 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergy-CLIP: Extending CLIP with Multi-modal Integration for Robust Representation Learning
Apr 30, 2025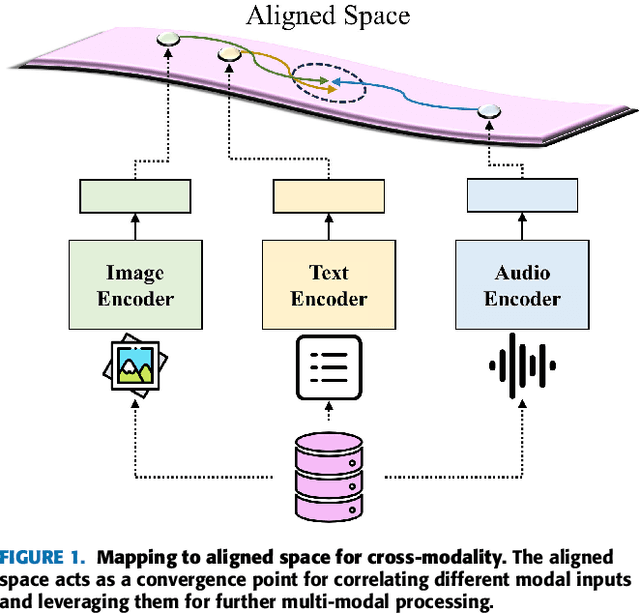
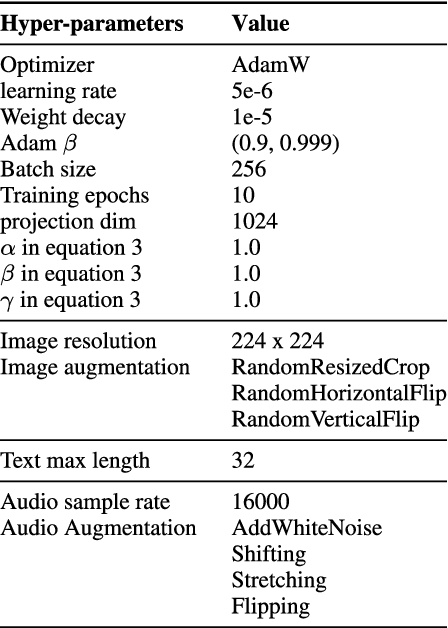

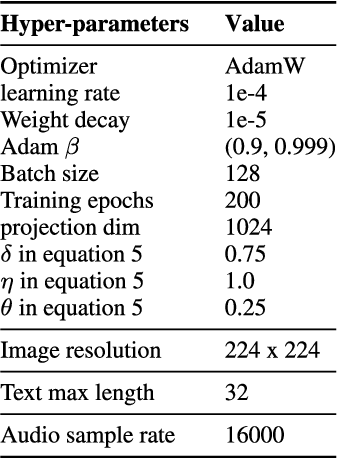
Multi-modal representation learning has become a pivotal area in artificial intelligence, enabling the integration of diverse modalities such as vision, text, and audio to solve complex problems. However, existing approaches predominantly focus on bimodal interactions, such as image-text pairs, which limits their ability to fully exploit the richness of multi-modal data. Furthermore, the integration of modalities in equal-scale environments remains underexplored due to the challenges of constructing large-scale, balanced datasets. In this study, we propose Synergy-CLIP, a novel framework that extends the contrastive language-image pre-training (CLIP) architecture to enhance multi-modal representation learning by integrating visual, textual, and audio modalities. Unlike existing methods that focus on adapting individual modalities to vanilla-CLIP, Synergy-CLIP aligns and captures latent information across three modalities equally. To address the high cost of constructing large-scale multi-modal datasets, we introduce VGG-sound+, a triple-modal dataset designed to provide equal-scale representation of visual, textual, and audio data. Synergy-CLIP is validated on various downstream tasks, including zero-shot classification, where it outperforms existing baselines. Additionally, we introduce a missing modality reconstruction task, demonstrating Synergy-CLIP's ability to extract synergy among modalities in realistic application scenarios. These contributions provide a robust foundation for advancing multi-modal representation learning and exploring new research directions.
BioBridge: Unified Bio-Embedding with Bridging Modality in Code-Switched EMR
Dec 16, 2024

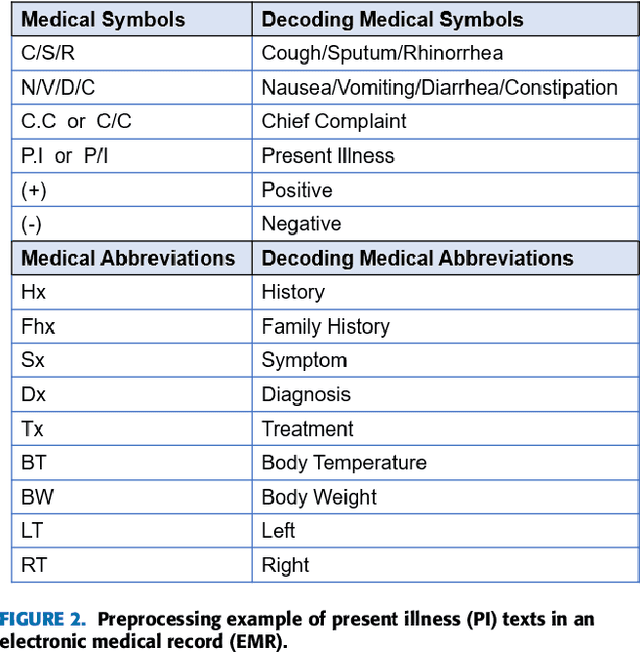
Pediatric Emergency Department (PED) overcrowding presents a significant global challenge, prompting the need for efficient solutions. This paper introduces the BioBridge framework, a novel approach that applies Natural Language Processing (NLP) to Electronic Medical Records (EMRs) in written free-text form to enhance decision-making in PED. In non-English speaking countries, such as South Korea, EMR data is often written in a Code-Switching (CS) format that mixes the native language with English, with most code-switched English words having clinical significance. The BioBridge framework consists of two core modules: "bridging modality in context" and "unified bio-embedding." The "bridging modality in context" module improves the contextual understanding of bilingual and code-switched EMRs. In the "unified bio-embedding" module, the knowledge of the model trained in the medical domain is injected into the encoder-based model to bridge the gap between the medical and general domains. Experimental results demonstrate that the proposed BioBridge significantly performance traditional machine learning and pre-trained encoder-based models on several metrics, including F1 score, area under the receiver operating characteristic curve (AUROC), area under the precision-recall curve (AUPRC), and Brier score. Specifically, BioBridge-XLM achieved enhancements of 0.85% in F1 score, 0.75% in AUROC, and 0.76% in AUPRC, along with a notable 3.04% decrease in the Brier score, demonstrating marked improvements in accuracy, reliability, and prediction calibration over the baseline XLM model. The source code will be made publicly available.
* Accepted at IEEE Access 2024
ConCSE: Unified Contrastive Learning and Augmentation for Code-Switched Embeddings
Aug 28, 2024This paper examines the Code-Switching (CS) phenomenon where two languages intertwine within a single utterance. There exists a noticeable need for research on the CS between English and Korean. We highlight that the current Equivalence Constraint (EC) theory for CS in other languages may only partially capture English-Korean CS complexities due to the intrinsic grammatical differences between the languages. We introduce a novel Koglish dataset tailored for English-Korean CS scenarios to mitigate such challenges. First, we constructed the Koglish-GLUE dataset to demonstrate the importance and need for CS datasets in various tasks. We found the differential outcomes of various foundation multilingual language models when trained on a monolingual versus a CS dataset. Motivated by this, we hypothesized that SimCSE, which has shown strengths in monolingual sentence embedding, would have limitations in CS scenarios. We construct a novel Koglish-NLI (Natural Language Inference) dataset using a CS augmentation-based approach to verify this. From this CS-augmented dataset Koglish-NLI, we propose a unified contrastive learning and augmentation method for code-switched embeddings, ConCSE, highlighting the semantics of CS sentences. Experimental results validate the proposed ConCSE with an average performance enhancement of 1.77\% on the Koglish-STS(Semantic Textual Similarity) tasks.