 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixtures of SubExperts for Large Language Continual Learning
Nov 09, 2025Adapting Large Language Models (LLMs) to a continuous stream of tasks is a critical yet challenging endeavor. While Parameter-Efficient Fine-Tuning (PEFT) methods have become a standard for this, they face a fundamental dilemma in continual learning. Reusing a single set of PEFT parameters for new tasks often leads to catastrophic forgetting of prior knowledge. Conversely, allocating distinct parameters for each task prevents forgetting but results in a linear growth of the model's size and fails to facilitate knowledge transfer between related tasks. To overcome these limitations, we propose a novel adaptive PEFT method referred to as \textit{Mixtures of SubExperts (MoSEs)}, a novel continual learning framework designed for minimal forgetting and efficient scalability. MoSEs integrate a sparse Mixture of SubExperts into the transformer layers, governed by a task-specific routing mechanism. This architecture allows the model to isolate and protect knowledge within dedicated SubExperts, thereby minimizing parameter interference and catastrophic forgetting. Crucially, the router can adaptively select and combine previously learned sparse parameters for new tasks, enabling effective knowledge transfer while ensuring that the model's capacity grows sublinearly. We evaluate MoSEs on the comprehensive TRACE benchmark datasets. Our experiments demonstrate that MoSEs significantly outperform conventional continual learning approaches in both knowledge retention and scalability to new tasks, achieving state-of-the-art performance with substantial memory and computational savings.
Soft-TransFormers for Continual Learning
Nov 25, 2024Inspired by Well-initialized Lottery Ticket Hypothesis (WLTH), which provides suboptimal fine-tuning solutions, we propose a novel fully fine-tuned continual learning (CL) method referred to as Soft-TransFormers (Soft-TF). Soft-TF sequentially learns and selects an optimal soft-network or subnetwork for each task. During sequential training in CL, Soft-TF jointly optimizes the weights of sparse layers to obtain task-adaptive soft (real-valued) networks or subnetworks (binary masks), while keeping the well-pre-trained layer parameters frozen. In inference, the identified task-adaptive network of Soft-TF masks the parameters of the pre-trained network, mapping to an optimal solution for each task and minimizing Catastrophic Forgetting (CF) - the soft-masking preserves the knowledge of the pre-trained network. Extensive experiments on Vision Transformer (ViT) and CLIP demonstrate the effectiveness of Soft-TF, achieving state-of-the-art performance across various CL scenarios, including Class-Incremental Learning (CIL) and Task-Incremental Learning (TIL), supported by convergence theory.
On the Perturbed States for Transformed Input-robust Reinforcement Learning
Aug 02, 2024Reinforcement Learning (RL) agents demonstrating proficiency in a training environment exhibit vulnerability to adversarial perturbations in input observations during deployment. This underscores the importance of building a robust agent before its real-world deployment. To alleviate the challenging point, prior works focus on developing robust training-based procedures, encompassing efforts to fortify the deep neural network component's robustness or subject the agent to adversarial training against potent attacks. In this work, we propose a novel method referred to as Transformed Input-robust RL (TIRL), which explores another avenue to mitigate the impact of adversaries by employing input transformation-based defenses. Specifically, we introduce two principles for applying transformation-based defenses in learning robust RL agents: (1) autoencoder-styled denoising to reconstruct the original state and (2) bounded transformations (bit-depth reduction and vector quantization (VQ)) to achieve close transformed inputs. The transformations are applied to the state before feeding it into the policy network. Extensive experiments on multiple MuJoCo environments demonstrate that input transformation-based defenses, i.e., VQ, defend against several adversaries in the state observations. The official code is available at https://github.com/tunglm2203/tirl
Continual Learning: Forget-free Winning Subnetworks for Video Representations
Jan 04, 2024



Inspired by the Lottery Ticket Hypothesis (LTH), which highlights the existence of efficient subnetworks within larger, dense networks, a high-performing Winning Subnetwork (WSN) in terms of task performance under appropriate sparsity conditions is considered for various continual learning tasks. It leverages pre-existing weights from dense networks to achieve efficient learning in Task Incremental Learning (TIL) scenarios. In Few-Shot Class Incremental Learning (FSCIL), a variation of WSN referred to as the Soft subnetwork (SoftNet) is designed to prevent overfitting when the data samples are scarce. Furthermore, the sparse reuse of WSN weights is considered for Video Incremental Learning (VIL). The use of Fourier Subneural Operator (FSO) within WSN is considered. It enables compact encoding of videos and identifies reusable subnetworks across varying bandwidths. We have integrated FSO into different architectural frameworks for continual learning, including VIL, TIL, and FSCIL. Our comprehensive experiments demonstrate FSO's effectiveness, significantly improving task performance at various convolutional representational levels. Specifically, FSO enhances higher-layer performance in TIL and FSCIL and lower-layer performance in VIL
Progressive Neural Representation for Sequential Video Compilation
Jun 20, 2023



Neural Implicit Representations (NIR) have gained significant attention recently due to their ability to represent complex and high-dimensional data. Unlike explicit representations, which require storing and manipulating individual data points, implicit representations capture information through a learned mapping function without explicitly representing the data points themselves. They often prune or quantize neural networks after training to accelerate encoding/decoding speed, yet we find that conventional methods fail to transfer learned representations to new videos. This work studies the continuous expansion of implicit video representations as videos arrive sequentially over time, where the model can only access the videos from the current session. We propose a novel neural video representation, Progressive Neural Representation (PNR), that finds an adaptive substructure from the supernet for a given video based on Lottery Ticket Hypothesis. At each training session, our PNR transfers the learned knowledge of the previously obtained subnetworks to learn the representation of the current video while keeping the past subnetwork weights intact. Therefore it can almost perfectly preserve the decoding ability (i.e., catastrophic forgetting) of the NIR on previous videos. We demonstrate the effectiveness of our proposed PNR on the neural sequential video representation compilation on the novel UVG8/17 video sequence benchmarks.
Forget-free Continual Learning with Soft-Winning SubNetworks
Mar 27, 2023



Inspired by Regularized Lottery Ticket Hypothesis (RLTH), which states that competitive smooth (non-binary) subnetworks exist within a dense network in continual learning tasks, we investigate two proposed architecture-based continual learning methods which sequentially learn and select adaptive binary- (WSN) and non-binary Soft-Subnetworks (SoftNet) for each task. WSN and SoftNet jointly learn the regularized model weights and task-adaptive non-binary masks of subnetworks associated with each task whilst attempting to select a small set of weights to be activated (winning ticket) by reusing weights of the prior subnetworks. Our proposed WSN and SoftNet are inherently immune to catastrophic forgetting as each selected subnetwork model does not infringe upon other subnetworks in Task Incremental Learning (TIL). In TIL, binary masks spawned per winning ticket are encoded into one N-bit binary digit mask, then compressed using Huffman coding for a sub-linear increase in network capacity to the number of tasks. Surprisingly, in the inference step, SoftNet generated by injecting small noises to the backgrounds of acquired WSN (holding the foregrounds of WSN) provides excellent forward transfer power for future tasks in TIL. SoftNet shows its effectiveness over WSN in regularizing parameters to tackle the overfitting, to a few examples in Few-shot Class Incremental Learning (FSCIL).
Maximum margin learning of t-SPNs for cell classification with filtered input
Mar 21, 2023An algorithm based on a deep probabilistic architecture referred to as a tree-structured sum-product network (t-SPN) is considered for cell classification. The t-SPN is constructed such that the unnormalized probability is represented as conditional probabilities of a subset of most similar cell classes. The constructed t-SPN architecture is learned by maximizing the margin, which is the difference in the conditional probability between the true and the most competitive false label. To enhance the generalization ability of the architecture, L2-regularization (REG) is considered along with the maximum margin (MM) criterion in the learning process. To highlight cell features, this paper investigates the effectiveness of two generic high-pass filters: ideal high-pass filtering and the Laplacian of Gaussian (LOG) filtering. On both HEp-2 and Feulgen benchmark datasets, the t-SPN architecture learned based on the max-margin criterion with regularization produced the highest accuracy rate compared to other state-of-the-art algorithms that include convolutional neural network (CNN) based algorithms. The ideal high-pass filter was more effective on the HEp-2 dataset, which is based on immunofluorescence staining, while the LOG was more effective on the Feulgen dataset, which is based on Feulgen staining.
Skew Class-balanced Re-weighting for Unbiased Scene Graph Generation
Jan 01, 2023



An unbiased scene graph generation (SGG) algorithm referred to as Skew Class-balanced Re-weighting (SCR) is proposed for considering the unbiased predicate prediction caused by the long-tailed distribution. The prior works focus mainly on alleviating the deteriorating performances of the minority predicate predictions, showing drastic dropping recall scores, i.e., losing the majority predicate performances. It has not yet correctly analyzed the trade-off between majority and minority predicate performances in the limited SGG datasets. In this paper, to alleviate the issue, the Skew Class-balanced Re-weighting (SCR) loss function is considered for the unbiased SGG models. Leveraged by the skewness of biased predicate predictions, the SCR estimates the target predicate weight coefficient and then re-weights more to the biased predicates for better trading-off between the majority predicates and the minority ones. Extensive experiments conducted on the standard Visual Genome dataset and Open Image V4 \& V6 show the performances and generality of the SCR with the traditional SGG models.
On the Soft-Subnetwork for Few-shot Class Incremental Learning
Sep 15, 2022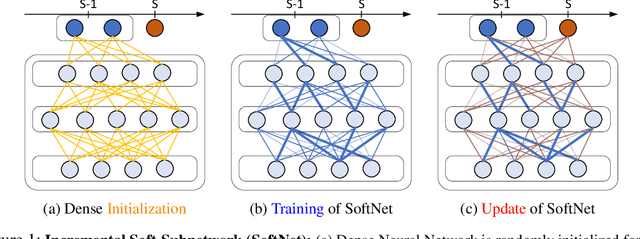
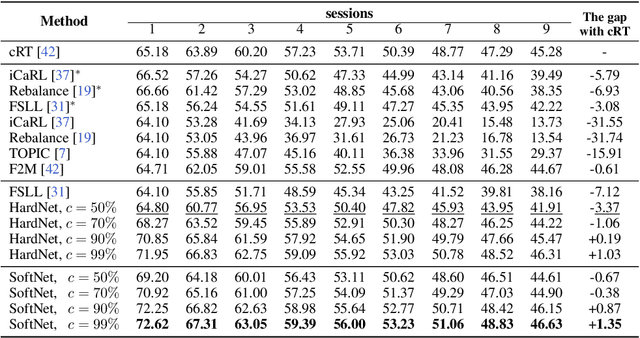
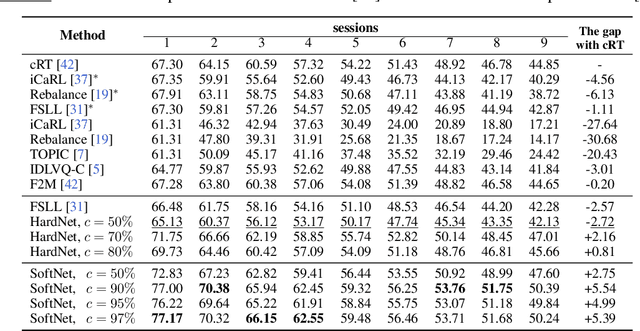
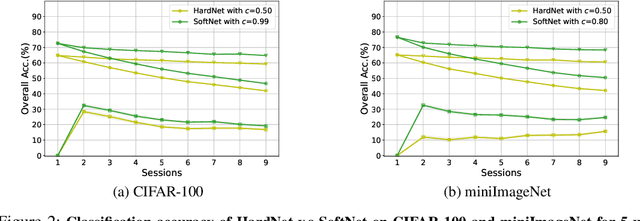
Inspired by Regularized Lottery Ticket Hypothesis (RLTH), which hypothesizes that there exist smooth (non-binary) subnetworks within a dense network that achieve the competitive performance of the dense network, we propose a few-shot class incremental learning (FSCIL) method referred to as \emph{Soft-SubNetworks (SoftNet)}. Our objective is to learn a sequence of sessions incrementally, where each session only includes a few training instances per class while preserving the knowledge of the previously learned ones. SoftNet jointly learns the model weights and adaptive non-binary soft masks at a base training session in which each mask consists of the major and minor subnetwork; the former aims to minimize catastrophic forgetting during training, and the latter aims to avoid overfitting to a few samples in each new training session. We provide comprehensive empirical validations demonstrating that our SoftNet effectively tackles the few-shot incremental learning problem by surpassing the performance of state-of-the-art baselines over benchmark datasets.
Learning Imbalanced Datasets with Maximum Margin Loss
Jun 11, 2022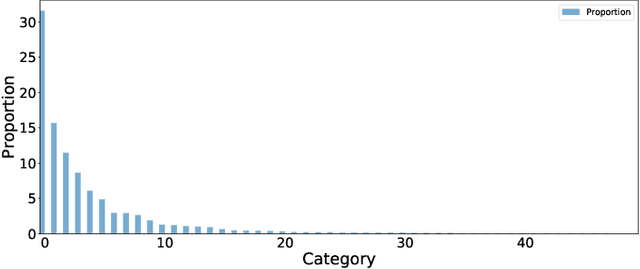
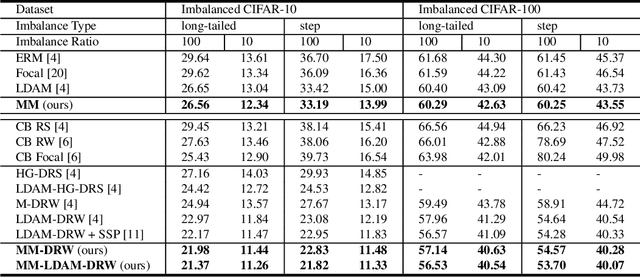
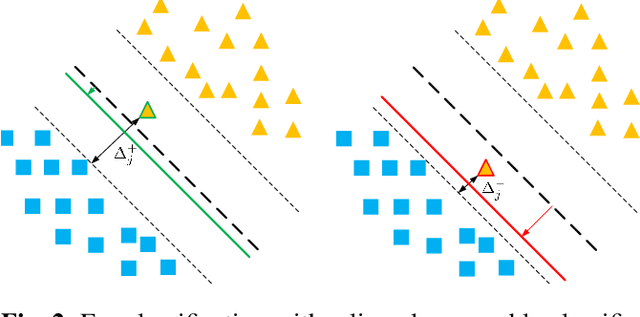
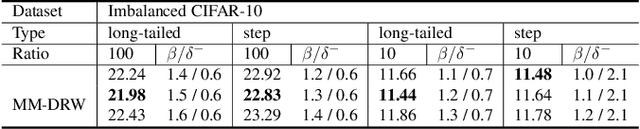
A learning algorithm referred to as Maximum Margin (MM) is proposed for considering the class-imbalance data learning issue: the trained model tends to predict the majority of classes rather than the minority ones. That is, underfitting for minority classes seems to be one of the challenges of generalization. For a good generalization of the minority classes, we design a new Maximum Margin (MM) loss function, motivated by minimizing a margin-based generalization bound through the shifting decision bound. The theoretically-principled label-distribution-aware margin (LDAM) loss was successfully applied with prior strategies such as re-weighting or re-sampling along with the effective training schedule. However, they did not investigate the maximum margin loss function yet. In this study, we investigate the performances of two types of hard maximum margin-based decision boundary shift with LDAM's training schedule on artificially imbalanced CIFAR-10/100 for fair comparisons and effectiveness.