critic components by perturbing observations during training and using adversarial defenses as regularization to enhance the learned policy. Four attacks and two defenses are introduced and evaluated on the D4RL benchmark. The results show the vulnerability of both the actor and critic to attacks and the effectiveness of the defenses in improving policy robustness. This framework holds promise for enhancing the reliability of offline RL models in practical scenarios.
SoftGroup++: Scalable 3D Instance Segmentation with Octree Pyramid Grouping
Sep 17, 2022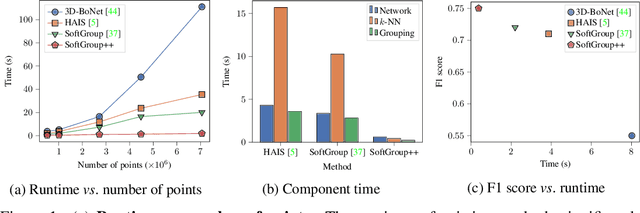
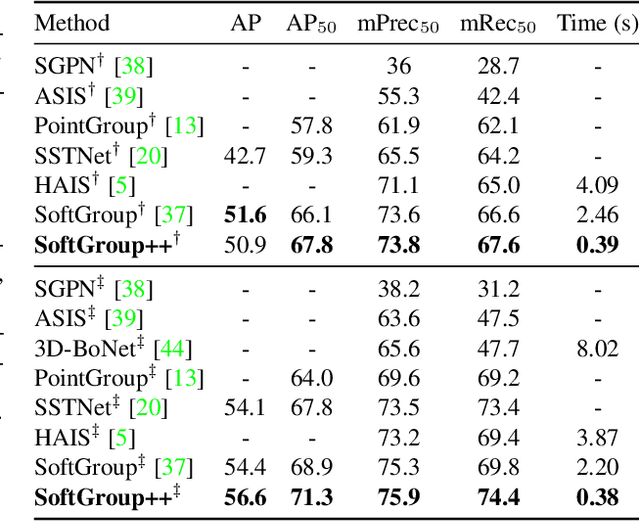
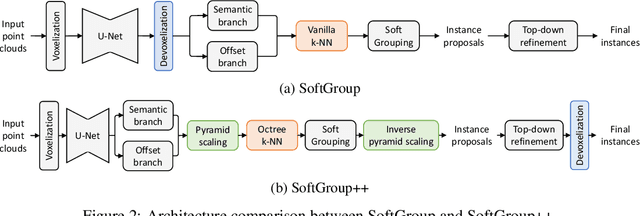

Existing state-of-the-art 3D point cloud instance segmentation methods rely on a grouping-based approach that groups points to obtain object instances. Despite improvement in producing accurate segmentation results, these methods lack scalability and commonly require dividing large input into multiple parts. To process a scene with millions of points, the existing fastest method SoftGroup \cite{vu2022softgroup} requires tens of seconds, which is under satisfaction. Our finding is that $k$-Nearest Neighbor ($k$-NN), which serves as the prerequisite of grouping, is a computational bottleneck. This bottleneck severely worsens the inference time in the scene with a large number of points. This paper proposes SoftGroup++ to address this computational bottleneck and further optimize the inference speed of the whole network. SoftGroup++ is built upon SoftGroup, which differs in three important aspects: (1) performs octree $k$-NN instead of vanilla $k$-NN to reduce time complexity from $\mathcal{O}(n^2)$ to $\mathcal{O}(n \log n)$, (2) performs pyramid scaling that adaptively downsamples backbone outputs to reduce search space for $k$-NN and grouping, and (3) performs late devoxelization that delays the conversion from voxels to points towards the end of the model such that intermediate components operate at a low computational cost. Extensive experiments on various indoor and outdoor datasets demonstrate the efficacy of the proposed SoftGroup++. Notably, SoftGroup++ processes large scenes of millions of points by a single forward without dividing the input into multiple parts, thus enriching contextual information. Especially, SoftGroup++ achieves 2.4 points AP$_{50}$ improvement while nearly $6\times$ faster than the existing fastest method on S3DIS dataset. The code and trained models will be made publicly available.
SoftGroup for 3D Instance Segmentation on Point Clouds
Mar 03, 2022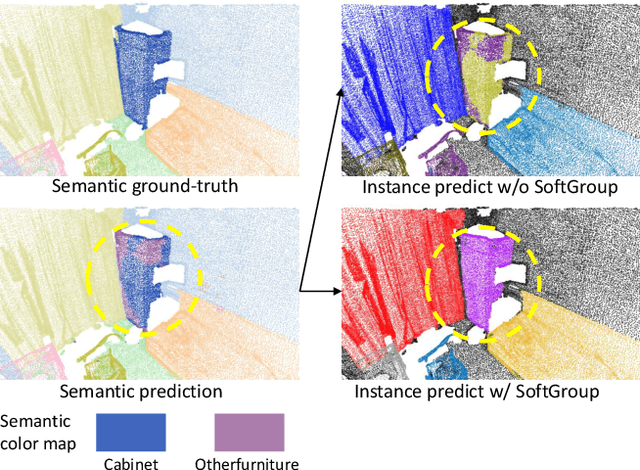
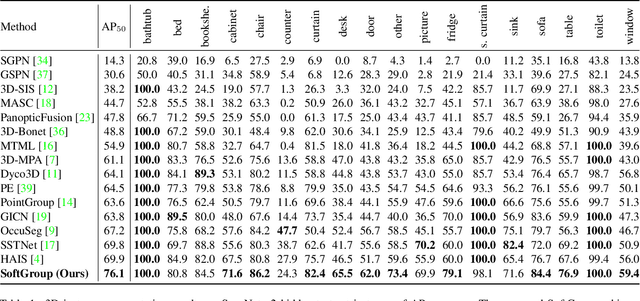
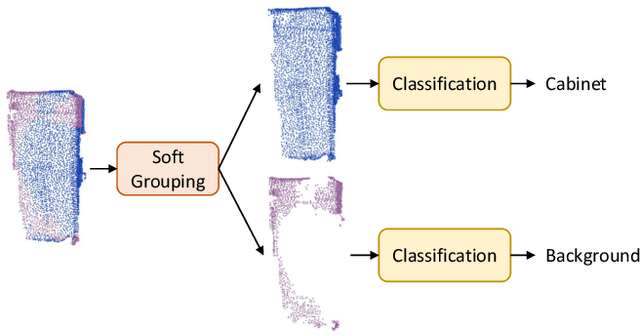
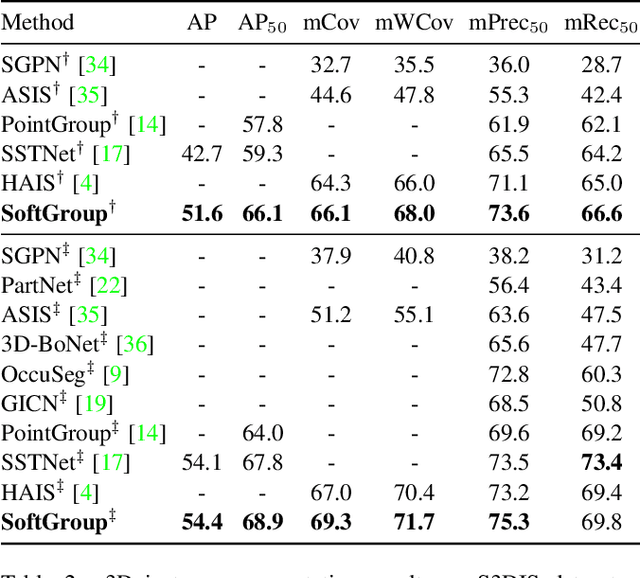
Existing state-of-the-art 3D instance segmentation methods perform semantic segmentation followed by grouping. The hard predictions are made when performing semantic segmentation such that each point is associated with a single class. However, the errors stemming from hard decision propagate into grouping that results in (1) low overlaps between the predicted instance with the ground truth and (2) substantial false positives. To address the aforementioned problems, this paper proposes a 3D instance segmentation method referred to as SoftGroup by performing bottom-up soft grouping followed by top-down refinement. SoftGroup allows each point to be associated with multiple classes to mitigate the problems stemming from semantic prediction errors and suppresses false positive instances by learning to categorize them as background. Experimental results on different datasets and multiple evaluation metrics demonstrate the efficacy of SoftGroup. Its performance surpasses the strongest prior method by a significant margin of +6.2% on the ScanNet v2 hidden test set and +6.8% on S3DIS Area 5 in terms of AP_50. SoftGroup is also fast, running at 345ms per scan with a single Titan X on ScanNet v2 dataset. The source code and trained models for both datasets are available at \url{https://github.com/thangvubk/SoftGroup.git}.
Hindsight Goal Ranking on Replay Buffer for Sparse Reward Environment
Oct 28, 2021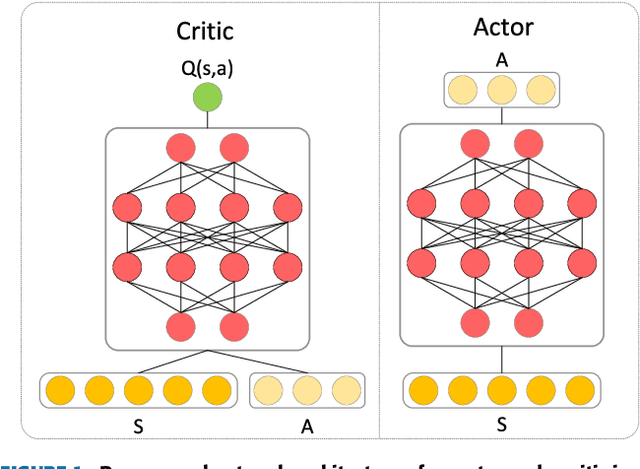
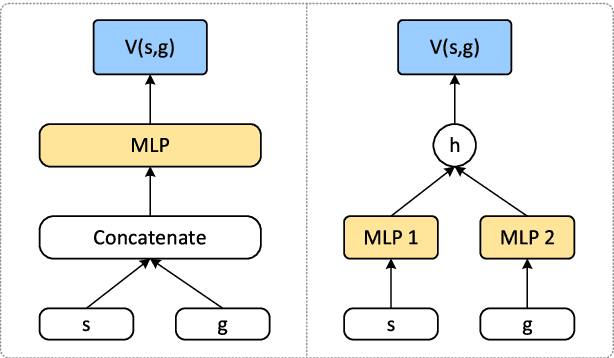
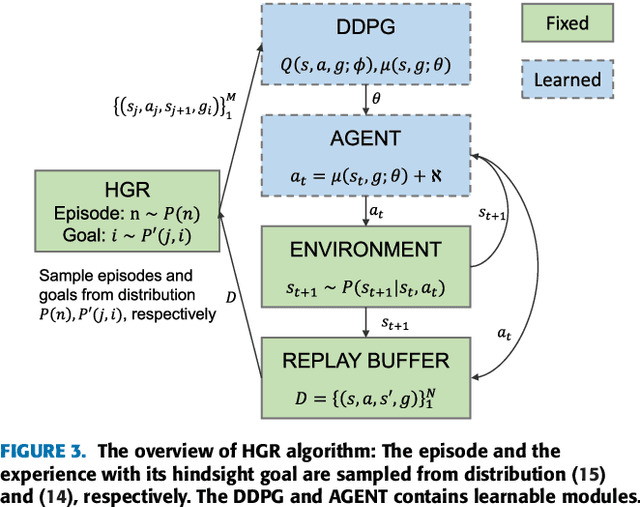
This paper proposes a method for prioritizing the replay experience referred to as Hindsight Goal Ranking (HGR) in overcoming the limitation of Hindsight Experience Replay (HER) that generates hindsight goals based on uniform sampling. HGR samples with higher probability on the states visited in an episode with larger temporal difference (TD) error, which is considered as a proxy measure of the amount which the RL agent can learn from an experience. The actual sampling for large TD error is performed in two steps: first, an episode is sampled from the relay buffer according to the average TD error of its experiences, and then, for the sampled episode, the hindsight goal leading to larger TD error is sampled with higher probability from future visited states. The proposed method combined with Deep Deterministic Policy Gradient (DDPG), an off-policy model-free actor-critic algorithm, accelerates learning significantly faster than that without any prioritization on four challenging simulated robotic manipulation tasks. The empirical results show that HGR uses samples more efficiently than previous methods across all tasks.
Sample-efficient Reinforcement Learning Representation Learning with Curiosity Contrastive Forward Dynamics Model
Mar 15, 2021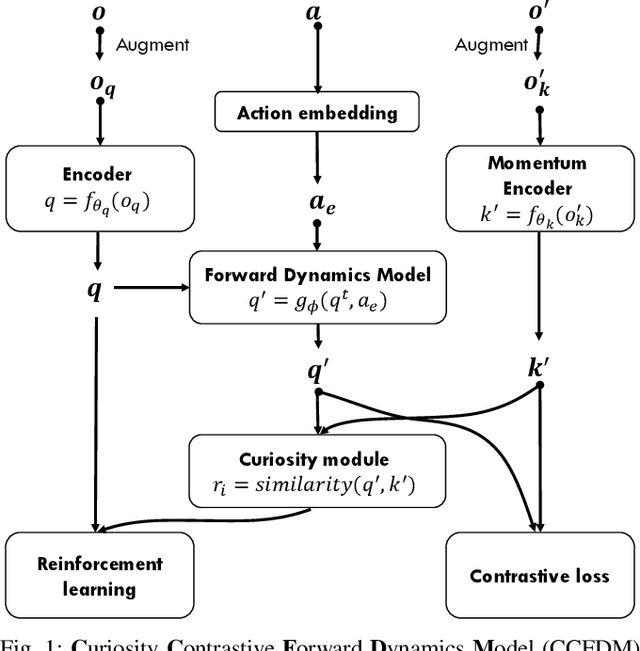
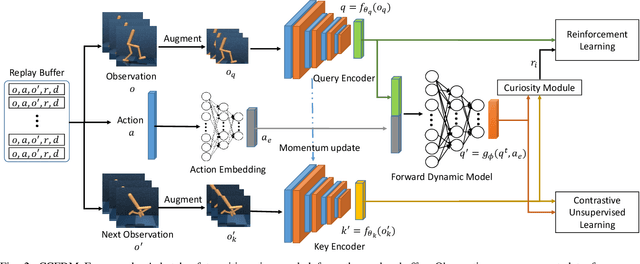
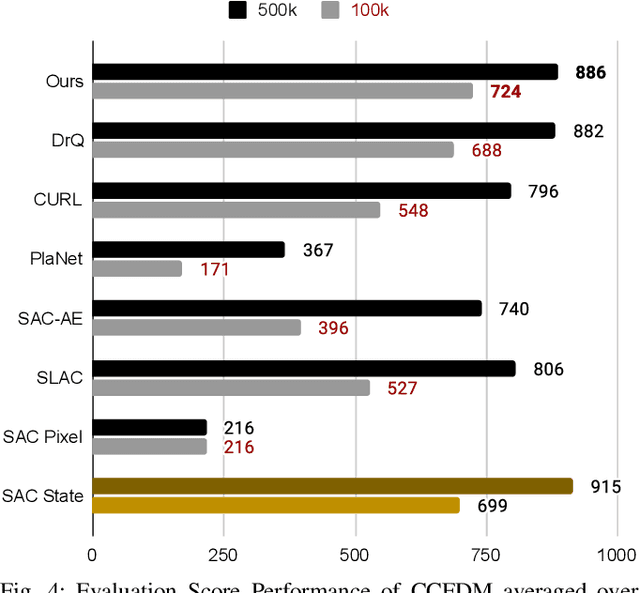
Developing an agent in reinforcement learning (RL) that is capable of performing complex control tasks directly from high-dimensional observation such as raw pixels is yet a challenge as efforts are made towards improving sample efficiency and generalization. This paper considers a learning framework for Curiosity Contrastive Forward Dynamics Model (CCFDM) in achieving a more sample-efficient RL based directly on raw pixels. CCFDM incorporates a forward dynamics model (FDM) and performs contrastive learning to train its deep convolutional neural network-based image encoder (IE) to extract conducive spatial and temporal information for achieving a more sample efficiency for RL. In addition, during training, CCFDM provides intrinsic rewards, produced based on FDM prediction error, encourages the curiosity of the RL agent to improve exploration. The diverge and less-repetitive observations provide by both our exploration strategy and data augmentation available in contrastive learning improve not only the sample efficiency but also the generalization. Performance of existing model-free RL methods such as Soft Actor-Critic built on top of CCFDM outperforms prior state-of-the-art pixel-based RL methods on the DeepMind Control Suite benchmark.