 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-efficient Reinforcement Learning Representation Learning with Curiosity Contrastive Forward Dynamics Model
Paper and Code
Mar 15, 2021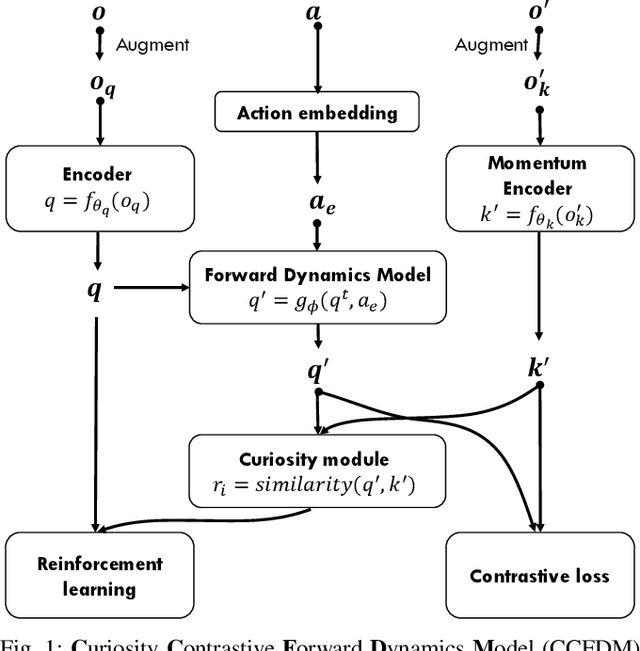
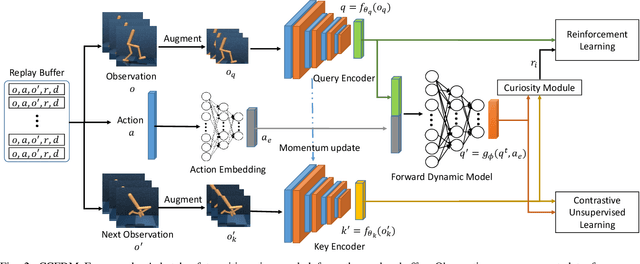
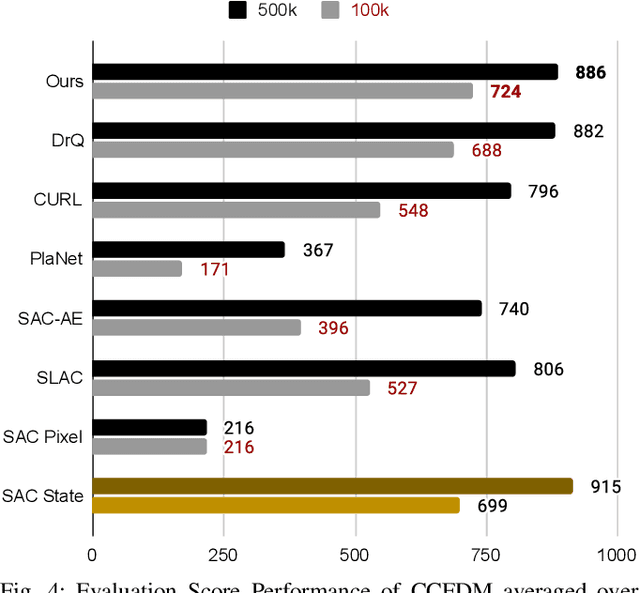
Developing an agent in reinforcement learning (RL) that is capable of performing complex control tasks directly from high-dimensional observation such as raw pixels is yet a challenge as efforts are made towards improving sample efficiency and generalization. This paper considers a learning framework for Curiosity Contrastive Forward Dynamics Model (CCFDM) in achieving a more sample-efficient RL based directly on raw pixels. CCFDM incorporates a forward dynamics model (FDM) and performs contrastive learning to train its deep convolutional neural network-based image encoder (IE) to extract conducive spatial and temporal information for achieving a more sample efficiency for RL. In addition, during training, CCFDM provides intrinsic rewards, produced based on FDM prediction error, encourages the curiosity of the RL agent to improve exploration. The diverge and less-repetitive observations provide by both our exploration strategy and data augmentation available in contrastive learning improve not only the sample efficiency but also the generalization. Performance of existing model-free RL methods such as Soft Actor-Critic built on top of CCFDM outperforms prior state-of-the-art pixel-based RL methods on the DeepMind Control Suite benchmark.