 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Coding for Decision Transformer
Paper and Code
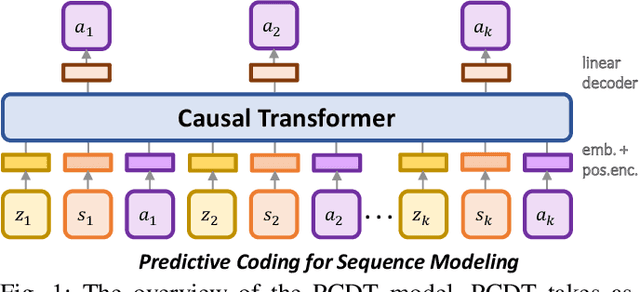
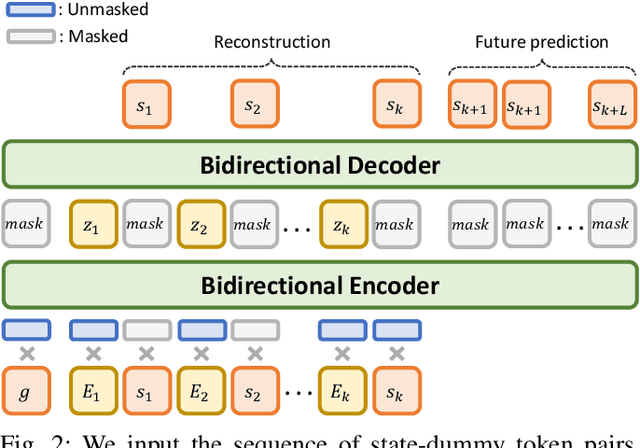
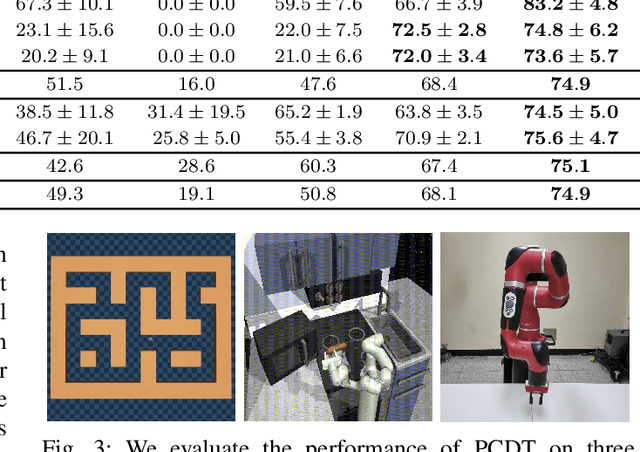
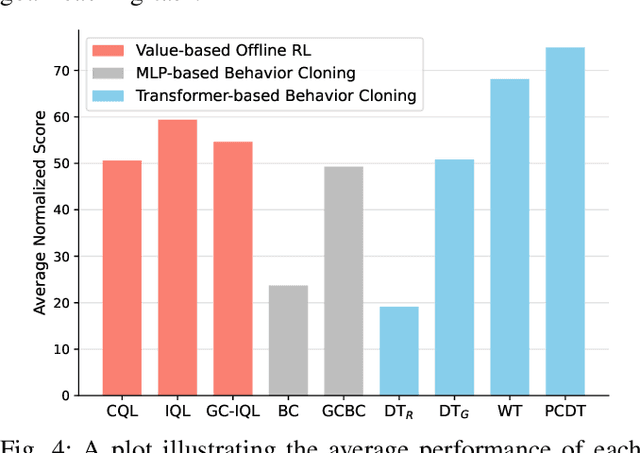
Recent work in offline reinforcement learning (RL) has demonstrated the effectiveness of formulating decision-making as return-conditioned supervised learning. Notably, the decision transformer (DT) architecture has shown promise across various domains. However, despite its initial success, DTs have underperformed on several challenging datasets in goal-conditioned RL. This limitation stems from the inefficiency of return conditioning for guiding policy learning, particularly in unstructured and suboptimal datasets, resulting in DTs failing to effectively learn temporal compositionality. Moreover, this problem might be further exacerbated in long-horizon sparse-reward tasks. To address this challenge, we propose the Predictive Coding for Decision Transformer (PCDT) framework, which leverages generalized future conditioning to enhance DT methods. PCDT utilizes an architecture that extends the DT framework, conditioned on predictive codings, enabling decision-making based on both past and future factors, thereby improving generalization. Through extensive experiments on eight datasets from the AntMaze and FrankaKitchen environments, our proposed method achieves performance on par with or surpassing existing popular value-based and transformer-based methods in offline goal-conditioned RL. Furthermore, we also evaluate our method on a goal-reaching task with a physical robot.