 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioBridge: Unified Bio-Embedding with Bridging Modality in Code-Switched EMR
Paper and Code


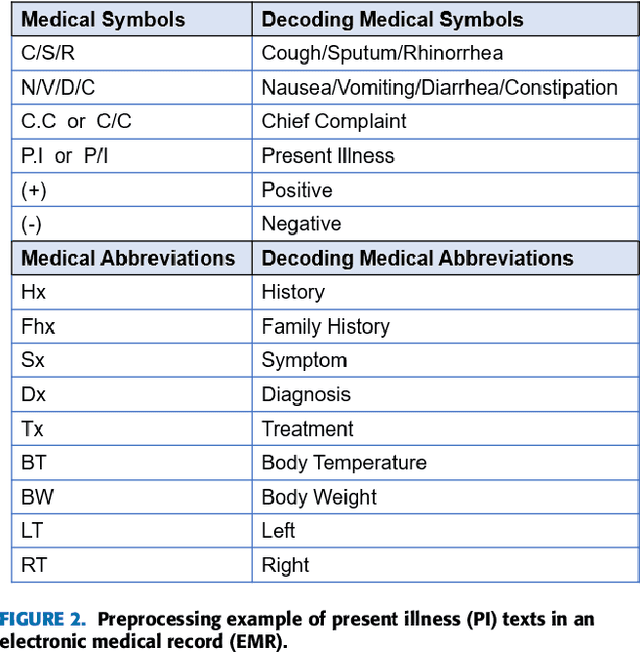
Pediatric Emergency Department (PED) overcrowding presents a significant global challenge, prompting the need for efficient solutions. This paper introduces the BioBridge framework, a novel approach that applies Natural Language Processing (NLP) to Electronic Medical Records (EMRs) in written free-text form to enhance decision-making in PED. In non-English speaking countries, such as South Korea, EMR data is often written in a Code-Switching (CS) format that mixes the native language with English, with most code-switched English words having clinical significance. The BioBridge framework consists of two core modules: "bridging modality in context" and "unified bio-embedding." The "bridging modality in context" module improves the contextual understanding of bilingual and code-switched EMRs. In the "unified bio-embedding" module, the knowledge of the model trained in the medical domain is injected into the encoder-based model to bridge the gap between the medical and general domains. Experimental results demonstrate that the proposed BioBridge significantly performance traditional machine learning and pre-trained encoder-based models on several metrics, including F1 score, area under the receiver operating characteristic curve (AUROC), area under the precision-recall curve (AUPRC), and Brier score. Specifically, BioBridge-XLM achieved enhancements of 0.85% in F1 score, 0.75% in AUROC, and 0.76% in AUPRC, along with a notable 3.04% decrease in the Brier score, demonstrating marked improvements in accuracy, reliability, and prediction calibration over the baseline XLM model. The source code will be made publicly available.